【AWS】ArmベースのEC2インスタンスt4gとt3のスペック・料金比較
昨年9月からArmベースのt4gインスタンスが利用可能になりました。同じく汎用インスタンスであるt3インスタンスはIntelベースです。
昨年はAppleのM1チップや、WindowsのCPU自社設計など大きな話題がありましたが、いずれもArmベースです。Armはすでにスマホ用CPUでシェアを握っていますが、PC向けでも勢力を拡大しつつありますね。
料金とスペック
Intelベースのt3, AMDベースのt3a, Armベースのt4の性能面を比較していきます。
お試しでよく使われる「micro」で比較します。価格は東京リージョンのものです。
| インスタンスサイズ | 価格(東京リージョン) | vCPU | メモリ (GiB) | ベースラインパフォーマンス/vCPU | CPU クレジット取得/時間 | ネットワークバースト幅 (Gbps) | EBS バースト幅 (Mbps) |
|---|---|---|---|---|---|---|---|
| t4g.micro | 0.0108USD/時間 | 2 | 1 | 10% | 12 | 最大 5 | 最大 2,085 |
| t3.micro | 0.0136USD/時間 | 2 | 1 | 10% | 12 | 最大 5 | 最大 2,085 |
| t3a.micro | 0.0122USD/時間 | 2 | 1 | 10% | 12 | 最大 5 | 最大 2,085 |
スペックは同じで価格が異なります。t4gとt3を比較すると、t4gの方が20%安いです。
micro以外も確認しましたが、microと同様にスペックは同じで20%安いという結果でした。micro以外の性能を見たい方は公式を参照してください。
Amazon EC2 T4g Instances - Amazon Web Services
t4g以外のArmベースインスタンス
t4g以外にもArmベースのインスタンスは存在します。a1, m6g, c6g, r6gです。
a1はArmベースのインスタンスの中では古い部類だったと記憶しています。なので、t4g, m6g, c6g, r6gで使い分けるのがよいと思います。
- お試し用途、バーストが必要ならt4g
- 汎用でバースト不要ならm6g
- 高性能CPUが必要ならc6g
- メモリ容量が必要ならr6g
t4.microは2021年末まで無料トライアル中
t4.microは750時間/月まで無料で利用できます。t3からの移行を試すには非常にありがたいです。
Amazon EC2 T4g Instances - Amazon Web Services
注意点
t3を始めとしたIntel系(x86)のインスタンスと、ライブラリのインストール方法が異なる場合があります。ソースからビルドしてインストールが必要な場合もあります。
numpy, pandas, matplotlibのインストール手順は下記記事にまとめています。
終わりに
Armは昨年、ソフトバンクからNVIDIAに売却されることで話題になりましたね。Armは業績が伸び悩んでいると言われていますが、今後どうなっていくのか楽しみです。
参考資料
下記記事はOpenSSLで実際の性能を測定しており面白い記事でした。
ARMベースのCPUをバースト利用できる「T4g」インスタンスの性能をOpenSSLで測定してみた | DevelopersIO
日本株の株価をpythonでスクレイピングを使って取得しmatplotlibで可視化する(単一銘柄)
過去数年分の株価をスクレイピングで取得して可視化する手順を紹介します。最終的に以下のようなグラフを作成します。

各銘柄の時価総額や決算情報を取得する手順や、ライブラリ(pandas-datareader)を用いて株価を取得する手順も別の記事にまとめています。
[1] 取得する情報
[1-1] 株式投資メモから取得
株価は株式投資メモから取得させてもらいます。

株式投資メモでは、各銘柄の株価が過去数十年分にわたって閲覧することができます。CSVファイルでダウンロードすることも可能です。
[1-2] URL
URLはhttps://kabuoji3.com/stock/(証券コード)/(年)/になっています。JR東日本(証券コード=9020)の2020年の株価であればhttps://kabuoji3.com/stock/9020/2020/です。
[1-3] HTMLの構成
株価はtable要素に格納されています。tbody要素がありますが、1つ目以外はタグの開始側がなく機能していないので無視して構わないです。
<table class="stock_table stock_data_table"> <thead> <tr> <th>日付</th> <th>始値</th> <th>高値</th> <th>安値</th> <th>終値</th> <th>出来高</th> <th>終値調整</th> </tr> </thead> <tbody> <tr> <td>2020-01-06</td> <td>9785</td> <td>9816</td> <td>9670</td> <td>9676</td> <td>1179000</td> <td>9676</td> </tr> </tbody> <tr> <td>2020-01-07</td> <td>9727</td> <td>9801</td> <td>9701</td> <td>9774</td> <td>900000</td> <td>9774</td> </tr> </tbody> 〜〜〜(中略)〜〜〜 </table>
[2] 403 Forbiddenで上手くいかないので解決する
[2-1] ソースコードと事象
以下のソースコードを実行したところ「403 Forbidden」が返ってきてしまいました。アクセスが拒否されたということです。
code = 9020 year = 2020 # 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html = requests.get(url) print(html) # <Response [403]> print(html.content) # b'<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> # <html><head>\n<title>403 Forbidden</title> # </head><body>\n<h1>Forbidden</h1> # <p>You don\'t have permission to access this resource.</p> # </body></html>\n'
[2-2] 原因
非ブラウザのリクエストを禁止しているようです。スクレイピングを防ぐ意図で禁止しているのかと思いましたが、規約やrobots.txtを確認するとそうではないようです。
そこで今回は、ブラウザからのリクエストと認識されるようにしていきます。クライアントが何なのかは、HTTPヘッダの'User-Agent'に書かれます。なので、'User-Agent'の内容をブラウザからのリクエストに書き換えます。
なお、'User-Agent'については以下の記事に詳しい説明が書かれておりました。
UserAgentからOS/ブラウザなどの調べかたのまとめ - Qiita
[2-3] 解決法
確認くんにアクセスすると「現在のブラウザー」欄に使用しているブラウザの情報が表示されています。その内容をHTMLヘッダにセットします。
以下のソースではhtml_headersというディクショナリを用意し、keyを'User-Agent'にし、valueに確認くんで表示された内容をコピーしています。
# 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html_headers ={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} html = requests.get(url, headers=html_headers)
[3] スクレイピング
[3-1] ソースコード
JR東日本(証券コード=9020)の2016年〜2020年の株価を取得してみます。
code = 9020 # 証券コード start_year = 2016 # 開始年 end_year = 2020 # 終了年 df = None headers = None # 指定した年数分の株価を取得する years = range(start_year, end_year+1) for year in years: # 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html_headers ={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} html = requests.get(url, headers=html_headers) # BeautifulSoupのHTMLパーサーを生成 bs = BeautifulSoup(html.content, "html.parser") # <table>要素を取得 table = bs.find('table') # <table>要素内のヘッダ情報を取得する(初回のみ)。 # (日付, 始値, 高値, 安値, 終値, 出来高, 終値調整) if headers is None: headers = [] thead_th = table.find('thead').find_all('th') for th in thead_th: headers.append(th.text) # <tr>要素のデータを取得する。 rows = [] tr_all = table.find_all('tr') for i, tr in enumerate(tr_all): # 最初の行は<thead>要素なので飛ばす if i==0: continue # <tr>要素内の<td>要素を取得する。 row = [] td_all = tr.find_all('td') for td in td_all: row.append(td.text) # 1行のデータをリストに追加 rows.append(row) # DataFrameを生成する df_tmp = pd.DataFrame(rows, columns=headers) # DataFrameを結合する if df is None: df = df_tmp else: df = pd.concat([df, df_tmp]) # 1秒ディレイ time.sleep(1) print(df.head()) # 日付 始値 高値 安値 終値 出来高 終値調整 # 0 2016-01-04 11360 11410 11100 11125 748400 11125 # 1 2016-01-05 11100 11300 11035 11205 896700 11205 # 2 2016-01-06 11275 11400 11055 11135 699200 11135 # 3 2016-01-07 11255 11305 11040 11050 1095000 11050 # 4 2016-01-08 10950 11180 10855 10875 1100300 10875
[3-2] データ型を変換する
取得したデータの型を確認すると、すべて'object'型になっています。このままでは、グラフ表示や移動平均算出の際に都合が悪いです。
print(df.dtypes) # 日付 object # 始値 object # 高値 object # 安値 object # 終値 object # 出来高 object # 終値調整 object # dtype: object
日付はdatatime型、それ以外はfloat型に変換します。
# 列とデータ型の組み合わせを設定 dtypes = {} for column in df.columns: if column == '日付': dtypes[column] = 'datetime64' else: dtypes[column] = 'float64' # データ型を変換 df = df.astype(dtypes) # インデックスを日付に変更 df = df.set_index('日付')
[4] 可視化
[4-1] 終値をグラフ表示
まずは、終値を単純に折れ線グラフにしてみます。

# FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(1,1,1) # 終値の折れ線グラフを追加 x = df['日付'] y = df['終値'] ax.plot(x, y, label='終値', linewidth=2.0) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # グラフを表示 fig.show()
[4-2] 移動平均を算出
続いて、チャートでよくみる移動平均を算出します。
df['5日移動平均'] = df['終値'].rolling(window=5).mean() df['25日移動平均'] = df['終値'].rolling(window=25).mean() df['75日移動平均'] = df['終値'].rolling(window=75).mean()
[4-3] 移動平均をグラフ表示
移動平均をグラフ表示するにあたり、2020/01/01以降のデータに絞ります。
# 2020/01/01以降のデータを抽出 df = df['2020-01-01':]
グラフ表示してみると以下のようになりました。以下はJR東日本の株価です。コロナウィルスの影響もあり、長期で見ると株価は下がり続けています。
# FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(1,1,1) # 終値の折れ線グラフを追加 x = df['日付'] y = df['終値'] ax.plot(x, y, label='終値', linewidth=2.0) # 移動平均の折れ線グラフを追加 average_columns = ['5日移動平均', '25日移動平均', '75日移動平均'] for column in average_columns: x = df['日付'] y = df[column] ax.plot(x, y, label=column, linewidth=1.0) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # グラフを表示 fig.show()
終わりに
株価をスクレイピングで取得してグラフ表示することができました。
しかし、単一銘柄の株価を見るだけであれば、色々なところで簡単に見れるので、自分でわざわざ作る価値はそれほどないでしょう。
次回は複数銘柄の比較と可視化を行い、作る価値のあるデータを作っていきます。
出典
- アイキャッチはGerd AltmannによるPixabayからの画像
【読書】最新書籍で紹介されていた世界注目の企業

<最新書籍で紹介されていた世界注目の企業>*1
2020年発売の書籍で紹介されていた世界注目の企業を紹介します。すでに世界で成功を収め今後も成長が見込める企業、今後急成長し市場破壊を起こすだろう企業が紹介されていました。
- サステナベーション sustainability × innovation ――多様性時代における企業の羅針盤
- フードテック革命 世界700兆円の新産業 「食」の進化と再定義
- アフターデジタル2 UXと自由
書籍で扱っていた全ての企業を紹介しているわけではありません。また、各企業については概要しか書いていません。詳細に興味がある方は、ぜひ書籍を購入するかご自分で調べてみてください。
中国
アリババ
最近、中国当局と揉めて話題になっているアリババです。知っている方も多いと思いますが、中国ECの超大手です。ECだけでなく様々な事業を持っているプラットフォーマーです。以下が主な事業です。
テンセント
メッセンジャーアプリ「WeChat」で有名な企業です。「WeChat」を基点として様々なサービスを提供しているプラットフォーマーなのはアリババと同じです。例えば、WeChatペイなどです。
アリババとの違いは、ゲーム事業で大きな収益を挙げていることです。テンセントミュージックという音楽サービスも展開しています。
NIO
電気自走車のメーカーで、中国で最も販売台数が多いのがNIOです。電気自動車自体よりも会員サービスが特徴的であり、NIO経済圏に顧客を引き込んでいます。会員サービスは、充電サービス、メンテナンス、ラウンジ・イベント、SNS・ECを提供しています。
電気自動車は充電に時間がかかりますが、電池パックそのものを交換するデリバリーサービスを提供しており、好評を得ています。また、ラウンジの提供やイベントの開催を、NIO専用のSNSで投稿してもらい、ポイントを貯めてグッズを買ってもらうことも行っています。
このように、NIOコミュニティでのコミュニケーションと購買を促し、ファンを獲得しています。
ZiRoom
若者向け賃貸サービスです。賃貸物件探し、生活サービス、旅行、コミュニティを提供しています。
生活サービスは管理費を上乗せすることで、定期的な清掃や家具の修理を提供しています。旅行は、中国国内で旅行する際にZiRoomの空き部屋に安価で宿泊できます。コミュニティでは、マンション内のイベントスペースを提供したり、近所のZiRoomユーザーのチャットグループを用意したりしています。
衆安保険
オンライン保険会社で、以下のような保険をOEMで提供しています。OEMなのでユーザー側に衆安保険の名前は出てこず、サービサーの名前で保険が販売されます。サービサーの保険を作りたいというニーズに応えるサービスです。
- 飛行機遅延保険
- 高温保険
- 糖尿病保険
- 返品運賃保険
イギリス
Digi.me
個人情報を一元管理するサービスを提供しています。SNSや財務管理サービス, スマートウォッチなどにより外部企業が保有している自分自身の個人データを、収集し一元管理できるようにしました。
これは個人情報管理に厳しい欧州、とくにイギリスならではのサービスと言えます。イギリスでは個人情報の活用を本人が選択できます。企業が保有している自身のデータにアクセスできるように政府主導で推進してきました。
エバーレッジャー
ダイヤモンドの産地や所有者の情報をブロックチェーンで電子台帳化するサービスを提供しています。電子化することで、産地の偽造や改ざん、詐欺を防げるようにしています。
ダイヤモンドの採掘は紛争地の貧困層によって行われるケースが増えていました。しかし、利益は貧困層と国に渡らず地元住民は貧乏なまま。産地は偽られ、紛争地のダイヤとは分からずに購入するのはよくあることでした。
東南アジア
Grab
ライドシェアサービス大手です。ライドシェアだけでなく「GrabPay」というキャッシュレス決済、デリバリーフードや食事のピックアップサービスも行っていますが、特に重要なのは金融サービスです。Grabで得たドライバーの情報から与信管理を行い、ドライバー向けの融資も行っています。
アメリカ
Casper
マットレス直販を行うD2Cブランドです。商品の購入はオンラインのみ、100日間返品可能、美しい包装といった特徴がありますが、特筆すべきは質の高いブランディングです。
睡眠は人間のウェルネスを決める重要な要素と位置付け、ウェルネスをテーマにした雑誌を自社で発行したりポッドキャストを展開したりして、ファンを獲得しました。
インポッシブルフーズ
動物肉を使わない代替肉である「植物性パティ」を製造しており、既に15,000点以上のレストランで採用されています。2020年3月時点で総額10億2,800万ドルの資金調達規模です。
近年問題化している、人口増加による肉の消費量増加、畜産の道義上の問題と環境問題、健康被害の解決作として代替肉は強く期待されています。
ビヨンドミート
インポッシブルフーズと同様に植物性パティを製造しています。2020年12月時点で時価総額は70億ドルを超えています。
イニット, サイドシェフ, シェフリング
キッチンOSの代表的なプレーヤーです。
キッチンOSは、スマート調理家電をコントロールするソフトウェアです。例えば、スマホアプリからレシピを選択すると、調理家電がレシピ通りに調理するといったことが可能になります。
キッチンOSにより、今まで得られなかったユーザー個別の食に関するデータが得られます。GAFAがデータを活用して巨大企業にまで成長したことは誰もが知っていますが、それと同じことが食でも起こるのかと注目されています。
日本
グローバルモビリティサービス
東南アジアの車社会に貢献している企業で、車載IoTデバイス「MCCS」が有名です。MCCSには加速度センサーやGPSが付いており、搭載した車がどこにいるか、どのような運転がされたかを24時間把握できます。
新興国では車を購入するのにローンが組めず購入できない場合が多かったです。しかし、MCCSを搭載した車であれば与信審査に通りやすくなります。例えば、タクシー運転手をしたい若者の与信審査をする場合に、MCCS搭載車であれば運転手が安全に運転しているかを把握できます。もし、ローンの返済が滞ったり危険な運転を行ってれば、遠隔で車を動かせなくすることも可能です。
南アフリカ
ルムカニ
スラム向け火災報知器を開発・販売しています。スラムは木や段ボールなど燃えやすい資材で作られており、火災が発生すると瞬く間に燃え広がるという問題がありました。
ルムカニの火災報知器は安価に簡単に取り付けができます。また、火災報知器から住民の生活情報を収集し信用調査が行えるようになったことで、スラムの住民が火災保険に加入できるようになりました。
*1:Gerd AltmannによるPixabayからの画像
*2:正確にはアリババではなく、アリババ関連企業のアントフィナンシャルが運営しています
日本株の情報をスクレイピングで取得しmatplotlibで可視化する

前回の続きです。前回は、複数銘柄の決算情報と財務情報をスクレイピングで取得しました。今回は前回取得した情報を可視化します。

[1] 基本的な指標の可視化
まずは前々回取得した以下の基本的な指標データを可視化してみます。
| 配当利回り | PER(調整後) | PSR | PBR | 出来高(千株) | 時価総額(兆円) | |
|---|---|---|---|---|---|---|
| JR東日本 | 2.53 | 12.39 | 0.83 | 0.77 | 1965.8 | 2.458450 |
| JR東海 | 1.04 | 7.07 | 1.60 | 0.76 | 701.9 | 2.957130 |
| JR西日本 | 3.59 | 10.85 | 0.64 | 0.79 | 1247.9 | 0.970065 |
| 東急 | 1.67 | 19.61 | 0.73 | 1.05 | 1104.6 | 0.856696 |
| 近鉄 | 1.05 | 43.77 | 0.75 | 2.22 | 387.7 | 0.902784 |
| 平均値 | 1.98 | 18.74 | 0.91 | 1.12 | 1081.6 | 1.629025 |
| 標準偏差 | 1.09 | 14.71 | 0.39 | 0.63 | 599.1 | 1.001244 |
[1-1] matplotlibをインストール
pip3 install matplotlib --user
[1-2] PERの可視化
まずは、PERを棒グラフで可視化します。
import matplotlib.pyplot as plt # '標準偏差'の列を削除 df = df.drop(index='標準偏差') # FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(111) # グラフ表示するデータを取得 per = df['PER(調整後)'] # PER xpos = np.arange(len(per)) # X軸上の位置(0, 1, 2, ...) # 棒グラフを作成 ax.bar(xpos, per) # X軸に銘柄名を表示 ax.set(xticks=xpos, xticklabels=df.index) # 補助線を描画 ax.grid(axis='y', color='gray', ls='--') # 凡例を表示 ax.legend(['PER(調整後)']) # グラフを表示 fig.show()
結果、次のようなグラフが得られます。

グラフ内の日本語は文字化けする場合があります。その場合は、日本語フォントのインストールが必要です(Amazon Linuxの場合は拙著参照)。
[1-3] PSRとPBRの可視化
次に、PSRとPBRを可視化します。
# 可視化する列 columns = ['PSR', 'PBR'] # FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(111) # データ数を取得 num_data = df.shape[0] # 銘柄の数 num_column = len(columns) # 可視化する列の数 # 棒グラフを横並びで表示するためのパラメータ width = 0.8 / num_column # 棒グラフの幅 xpos = np.arange(num_data) # X軸上の位置 # 指定した列数分ループ for i in range(num_column): col = columns[i] x = xpos + width * i y = df[col] # 棒グラフを表示 ax.bar(x, y, width=width, align='center') # X軸の目盛位置を調整し、銘柄名を表示 labels = df.index.values offset = width / 2 * (num_column - 1) ax.set(xticks=xpos+offset, xticklabels=labels) # 補助線を描画 ax.grid(axis='y', color='gray', ls='--') # 凡例を表示 ax.legend(columns) # グラフを表示 fig.show()
結果、次のグラフが得られました。 棒グラフを横並びにするのには、少々手間がかかります。下記サイトを参考にさせていただきました。
【Python】matplotlibで色んな種類の棒グラフを表示する方法 | 侍エンジニアブログ

近鉄GHDのPBRが高いですね。PBR = 時価総額 / 株主資本ですから、B/S上の価値よりも市場に高く評価されていると言えます。
[2] 決算情報の可視化
続いて、前回得た決算情報・財務情報を可視化します。
| ROA | ROE | ||
|---|---|---|---|
| 名称 | 決算期 | ||
| JR東日本 | 2020年3月期 | 2.32 | 6.25 |
| 2019年3月期 | 3.53 | 9.54 | |
| JR東海 | 2020年3月期 | 4.14 | 10.28 |
| 2019年3月期 | 4.72 | 12.51 |
[2-1] ROEの可視化
まずは、ROEを折れ線グラフで可視化します。
# FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(1,1,1) # 銘柄の名称リスト brand_names = list(df.index.unique('名称')) # 可視化するデータの名称 data_name = 'ROE' # 全銘柄のデータを折れ線グラフに表示 for brand_name in brand_names: brand_df = df.loc[(brand_name,)] # 指定した銘柄のデータ x = brand_df.index # 決算期 y = brand_df[data_name] # 可視化するデータ # 折れ線グラフ表示 ax.plot(x, y, marker='o') # 補助線を描画 ax.grid(axis='y', color='gray', ls='--') # 軸ラベルをセット plt.xlabel(data_name, size=15) # 凡例を表示 ax.legend(brand_names) # グラフを表示 fig.show()
結果、次のグラフが得られました。

[2-2] ROEとROAの可視化
次に、ROEとROAをセットで可視化して、1つの図に収めます。
# 可視化するデータ data_names = ['ROE', 'ROA'] # Figurを取得 fig = plt.figure(figsize=(10, 4)) # 指定した全データをデータ別に折れ線グラフで表示する for i, data_name in enumerate(data_names): # Axesを取得 ax = fig.add_subplot(1, 2, i+1) # 銘柄の名称リスト brand_names = list(df.index.unique('名称')) # 全銘柄のデータを折れ線グラフに表示 for brand_name in brand_names: brand_df = df.loc[(brand_name,)] # 指定した銘柄のデータ x = brand_df.index # 決算期 y = brand_df[data_name] # 可視化するデータ # 折れ線グラフ表示 ax.plot(x, y, marker='o') # 補助線を描画 ax.grid(axis='y', color='gray', ls='--') # 軸ラベルをセット plt.xlabel(data_name, size=15) # 凡例を表示 ax.legend(brand_names) # 不要な余白を削る plt.tight_layout() # グラフを表示 fig.show()
結果、次のグラフが得られました。

JR東海は利益率が高いことで知られていますが、ROE・ROAが高いことからもそのことが窺えます。
また、2020年3月期はどの鉄道会社もROE・ROAが低下しています。これは、2020年2月頃からコロナウィルスの感染拡大があったことや、2019年10月の増税の影響によるものではないかと推測できます。
[2-3] 1銘柄の決算情報を可視化
詳細は割愛しますが、これまで紹介してきた内容を組み合わせると、次のようなグラフを作ることも可能です。
2018年度末(2019年3月期)までは、売上高・利益ともに伸びていましたが、2020年3月期は落ち込んでいます。
終わりに
今回は、スクレイピングで取得した情報を「matplotlib」で可視化しました。
今回行った可視化は複雑なものではありませんが、それでも可視化することによって得られる情報はあります。
株に関して言えば、個々の銘柄の情報は簡単に調べることが出来ますが、複数銘柄を比較できるサイトが少ないです。比較はできても、自分が比較したい情報は無いという場合もあります。
まずは、自力でExcelなどに手入力してみて、自動化したくなったら今回のようにするとよいのかもしれません。
*1:Lorenzo CafaroによるPixabayからの画像
【AWS】Route53でドメインを登録してHTTPS対応のnginxサーバーをCloudFrontとCloudFormationで構築するまで

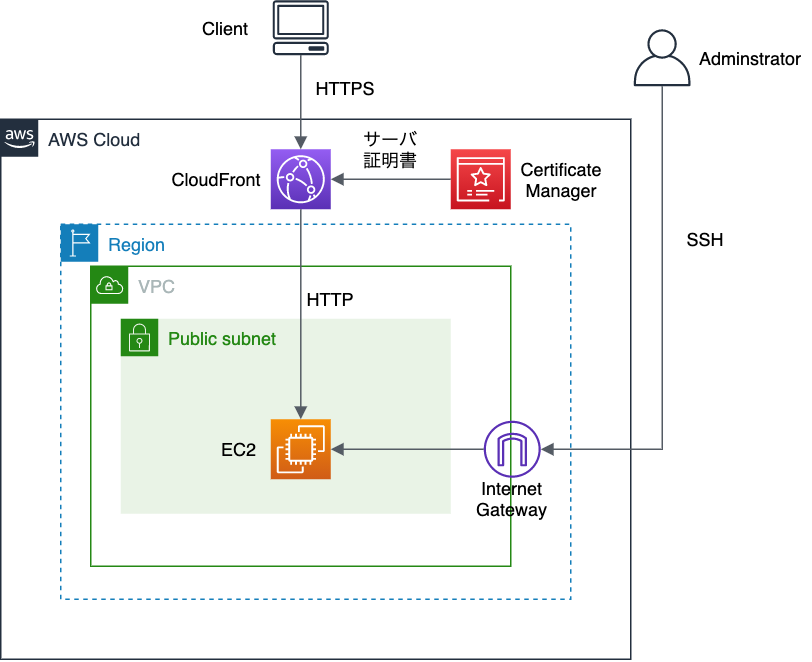
AWSでHTTPS対応のnginxサーバーを構築するまでの手順をまとめました。
HTTPS対応のサーバーを構築する手順は多々あります。今回は「CertificateManager」でサーバ証明書を発行し「CloudFront」でHTTPS対応する構成にしました。
Route53で独自ドメインの登録を行いましたが、別のプロバイダで登録することも可能です。
- [0] 前提条件
- [1] Route53でドメイン登録
- [2] Certificate Managerで証明書発行
- [3] EC2インスタンス構築
- [4] nginxインストール
- [5] セキュリティグループの設定
- [6] CloudFrontの設定
- [7] 動作確認
- [8] スタックの削除
- 終わりに
- 参考資料
[0] 前提条件
nginxインストールなどの操作を行うために、EC2へSSHでログインします。SSHでログインするためのキーペアは作成済みとします。
[前提条件]
- キーペアは作成済み
[1] Route53でドメイン登録
マネージメントコンソールから、Route53で独自ドメインを登録します。
[1-1] ドメインの選択
ドメインの選択欄にドメイン名を入力し[チェック]を押すと、利用可能か否かと料金が表示されます。

[カートに入れる]を押すとカートに料金と登録期間が表示されます。登録期間を過ぎても自動延長できます。長期間使用する予定がなければ1年のままで問題ありません。画面下部の[続行]を押して次に進みます。

[1-2] 連絡先の入力と購入
登録者の連絡先を登録します。電話番号以外は日本語表記で問題ありません。
プライバシーの保護は、個人の場合は[有効化]にしておきます。

[続行]を押すと、次のように表示されますが問題ありませんでした。心配な場合は連絡先に登録したEメールを確認しましょう。AWSからメールが来ているはずです。

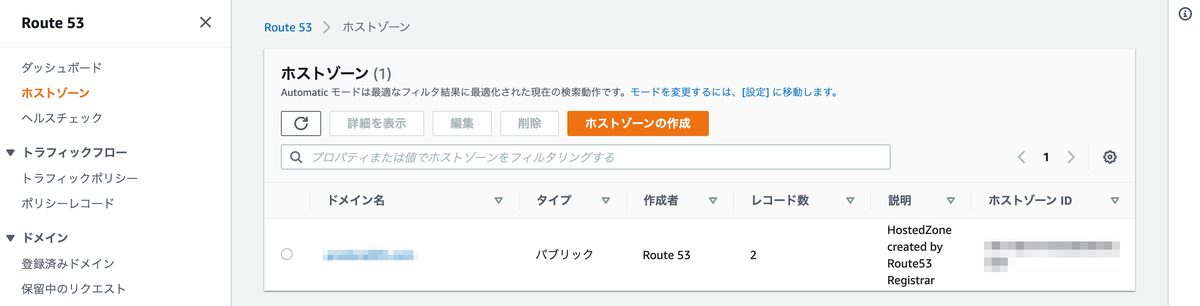
ドメインを登録すると自動的にホストゾーンが作成されます。ホストゾーンは12時間以上使用すると、0.5$/月かかります。しばらく使用しない場合は後で手動で削除しましょう。
ドメインの自動更新は個々の目的に応じて選びます。

連絡先に登録したEメールを確認し、メール内のリンクをクリックします。

リンクをクリックした後、[ステータスの更新]を押します。すると、ステータスが検証済みになります。
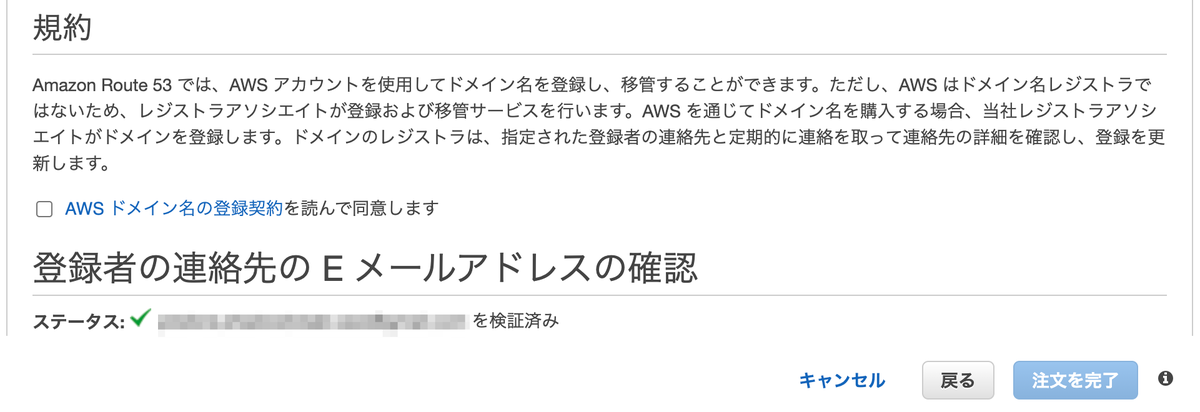
以上でドメインの登録は完了です。ドメイン登録が完了して使えるようになるまでには多少時間がかかります。私の場合は30分かかりました。

ホストゾーンが自動作成されたかを確認すると、作成されていました。
[2] Certificate Managerで証明書発行
続いて、Certificate Managerでサーバ証明書を発行します。証明書の発行は無料です。
なお、リージョンは「米国東部(バージニア北部)」にします。別のリージョンで発行するとCloudFrontと証明書の関連付けが出来ません。
CloudFront で SSL/TLS 証明書を使用するための要件 - Amazon CloudFront
CloudFront ディストリビューションで使用するために SSL 証明書を米国東部 (バージニア北部) リージョンに移行する
[2-1] 証明書発行

[パブリック証明書のリクエスト]を選択します。

ドメイン名を入力します。登録したドメインがexample.comであれば、example.comと*.example.comを登録します。ワイルドカードを使用してサブドメインも登録します。

検証方法は[DNSの検証]にします。

証明書を多数発行するなど特別な理由がなければ、タグは空欄のままで問題ありません。

内容を確認し[確認とリクエスト]を押します。

[2-2] 検証
「検証保留中」になっています。これを「発行済み」にしていきます。ドメイン名横のドロップダウンを選択します。

[Route53でのレコードの作成]を押下します。

[作成]を押します。

もう一方も同様にDNSレコードを作成します。
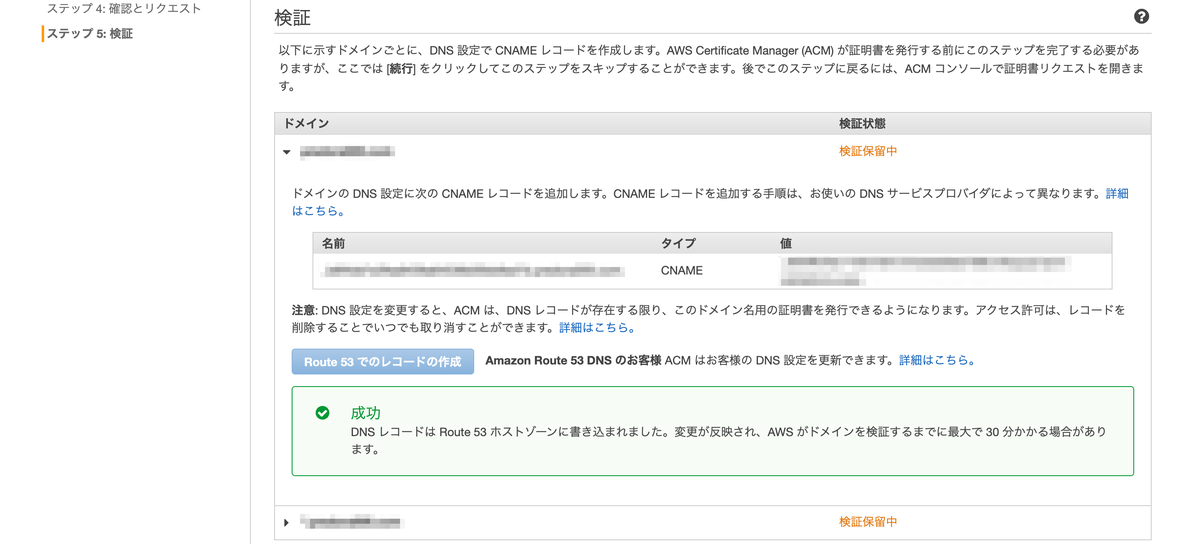
以上で証明書発行の手続きは完了です。「検証保留中」になっていますが、数分経つと「発行済み」に変わります。

[3] EC2インスタンス構築
EC2インスタンス構築に当たり、次のものを作成する必要があります。
これらを毎回手動で構築するのは面倒です。なので、CloudFormationで自動化します。
[3-1] CloudFormationのテンプレート
[3-1-1] テンプレートバージョン
テンプレートバージョンは固定です。Descriptionは任意です。
AWSTemplateFormatVersion: 2010-09-09 Description: >- AWS CloudFormation template for the nginx server.
[3-1-2] パラメータ
次の内容はユーザーが決められるようにします。Defaultを指定しておけば毎回入力する必要がなくて楽です。
Parameters: # SSHのキー名称 KeyName: Description: Name of an existing EC2 KeyPair to enable SSH access to the instance Type: 'AWS::EC2::KeyPair::KeyName' ConstraintDescription: Can contain only ASCII characters. # インスタンスタイプをリストから選択 InstanceType: Description: EC2 instance type Type: String Default: t3.micro AllowedValues: - t3.nano - t3.micro - t3.small - t3.medium ConstraintDescription: must be a valid EC2 instance type. # EBSの容量 VolumeSize: Description: 'Volume size of EBS' Type: Number Default: 8 ConstraintDescription: expect size >= 8GB. # CIDR VpcCidr: Description: 'VPC CIDR' Type: String Default: 10.0.0.0/16 SubnetCidr: Description: 'Subnet CIDR' Type: String Default: 10.0.0.0/24 # プライベートIPアドレス PrivateIpAddress: Description: 'Private IP Address.' Type: String Default: '10.0.0.10'
[3-1-3] ネットワーク周り
VPC, サブネット, ルートテーブル, インターネットゲートウェイの設定です。特殊なのはVPCのEnableDnsHostnamesとEnableDnsSupportをtrueにすることです。デフォルトはfalseですが、CloudFrontの設定時に必要なためtrueにします。
Resources: # VPC Vpc: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Ref VpcCidr # DNSはCloudFrontのOrigin Domain Name指定のために必要 EnableDnsHostnames: true EnableDnsSupport: true Tags: - Key: Name Value: !Sub '${AWS::StackName}-vpc' # サブネット Subnet: Type: 'AWS::EC2::Subnet' Properties: VpcId: !Ref Vpc CidrBlock: !Ref SubnetCidr Tags: - Key: Name Value: !Sub '${AWS::StackName}-ec2-sb' # インターネットゲートウェイ IGW: Type: 'AWS::EC2::InternetGateway' Properties: Tags: - Key: Name Value: !Sub '${AWS::StackName}-igw' IGW2Vpc: Type: 'AWS::EC2::VPCGatewayAttachment' Properties: InternetGatewayId: !Ref IGW VpcId: !Ref Vpc # ルートテーブル RouteTable: Type: 'AWS::EC2::RouteTable' Properties: VpcId: !Ref Vpc Tags: - Key: Name Value: !Sub '${AWS::StackName}-ec2-rt' RT2Subnet: Type: 'AWS::EC2::SubnetRouteTableAssociation' Properties: SubnetId: !Ref Subnet RouteTableId: !Ref RouteTable Route: Type: 'AWS::EC2::Route' Properties: GatewayId: !Ref IGW RouteTableId: !Ref RouteTable DestinationCidrBlock: 0.0.0.0/0
[3-1-4] セキュリティグループ
セキュリティグループは少々複雑です。4つセキュリティグループを作成するのには理由があります。
セキュリティグループ1は、EC2へのSSHアクセスと、EC2からnginxインストール等の作業を可能にするための設定です。これは普通の設定です。
セキュリティグループ2, 3, 4は、CloudFrontからのHTTPアクセスのみ受け付けるためです。CloudFrontは世界中にエッジサーバを持っており、どのサーバからアクセスされるか分かりません。そのため、全エッジサーバのIPアドレスをセキュリティグループに登録しておく必要があります。
セキュリティグループへの登録は、EC2構築後にシェルスクリプトで行います。CloudFormationでは中身が空のセキュリティグループを準備しておきます。3つ用意するのは、セキュリティグループのルール数に制限があるからです。デフォルトでは60ルールまでですが、CloudFrontのIPアドレスは100以上有るため、複数用意しておきます。
# セキュリティグループ1 SecurityGroup1: Type: 'AWS::EC2::SecurityGroup' Properties: GroupName: !Sub '${AWS::StackName}-ec2-sg1' GroupDescription: !Sub '${AWS::StackName}-ec2-sg1' VpcId: !Ref Vpc Tags: - Key: Name Value: !Sub '${AWS::StackName}-ec2-sg1' # インバウンド: SSH許可 SecurityGroupIngress: - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: 0.0.0.0/0 # アウトバウンド: HTTPとHTTPS許可 SecurityGroupEgress: - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: 0.0.0.0/0 - IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: 0.0.0.0/0 # セキュリティグループ2 (for CloudFront) SecurityGroup2: Type: 'AWS::EC2::SecurityGroup' Properties: GroupName: !Sub '${AWS::StackName}-ec2-sg2' GroupDescription: !Sub '${AWS::StackName}-ec2-sg2' VpcId: !Ref Vpc Tags: - Key: Name Value: !Sub '${AWS::StackName}-ec2-sg2' # セキュリティグループ3 (for CloudFront) SecurityGroup3: Type: 'AWS::EC2::SecurityGroup' Properties: GroupName: !Sub '${AWS::StackName}-ec2-sg3' GroupDescription: !Sub '${AWS::StackName}-ec2-sg3' VpcId: !Ref Vpc Tags: - Key: Name Value: !Sub '${AWS::StackName}-ec2-sg3' # セキュリティグループ4 (for CloudFront) SecurityGroup4: Type: 'AWS::EC2::SecurityGroup' Properties: GroupName: !Sub '${AWS::StackName}-ec2-sg4' GroupDescription: !Sub '${AWS::StackName}-ec2-sg4' VpcId: !Ref Vpc Tags: - Key: Name Value: !Sub '${AWS::StackName}-ec2-sg4'
Amazon VPC でセキュリティグループルールの制限を増やす
[3-1-5] IAMロール
IAMロールは通常不要です。わざわざ設定するのは、EC2からCloudFrontのIPアドレスをセキュリティグループに登録するためです。セキュリティグループの変更は、EC2構築後にEC2から行います。EC2にセキュリティグループ操作の権限を付与します。
# IAMロール SecurityGroupAccessRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "ec2.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" # IAMポリシー SecurityGroupAccessPolicies: Type: AWS::IAM::Policy Properties: PolicyName: SecurityGroupAccess PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow # 自リージョン・自アカウントのセキュリティグループの変更を許可 Action: - 'ec2:AuthorizeSecurityGroupEgress' - 'ec2:AuthorizeSecurityGroupIngress' - 'ec2:DeleteSecurityGroup' - 'ec2:RevokeSecurityGroupEgress' - 'ec2:RevokeSecurityGroupIngress' Resource: !Sub 'arn:aws:ec2:${AWS::Region}:${AWS::AccountId}:security-group/*' # 作成するVPCのセキュリティグループのみに限定する Condition: ArnEquals: 'ec2:Vpc': !Sub 'arn:aws:ec2:${AWS::Region}:${AWS::AccountId}:vpc/${Vpc}' - Effect: Allow Action: - 'ec2:DescribeSecurityGroups' - 'ec2:DescribeSecurityGroupReferences' - 'ec2:DescribeStaleSecurityGroups' - 'ec2:DescribeVpcs' Resource: '*' Roles: - !Ref SecurityGroupAccessRole # IAMインスタンスプロファイル SecurityGroupAccessInstanceProfile: Type: AWS::IAM::InstanceProfile Properties: Path: "/" Roles: - !Ref SecurityGroupAccessRole
[3-1-6] EC2 (前半)
ここでは、リージョンは東京(ap-northeast-1)、OSはAmazon Linux2で構築する設定にしています。UserDataはEC2構築後にjq, curlを自動インストールし、シェルスクリプトを自動生成するための設定です。
# インスタンス Instance: Type: 'AWS::EC2::Instance' # プロパティ Properties: # ap-northeast-1のAmazon Linux2 ImageId: 'ami-01748a72bed07727c' InstanceType: !Ref InstanceType # ネットワーク周りの設定 NetworkInterfaces: - AssociatePublicIpAddress: true DeviceIndex: 0 GroupSet: - Ref: SecurityGroup1 - Ref: SecurityGroup2 - Ref: SecurityGroup3 - Ref: SecurityGroup4 SubnetId: Ref: Subnet PrivateIpAddress: !Ref PrivateIpAddress # SSHのキー名称 KeyName: !Ref KeyName # EBSの設定 BlockDeviceMappings: - DeviceName: /dev/xvda Ebs: VolumeSize: !Ref VolumeSize VolumeType: gp2 DeleteOnTermination: true # IAM IamInstanceProfile: !Ref SecurityGroupAccessInstanceProfile # タグ Tags: - Key: Application Value: String - Key: Name Value: !Sub '${AWS::StackName}-inst' # ユーザーデータ UserData: !Base64 Fn::Sub: | #!/bin/bash yum -y update yum -y install aws-cfn-bootstrap /opt/aws/bin/cfn-init -v --stack ${AWS::StackName} --resource Instance --region ${AWS::Region} /opt/aws/bin/cfn-signal -e $? --stack ${AWS::StackName} --resource Instance --region ${AWS::Region}
[3-1-7] EC2 (後半)
EC2構築後にjq, curlを自動インストールし、シェルスクリプトを自動生成するための設定です。スクリプトの詳細は後述しますが下記記事を参考にさせていただいています。
EC2のセキュリティグループにCloudFrontからしかアクセスを許可しない設定を追加する(改良版) | 綺麗に死ぬITエンジニア
# メタデータ Metadata: AWS::CloudFormation::Init: config: # jq, curlをインストール packages: yum: jq: [] curl: [] files: # セキュリティグループ変更用のスクリプト '/home/ec2-user/set_security_group.sh': content: Fn::Sub: | #!/bin/bash IP_RANGE=`curl -s https://ip-ranges.amazonaws.com/ip-ranges.json` IP_LIST=`echo $IP_RANGE | jq -r '.prefixes[] | if .service == "CLOUDFRONT" then .ip_prefix else empty end'` count=0 for IP in $IP_LIST; do if [ $count -lt 60 ]; then SG=${SecurityGroup2} elif [ $count -lt 120 ]; then SG=${SecurityGroup3} else SG=${SecurityGroup4} fi aws ec2 authorize-security-group-ingress --region ${AWS::Region} --group-id $SG --protocol tcp --port 80 --cidr $IP echo $IP (( count++ )) done mode: '000644' owner: 'ec2-user' group: 'ec2-user' # nginxインストール用のスクリプト '/home/ec2-user/install_nginx.sh': content: Fn::Sub: | #!/bin/bash sudo amazon-linux-extras install nginx1 -y sudo systemctl start nginx sudo systemctl enable nginx mode: '000644' owner: 'ec2-user' group: 'ec2-user'
[3-1-8] Elastic IP
サーバーを再起動するたびにパブリックIPが変わると面倒なので、Elastic IPを設定しておきます。
# Elastic IP ElasticIp: Type: AWS::EC2::EIP Properties: InstanceId: !Ref Instance Domain: vpc
[3-2] スタックの作成
テンプレートが準備できたらスタックを作成します。
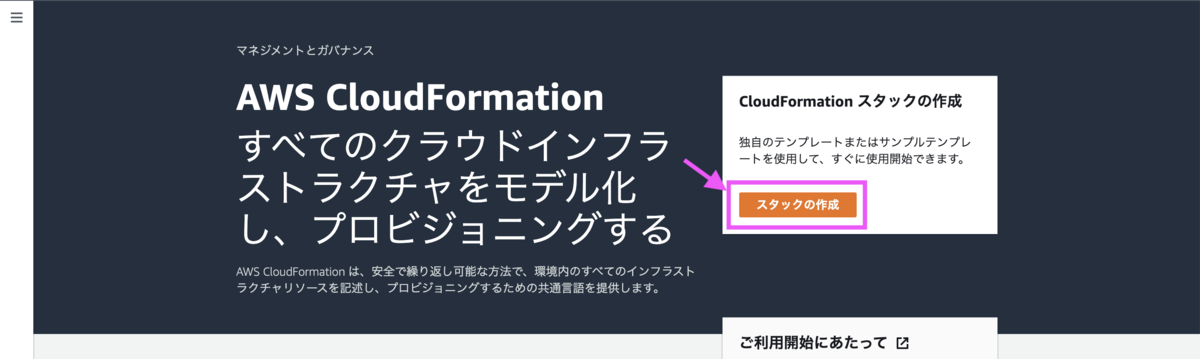
テンプレートファイルはローカルからのアップロードを選択しました。S3にアップロードしたものを参照することも可能です。

スタックの名前は任意の名称を入力します。今回は'stack1'としました。

パラメータはキーペアの名称(KeyName)以外はデフォルトのままにしました。キーペアのみコンボボックスから作成済みのキーペアを選択します。
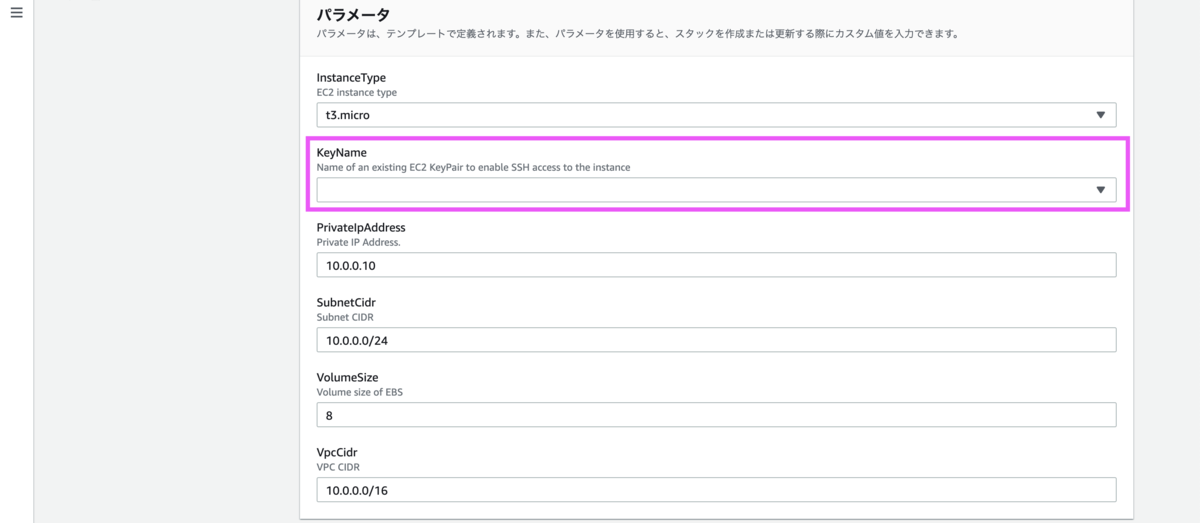
「スタックオプションの設定」は変更なしで次に進みます。

「レビュー」では末尾の機能のみ注意が必要です。今回作成したテンプレートではIAMロールをEC2に付与しています。IAMリソースを作成しても問題ないか問われるので、チェックボックスにチェックして[スタックの作成]を押下します。
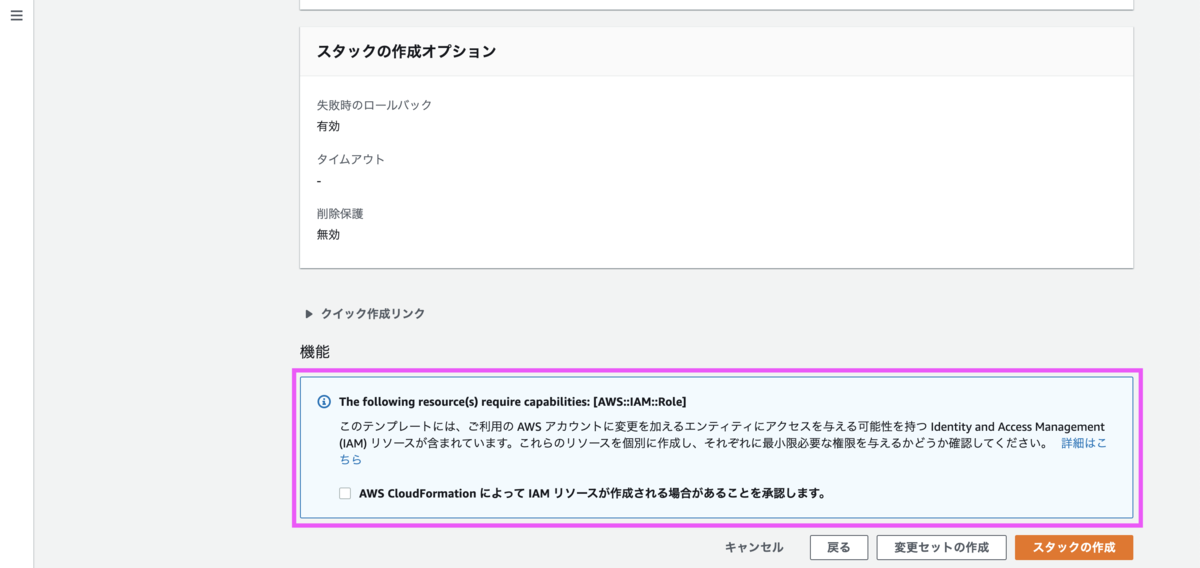
数分待つとスタックの作成が完了します。

インスタンスの状態を確認すると、設定通りに作成されていることが分かります。

[4] nginxインストール
EC2にsshでログインして、install_nginx.shを実行します。
sh install_nginx.sh
スクリプトの中身は次の通りです。nginxはAmazon Linux 2のextrasレポジトリで配布されているものをインストールします。
#!/bin/bash sudo amazon-linux-extras install nginx1 -y sudo systemctl start nginx sudo systemctl enable nginx
インストール後にバージョンを確認すると無事インストールされたことが分かります。
nginx -v # nginx version: nginx/1.18.0
[5] セキュリティグループの設定
EC2でset_security_group.shを実行します。
sh set_security_group.sh
実行後にマネージメントコンソールで確認すると、インバウンドルールが追加されています。
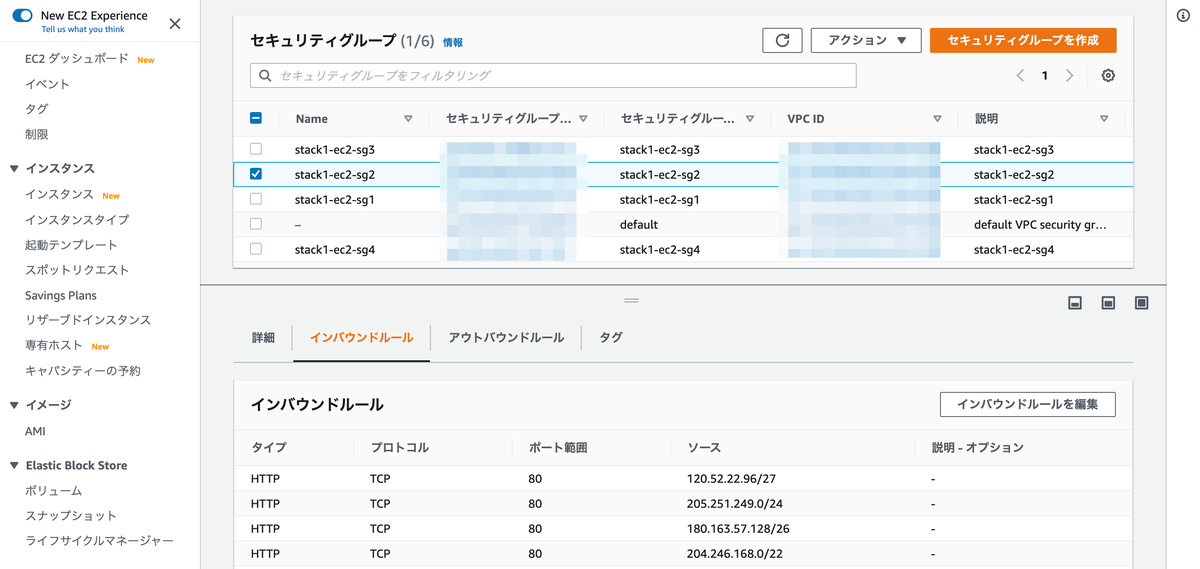
スクリプトの中身は次の通りです。セキュリティグループのIDとリージョン名は、スタック作成時に自動で設定されます。
#!/bin/bash IP_RANGE=`curl -s https://ip-ranges.amazonaws.com/ip-ranges.json` IP_LIST=`echo $IP_RANGE | jq -r '.prefixes[] | if .service == "CLOUDFRONT" then .ip_prefix else empty end'` count=0 for IP in $IP_LIST; do if [ $count -lt 60 ]; then SG={セキュリティグループ2のID} elif [ $count -lt 120 ]; then SG={セキュリティグループ3のID} else SG={セキュリティグループ4のID} fi aws ec2 authorize-security-group-ingress --region {リージョン名} --group-id $SG --protocol tcp --port 80 --cidr $IP echo $IP (( count++ )) done
[5-1] シェルスクリプトの解説
シェルスクリプトは下記記事を参考にさせていただきました。
EC2のセキュリティグループにCloudFrontからしかアクセスを許可しない設定を追加する(改良版) | 綺麗に死ぬITエンジニア
[5-1-1] CloudFrontのIPアドレス取得
CloudFrontエッジサーバのIPアドレスはip-ranges.jsonから取得します。ip-ranges.jsonから必要な情報をjqコマンドで取り出します。
ip-ranges.jsonはCloudFront以外の情報も含んでいます。service == "CLOUDFRONT"でCloudFrontの情報を抽出します。また、抽出した情報はIPアドレス以外の情報も含んでいるため.ip_prefixでIPアドレスを抽出します。
IP_RANGE=`curl -s https://ip-ranges.amazonaws.com/ip-ranges.json` IP_LIST=`echo $IP_RANGE | jq -r '.prefixes[] | if .service == "CLOUDFRONT" then .ip_prefix else empty end'`
[5-1-2] セキュリティグループのルール追加
抽出したIPアドレスからのHTTPアクセス(TCPプロトコルのポート80)を許可するルールを、セキュリティグループに追加します。
countでIPアドレスの個数をカウントします。1セキュリティグループあたり、60ルール以内に収まるようにしています。
セキュリティグループへのルール追加はaws ec2 authorize-security-group-ingressで行います。
count=0 for IP in $IP_LIST; do if [ $count -lt 60 ]; then SG={セキュリティグループ2のID} elif [ $count -lt 120 ]; then SG={セキュリティグループ3のID} else SG={セキュリティグループ4のID} fi aws ec2 authorize-security-group-ingress --region {リージョン名} --group-id $SG --protocol tcp --port 80 --cidr $IP echo $IP (( count++ )) done
[6] CloudFrontの設定
外部からnginxサーバーにアクセスする際は、'test.example.com'のようにドメイン形式でアクセスできるようにします。そして、外部からのアクセスはCloudFrontがHTTPSのみ受け付けて、CloudFrontからEC2へHTTPへ流します。それぞれの関係を表すと次の通りです。
サブドメイン名(test.exmaple.com) <---> CloudFront <---> EC2のパブリック IPv4 DNS
[6-1] CloudFormationのテンプレート
[6-1-1] パラメータ
次の内容はユーザーが入力します。調べ方は後述します。
| パラメータ | 備考 |
|---|---|
| EC2インスタンスのパブリック IPv4 DNS | CloudFrontのOrigin Domain Nameに指定。 |
| Certificate ManagerのARN | CloudFrontのSSL Certificateに指定。 |
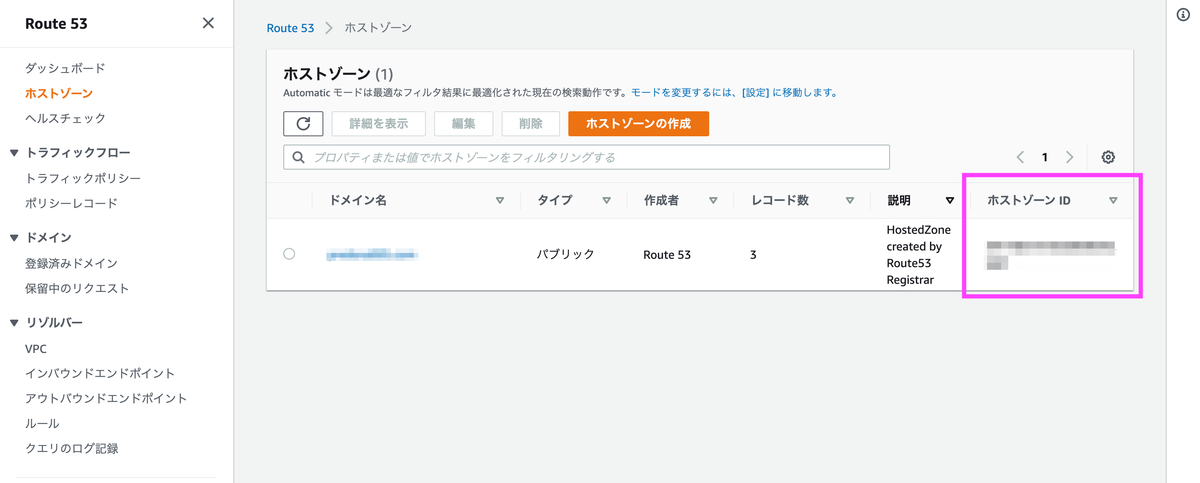
| ホストゾーン ID | ドメイン登録時に作成されたホストゾーン。 |
| サブドメイン名 | 任意。Route53で登録したドメインのサブドメイン。 |
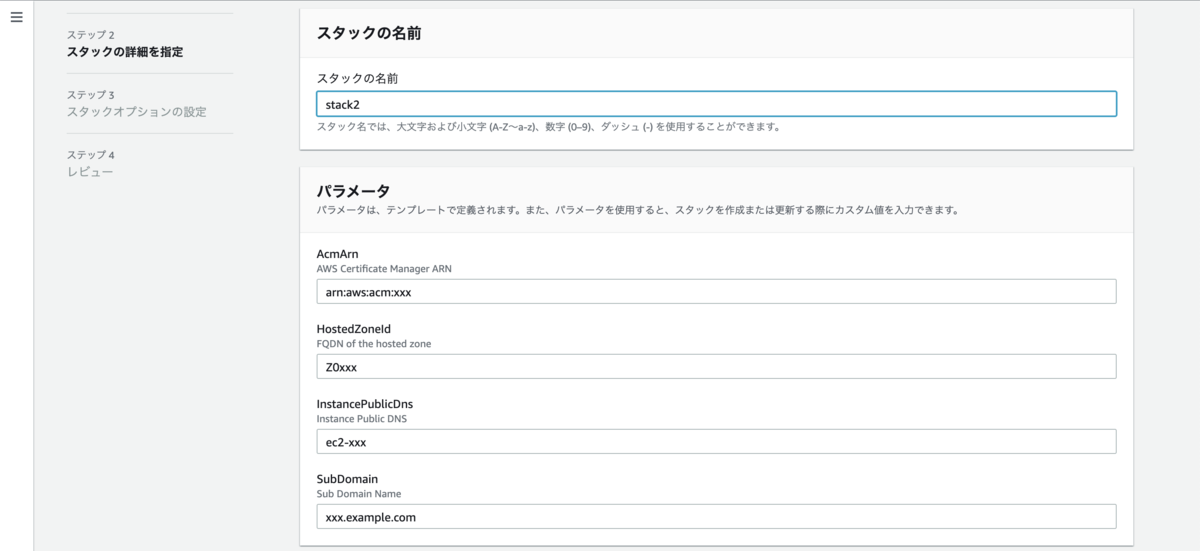
AWSTemplateFormatVersion: 2010-09-09 Description: >- AWS CloudFormation template for the nginx server. Parameters: # Instance InstancePublicDns: Description: Instance Public DNS Type: String Default: 'ec2-xxx' # Certificate ManagerのARN AcmArn: Description: AWS Certificate Manager ARN Type: String Default: 'arn:aws:acm:xxx' # ホストゾーンのID HostedZoneId: Description: FQDN of the hosted zone Type: String Default: 'Z0xxx' # サブドメイン名 SubDomain: Description: Sub Domain Name Type: String Default: 'xxx.example.com'
[6-1-2] CloudFront
CloudFrontは次の設定にします。
- Origin側(EC2)はHTTP Only
- Target側(CloudFront)はHTTPからHTTPSへリダイレクト
- Certificate Managerで発行した証明書を関連付け
- サブドメインを使用する
Resources: # CloudFront Distribution CloudFrontDistribution: Type: 'AWS::CloudFront::Distribution' Properties: DistributionConfig: Aliases: - !Ref SubDomain # インスタンス側はHTTP Onlyに設定 Origins: - CustomOriginConfig: OriginProtocolPolicy: http-only DomainName: !Ref InstancePublicDns Id: !Sub '${AWS::StackName}-cloudfront-distribution' DefaultCacheBehavior: # TargetOriginIdは Origins Idと一致していないとNG TargetOriginId: !Sub '${AWS::StackName}-cloudfront-distribution' ViewerProtocolPolicy: redirect-to-https # ForwardedValuesは公式非推奨(CachePolicyが推奨だが面倒) ForwardedValues: QueryString: false # SSL Certificate ViewerCertificate: SslSupportMethod: sni-only AcmCertificateArn: !Ref AcmArn MinimumProtocolVersion: TLSv1.2_2019 HttpVersion: http2 IPV6Enabled: true # Enabledは必須 Enabled: true Tags: - Key: Name Value: !Sub '${AWS::StackName}-cloudfront-dns'
MinimumProtocolVersionとHttpVersion, IPV6Enabledは任意のため指定しなくても問題はありません。
代替ドメイン名 (CNAME) を追加してカスタム URL を使用する - Amazon CloudFront
[6-1-3] Route53のエイリアスレコード
サブドメイン名とCloudFrontを関連付けします。CloudFront自体のドメイン名は'*.cloudfront.net'ですが、自分が決めたサブドメイン(www.example.com等)でCloudFrontにアクセスできるようにします。
# DNS Record DnsRecord: Type: 'AWS::Route53::RecordSet' Properties: HostedZoneId: !Ref HostedZoneId Comment: 'DNS name for CloudFront' Name: !Ref SubDomain Type: A AliasTarget: # AliasTargetのHostedZoneIdはホストゾーンのIDとは別 # CloudFrontの場合は固定 HostedZoneId: Z2FDTNDATAQYW2 DNSName: !GetAtt CloudFrontDistribution.DomainName
注意点はAliasTargetのHostedZoneIdです。CloudFrontを使用する場合は「Z2FDTNDATAQYW2」固定です。
AWS::Route53::RecordSetGroup AliasTarget - AWS CloudFormation
[6-2] スタックの作成
先程と同様にマネージメントコンソールから作成します。
[6-2-1] パラメータの調べ方
サブドメイン名は任意に決めます。それ以外のパラメータはマネージメントコンソールから確認します。
EC2インスタンスのパブリック IPv4 DNS
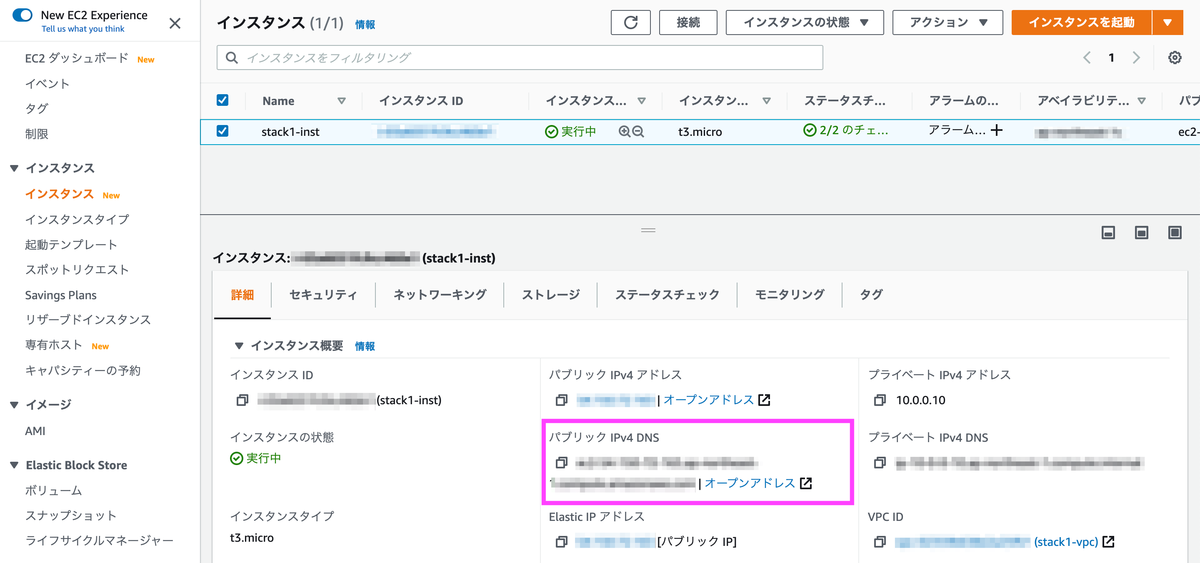
Certificate ManagerのARN
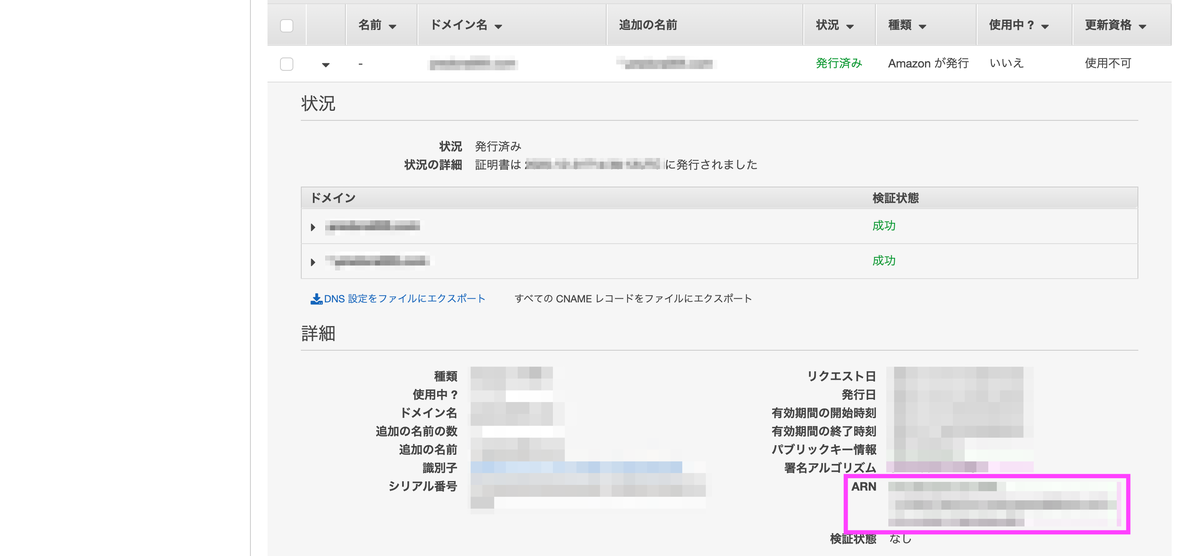
ホストゾーン ID
[6-2-2] スタックの作成
調べたパラメータを入力します。
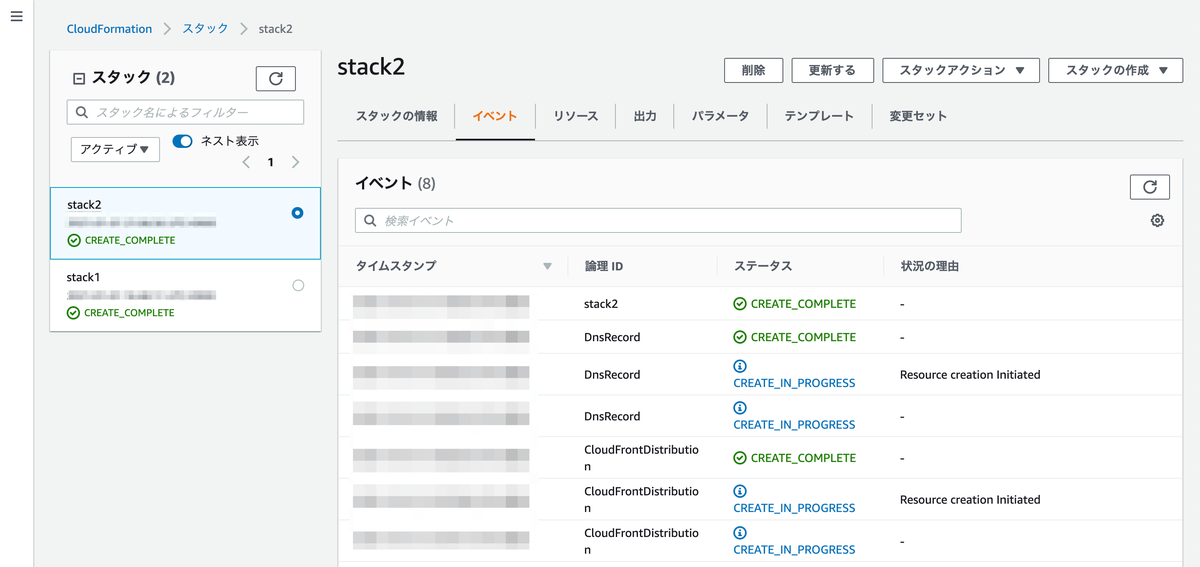
以降の項目はデフォルトのまま進めます。作成を開始して5分程度で作成が完了しました。
[7] 動作確認
設定したサブドメイン名(www.example.com等)でアクセスできるのかを確認します。
ブラウザのURL欄にサブドメイン名を入力します。正常に動作していれば、nginxのテストページが表示されます。
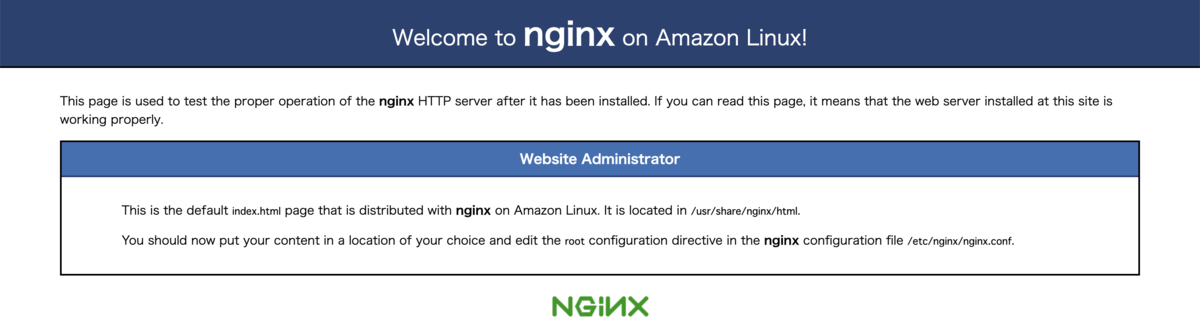
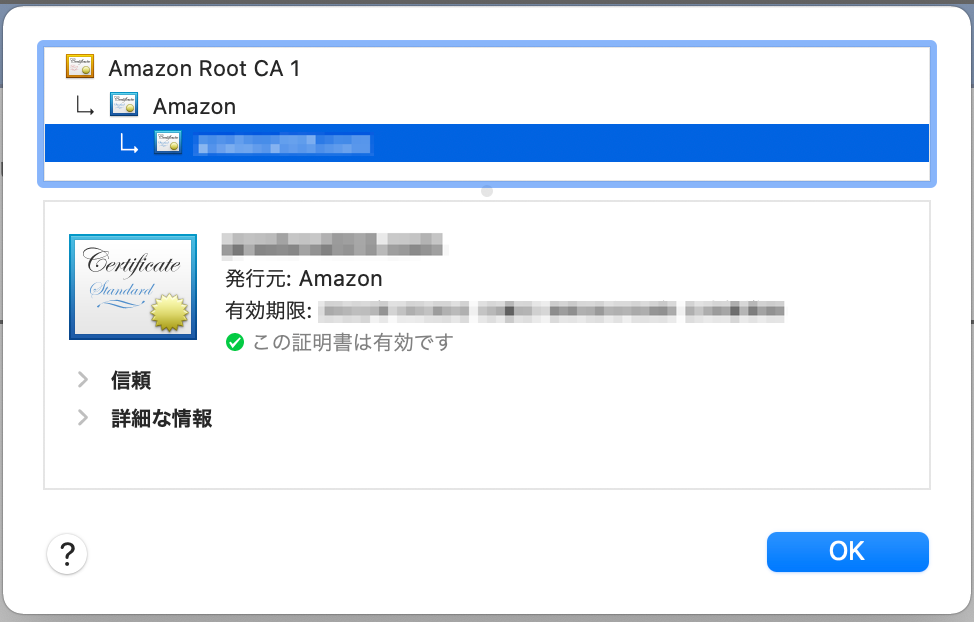
サーバ証明書を確認すると、有効になっていることが分かります。
EC2のIPアドレスを直に入力するとアクセスできないことが確認できます。セキュリティグループでCloudFrontからのアクセスのみ許可したため、EC2に直接アクセスできなくなっています。

[8] スタックの削除
作成したスタックを削除します。削除は新しいスタックから順に行います。
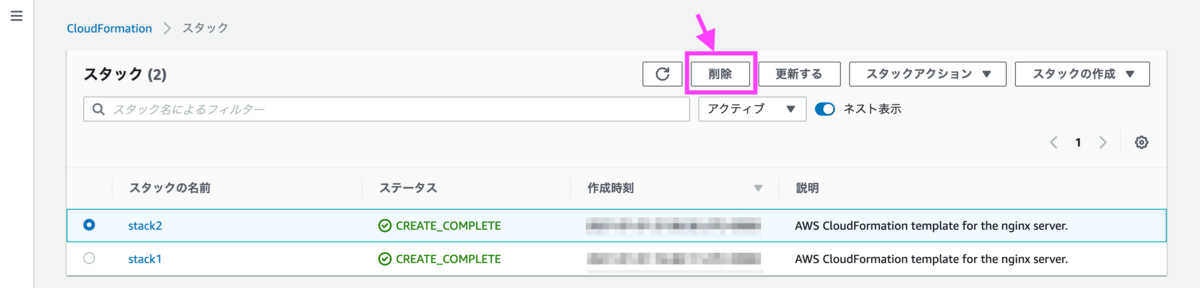
'CloudFrontDistribution'の削除は作成時と同様に5分程度かかります。
終わりに
複雑な構成では無いので手動で行えば、それほど時間はかかりません。しかし、CloudFormationでやろうとすると思いのほか時間がかかりました。
CloudFrontを使うことによって、CloudFormationのテンプレートが大分複雑になった感はあります。CloudFrontのIPをセキュリティグループに設定するのは、もう少し簡単になるといいなと思いました。
ただ、テンプレートを1回作成してしまえば何度でも使い回せるのはメリットです。だいぶ時間はかかりましたが、やってみて良かったなと思います。
ちなみに、HTTPS対応はCloudFrontだけが選択肢ではありません。ALBやNLBで代替可能な場合は検討してみるのもよいでしょう。また、EC2にSSHでログインして操作を行いましたが、Session Managerを使用する選択肢もアリです。
参考資料
AWSでWebサイトをHTTPS化 全パターンを整理してみました – ナレコムAWSレシピ
CloudFormationを使ってS3とCloudFrontの構成で静的Webサイトを構築する(Origin Access Identityは使わない) - Qiita
CloudFormation で OAI を使った CloudFront + S3 の静的コンテンツ配信インフラを作る | DevelopersIO
日本株の決算情報と財務情報をpythonでスクレイピングを使って取得する
前回の続きです。前回は複数銘柄のPERや配当利回り等をスクレイピングで取得しました。今回は決算情報をスクレイピングで取得します。
[1] 取得する情報
前回以前に引き続き「みんなの株式」から情報を取得させてもらいます。
[1-1] 決算情報と財務情報
今回取得するデータは期ごとの決算情報と財務情報です。以下は、JR東日本のものです。

[1-2] HTMLの中身
決算情報の表に着目すると、以下のHTMLになっていました。
<div class="md_box"> <table class="data_table md_table is_fix" data-table=""> <caption class="md_sub_index"><div class="title_box">決算情報</div></caption> <thead> <tr> <th class="w100p">決算期<p class="fsm">(決算発表日)</p></th> <th class="vamd">売上高</th> <th class="vamd">営業利益</th> <th class="vamd">経常利益</th> <th class="vamd">純利益</th> <th class="vamd">1株益</th> </tr> </thead> <tbody> <tr> <th class="vamd">2020年<span class="fwn fsm">3月期</span><p class="fsm">(2020/04/28)</p></th> <td class="num vamd">2,946,639</td> <td class="num vamd">380,841</td> <td class="num vamd">339,525</td> <td class="num vamd">198,428</td> <td class="num vamd">524.91</td> </tr> <tr> <th class="vamd">2019年<span class="fwn fsm">3月期</span><p class="fsm">(2019/04/25)</p></th> <td class="num vamd">3,002,043</td> <td class="num vamd">484,860</td> <td class="num vamd">443,267</td> <td class="num vamd">295,216</td> <td class="num vamd">773.26</td> </tr> ...(中略)... </tbody> </table> </div>
[2] スクレイピング
[2-1] 複数の表から目当ての表を特定する
table要素は決算情報だけでなく、財務情報など他にも複数の表にありました。まずは、table要素の中から決算情報の表を特定します。
caption要素のタイトルが格納されているので、caption要素の文字列が何かで判断します。
code = 9020 # JR東日本の証券コード # 指定URLのHTMLデータを取得 url = "https://minkabu.jp/stock/{0:d}/settlement".format(code) html = requests.get(url) # BeautifulSoupのHTMLパーサーを生成 soup = BeautifulSoup(html.content, "html.parser") # 全<table>要素を抽出 table_all = soup.find_all('table') # 決算情報の<table>要素を検索する。 fin_table1 = None for table in table_all: # <caption>要素を取得 caption = table.find('caption') if caption is None: continue # <caption>要素の文字列が目的のものと一致したら終了 if caption.text == '決算情報': fin_table1 = table break
[2-2] table要素からデータを取得する
table要素の中は、thead要素とtbody要素に分かれています。

まずは、thead要素のデータを抽出します。
# <table>要素内のヘッダ情報を取得する。 headers = [] thead_th = fin_table1.find('thead').find_all('th') for th in thead_th: headers.append(th.text)
次に、tbody要素のデータを抽出します。
# <table>要素内のデータを取得する。 rows = [] tbody_tr = fin_table1.find('tbody').find_all('tr') for tr in tbody_tr: # 1行内のデータを格納するためのリスト row = [] # <tr>要素内の<th>要素を取得する。 th = tr.find('th') row.append(th.text) # <tr>要素内の<td>要素を取得する。 td_all = tr.find_all('td') for td in td_all: row.append(td.text) # 1行のデータを格納したリストを、リストに格納 rows.append(row)
[2-3] DataFrameに格納する
抽出したデータをDataFrameに格納します。DataFrame作成後、先頭の列である決算期をインデックスに指定します。
# DataFrameを生成する df = pd.DataFrame(rows, columns=headers) # 先頭の列(決算期)をインデックスに指定する df = df.set_index(headers[0])
結果、以下のようなDataFrameが得られます。
| 売上高 | 営業利益 | 経常利益 | 純利益 | 1株益 | |
|---|---|---|---|---|---|
| 決算期(決算発表日) | |||||
| 2020年3月期(2020/04/28) | 2,946,639 | 380,841 | 339,525 | 198,428 | 524.91 |
| 2019年3月期(2019/04/25) | 3,002,043 | 484,860 | 443,267 | 295,216 | 773.26 |
| 2018年3月期(2018/04/27) | 2,950,156 | 481,295 | 439,969 | 288,957 | 749.20 |
| 2017年3月期(2017/04/28) | 2,880,802 | 466,309 | 412,311 | 277,925 | 713.96 |
[3] データの加工
[3-1] 不要なデータを削る
前回と同様に、数値のカンマや単位を削っていきます。まずは、数値からカンマを削除します。
# 数値のカンマを削除する関数 def trim_camma(x): # 2,946,639.3のようなカンマ区切り、小数点有りの数値か否か確認する comma_re = re.search(r"(\d{1,3}(,\d{3})*(\.\d+){0,1})", x) if comma_re: value = comma_re.group(1) value = value.replace(',', '') # カンマを削除 return np.float64(value) # 数値に変換 return x # 各列に対して、trim_cammaを適用する new_df = df.copy() for col in df.columns: new_df[col] = df[col].map(lambda v : trim_camma(v))
次に、決算期に付属している括弧の情報を削除します。削除する理由は、他の銘柄のデータを結合する際に不都合だからです。企業によって決算発表日は異なるため削除しておきます。
# 括弧内の文字列を削除する関数(括弧自体も削除する) def remove_inparentheses(s): # 文字列末尾の括弧を削除する result = re.search(r"(.+)(\(.+\))", s) if result: str = result.group(1) return str return s # インデックス(決算情報)の括弧内要素を削除する。 new_df.index.name = remove_inparentheses(new_df.index.name) new_df.index = new_df.index.map(lambda s : remove_inparentheses(s))
[3-2] 複数銘柄のデータを結合する
JR東日本以外の鉄道関係銘柄についても、同様に決算情報を取得し、DataFrameに格納します。
# 上記の処理 ...(中略)... # 名称を追加し、MultiIndexにする。 df['名称'] = name df = df.set_index('名称', append=True) # 全銘柄データ格納用のDataFrameに1銘柄のDataFrameを追加する if whole_df is None: whole_df = df else: whole_df = whole_df.append(df)
各銘柄の名称と決算期単位でデータを扱えるようにMultiIndexにしておきます。MultiIndexにすると次のような構造になります。
| 売上高 | 営業利益 | 経常利益 | ... | ||
|---|---|---|---|---|---|
| 名称 | 決算期 | ||||
| JR東日本 | 2020年3月期 | 2,946,639 | 380,841 | 339,525 | ... |
| 2019年3月期 | 3,002,043 | 484,860 | 443,267 | ... | |
| JR東海 | 2020年3月期 | 1,844,647 | 656,163 | 574,282 | ... |
| 2019年3月期 | 1,878,137 | 709,775 | 632,653 | ... |
全銘柄のデータをDataFrameに追加した後、以下の処理を行うことで、名称と決算期でソートされたデータになります。
# indexを入れ替えてソートする。 whole_df = whole_df.swaplevel('名称', '決算期').sort_index()
[3-3] 財務情報も取得する
決算情報と同様に、財務情報も取得します。caption要素の文字列が'決算情報'から'財務情報'に変わっただけで、処理内容は同じです。
| 1株純資産 | 総資産 | 純資産 | ... | ||
|---|---|---|---|---|---|
| 名称 | 決算期 | ||||
| JR東日本 | 2020年3月期 | 8,396.81 | 8,537,059 | 3,173,427 | ... |
| 2019年3月期 | 8,187.64 | 8,359,676 | 3,094,378 | ... | |
| JR東海 | 2020年3月期 | 18,796.61 | 9,603,126 | 3,872,103 | ... |
| 2019年3月期 | 17,029.44 | 9,295,745 | 3,508,065 | ... |
[3-4] ROAとROEを算出する
# ROAとROEを求める df['ROA'] = df['純利益'] / df['総資産'] * 100 df['ROE'] = df['純利益'] / df['純資産'] * 100
| ROA | ROE | ||
|---|---|---|---|
| 名称 | 決算期 | ||
| JR東日本 | 2020年3月期 | 2.32 | 6.25 |
| 2019年3月期 | 3.53 | 9.54 | |
| JR東海 | 2020年3月期 | 4.14 | 10.28 |
| 2019年3月期 | 4.72 | 12.51 |
終わりに
複数銘柄の決算情報を取得し、ROAとROEを求めることができました。次回は取得したデータを可視化します。
*1:Lorenzo CafaroによるPixabayからの画像
【読書】「フードテック革命」の感想 (2/2)

前回につづいて「フードテック革命」を紹介します。
[5] 食領域のGAFAは現れるのか
[5-1] キッチンOS
キッチンのソフトウェア化も今後期待されている分野の1つです。キッチンOSとは、キッチンを制御するソフトウェアのことです。
いまはネット上で多種多様なレシピを検索できるようになりました。動画でレシピを解説しているものも多く、昔に比べてだいぶ分かりやすくなりました。ですが、実際の調理はまだ人間が行っています。しかし、キッチンOSが組み込まれたIoT家電を使うと、調理までソフトウェアが行うようになります。
キッチンOSのメリットは、食材に応じて適切な調理を行うことができることです。人間では難しい火加減や時間の調整も正確に行えます。また、個人の好みに合わせた調整も行いやすいこともメリットです。
ゆくゆくは小売と合わさり、レシピの選定、食材の購入・配送、調理までが、一連の流れで行える未来が来るかもしれません。
[5-2] 食のデータ化
より重要なのが食のデータ化です。FANNG(FacebookやAmazon)が台頭した大きな理由が、個人データの収集と活用です。食にもデータ化の波が来るとされています。
今までは、誰がいつどこでどの食材を買ったかは分かっても、いつ何をどのように調理して食べたかまでは分かりませんでした。しかし、調理するのがキッチンOSであれば、誰がいつどの料理を食べたのかが分かります。
これらのデータを駆使すれば、個人に合わせたレシピを提案し食材を売るといったことも可能です。これはNetfrixのレコメンド機能や、Facebook広告の最適化に近いことです。食の世界でもマス向けから個別最適化が進む可能性があります。
さらに、個人の健康情報も組み合わせるとより大きな威力を発揮します。個人の体質や健康に合わせたレシピの提案も可能になります。いずれ、食業界のGAFAが出現しても不思議ではありません。
[6] 外食産業のアップデート
外食産業は新型コロナウィルスの影響を大きく受けました。ただ、コロナ以前から人手不足や労働生産性の低さといった構造的な課題は指摘されていました。
これらの課題を解決するフードテックとして注目されているのが「フードロボット」「自販機3.0」「デリバリー&ピックアップ」「ゴーストキッチン&シェア型セントラルキッチン」です。
[6-1] フードロボット
フードロボットと一言で言っても様々な種類があります。調理、盛り付け、店内の洗浄、配膳など支援範囲は広いです。
調理ロボットの代表例は、Creatorのハンバーガーを自動で作り上げるロボットです。顧客・店側双方にとってメリットがあります。1つめは、注文を受けた後で食材を切るところから調理を始めるので新鮮なこと。2つめが、顧客一人ひとりの細かい注文に応えられること。店側としては、調理をロボットに任せるため、人間を接客に注力でき、かつ、人件費も削減できます。実際に、このロボットが作ったハンバーガーは6ドルという低価格で提供されています*2。
それ以外のロボットには、パンを自動で製造するロボット、たこ焼きロボットがあります。
[6-2] 自販機3.0
ペットボトルや缶飲料の自販機は日本全国に普及しているが、筆者によればそれらは自販機1.0だと言います。自販機2.0は、カップ型コーヒーのような、砂糖やミルクなど調整できるものを指します。
そして、自販機3.0は小型の無人レストランとも言えるもの、例えば出来立てのラーメンやカスタマイズサラダを提供できるものを指します。当然、スマホアプリを介して注文が行われます。
代表例が米Chowboticsのカスタマイズサラダ製造マシン「Sally」です。
Sallyは空港、大学、病院など街中ほど食事環境が整っていない場所に設置されています。同様に、白Albertsのカスタムスムージー自販機は、有事の際のミール提供ツールとして活用されています。
新型コロナ禍で忙しい医療従事者にも栄養価の高い食事を提供可能ということで、海外では医療機関への設置が増えています。
[6-3] デリバリー&ピックアップ
Uber EatsやGrubhub, Deliveroo, DoorDash、日本では出前館など数多くの企業が参入している分野です。これらは自宅やオフィスまで配送するデリバリー型サービスです。
一方、ピックアップ型サービスは、料理が出来上がったタイミングでユーザーが決められた場所に取りに行く(ピックアップする)方式です。
いまはデリバリーの方が勢力を拡大しています。ただ、手数料が高く、飲食店側の負担が大きいという問題も出ています。新型コロナ禍の影響で、デリバリーはより拡大していくと思いますが、その過程で議論されていくでしょう。
[6-4] ゴーストキッチン&シェア型セントラルキッチン
いままで調理の集約化は、セントラルキッチンが主流でした。1箇所で集中的に調理し生産性を向上させ、かつ、品質を確保できるというメリットがありました。レストランチェーンなどが取ってきた方式です。
しかし、デリバリーが増えてきたり、調理自動化が進みつつある中で、シェア型セントラルキッチンが増えてきていました。シェア型キッチンはUber Eatsなどのデリバリーする側にも、料理を提供する店側にもメリットがあります。
デリバリーする側は、1件ずつ店舗を回る必要が無くなります。店側はデリバリー用の設備やキッチンを持つ必要が無くなります。
デリバリーがより普及していく中で、店舗を持たないデリバリー専門のレストランが出てきました。そうしたデリバリー専門レストランを束ねて調理を担うのが、ゴーストキッチンです。最近では、デリバリーする側がゴーストキッチンを構えるケースが増えています。
新型コロナウィルスの影響もあり、日本でもデリバリー専門の店が増えています。ゴーストキッチン、シェアキッチンは今後も増加していくでしょう。
終わりに
「フードテック革命」は読み応えのある本でした。まだまだ紹介できていない内容が沢山あります。昨今のフードテック事情を余すことなく盛り込もうとしている感がスゴく感じられました。
また、日本はフードテックで遅れを取っていることもあり、それを改善していきたいという思いも伝わってきました。いまは遅れを取っていてもポテンシャルはある、すでに動き出している企業もあるということが紹介されていました。
今後、フードテックの波は日本にも間違いなくやってくるでしょう。食はすべての人に関わる事柄なので、本書で最新のフードテック事情を知って損はないかと思います。