【AWS】pythonでS3のファイルを操作する手順(Boto3)
pythonのプログラムからS3を操作する手順をまとめました。ファイルのアップロード/ダウンロードなど、基本的な手順を書いています。
- [1] 前提条件
- [2] 準備
- [3] Boto3を使った操作の概略
- [4] Boto3を使った操作の詳細
- 終わりに
- 補足
- 出典
[1] 前提条件
AWS EC2環境で実行する際の手順です。ライブラリとして「AWS SDK for Python (Boto3)」を使用しています。
- EC2
- Amazon Linux2
- Python3
- Boto3
[2] 準備
[2-1] boto3のインストール
pipを使ってインストールします。
pip3 install boto3 --user
Quickstart — Boto3 Docs 1.17.102 documentation
[2-2] EC2にIAMロールを付与する
詳細は末尾の補足に記載しますが、IAMロールを作成し、以下のIAMポリシーを適用します。作成したIAMロールをEC2インスタンスに設定します。
IAMポリシー以下の権限を付与しています。
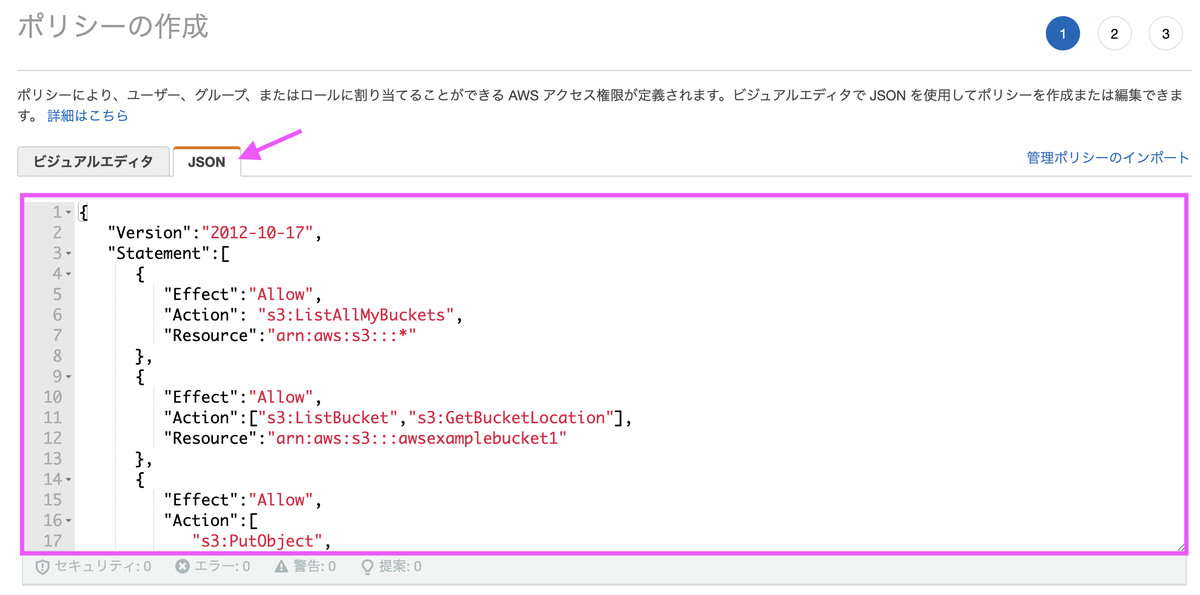
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ListAllBuckets", "Effect":"Allow", "Action": "s3:ListAllMyBuckets", "Resource":"arn:aws:s3:::*" }, { "Sid": "ListObjectsInBucket", "Effect": "Allow", "Action": ["s3:ListBucket","s3:GetBucketLocation"], "Resource": ["arn:aws:s3:::bucket-name"] }, { "Sid": "ObjectActions", "Effect": "Allow", "Action": ["s3:GetObject","s3:PutObject","s3:DeleteObject"], "Resource": ["arn:aws:s3:::bucket-name/*"] } ] }
IAMポリシーは下記資料を参考にしています。
- ユーザーポリシーの例 - Amazon Simple Storage Service
- Amazon S3: S3 バケットのオブジェクトへの読み取りおよび書き込みアクセスを許可する - AWS Identity and Access Management
[3] Boto3を使った操作の概略
やり方は色々とありますが、以下のソースコードで基本的なことは出来ます。
import boto3 BUCKET_NAME = 'bucket_name' # 全バケットを表示 s3 = boto3.resource('s3') for bucket in s3.buckets.all(): print(bucket.name) # バケット内の全オブジェクトを表示 bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.all() for obj in objects: print(obj.key) # オブジェクトをダウンロード bucket.download_file('input/file.txt', 'file.txt') # オブジェクトをアップロード bucket.upload_file('file.txt', 'output/file.txt') # オブジェクトを削除 s3.Object(BUCKET_NAME, 'output/file.txt').delete()
前半は全バケットの表示と、バケット内オブジェクトの表示です。後半はバケットからファイルをダウンロードし、別名でアップロードしたのち削除しています。
[4] Boto3を使った操作の詳細
boto3.resourceとboto3.client、2つの書き方があります。両者とも概ね同じことができるようになっています。
[4-1] 全バケットを表示
QuickStartに書いてあるソースコードです。非常に簡単です。
import boto3 s3 = boto3.resource('s3') for bucket in s3.buckets.all(): print(bucket.name)
Quickstart — Boto3 Docs 1.17.102 documentation
以下の書き方でも、同じことが実現できます。
s3 = boto3.client('s3') response = s3.list_buckets() print('Existing buckets:') for bucket in response['Buckets']: print(f' {bucket["Name"]}')
Amazon S3 buckets — Boto3 Docs 1.17.102 documentation
[4-2] バケット内のオブジェクトを表示
[4-2-1] 全オブジェクトを表示
boto3.resourceを使用した書き方は次の通りです。
BUCKET_NAME = 'bucket_name' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) for obj in bucket.objects.all(): print(obj.key)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientを使用した書き方は次の通りです。どちらを使用しても同じ出力結果が得られます。
BUCKET_NAME = 'bucket_name' s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME) for obj in response['Contents']: print(obj['Key'])
S3 — Boto3 Docs 1.17.102 documentation
例として以下のような出力結果が得られます。
# dir1/ # dir1/file1.txt # dir1/file2.txt # dir2/ # dir2/file3.csv # dir2/file4.txt # file5.csv
下記ファイル構成の場合の出力結果です。
bucket_name ├── dir1 │ ├── file1.txt │ └── file2.txt ├── dir2 │ ├── file3.csv │ └── file4.txt └── file5.csv
[4-2-2] Prefixに該当するオブジェクトを表示
指定したPrefixに該当するオブジェクトを表示することも可能です。
boto3.resourceを使用した書き方は以下の通りです。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.filter(Prefix='dir1') for obj in objects: print(obj.key) # dir1/ # dir1/file1.txt # dir1/file2.txt
boto3.clientを使用した書き方は以下の通りです。
s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME, Prefix='dir2') for obj in response['Contents']: print(obj['Key']) # dir2/ # dir2/file3.csv # dir2/file4.txt
[4-2-3] 階層化のオブジェクトのみ表示
Delimiterを使用することで階層直下のオブジェクトのみ表示します(再帰表示しない)。以下の例ではバケットの直下のみ表示しています。
boto3.resourceを使用した書き方は以下の通りです。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.filter(Delimiter='/') for obj in objects: print(obj.key) # file5.csv
boto3.clientを使用した書き方は以下の通りです。
s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME, Delimiter='/') for obj in response['Contents']: print(obj['Key']) # file5.csv
[4-2-4] Keyが1,000件以上になる場合の対処法
オブジェクト情報取得には制限があります。ワンオペレーションで取得できるKeyは最大で1,000件までです。1,000件を超えることが想定される場合、それを見越した処理が必要になります。
以下の処理では、テスト用に一度で5件までしか取得できないようにしています。MaxKeys=5です。Markerにキーを指定すると、そのキーの次のオブジェクトから取得します。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) marker = '' while True: # オブジェクト取得 objects = bucket.objects.filter(Marker=marker, MaxKeys=5) # オブジェクト表示 last_key = None for obj in objects: print(obj.key) last_key = obj.key # 最後のキーをMarkerにセットし次のオブジェクト取得を行う。 # オブジェクト取得が完了していたら終了。 if last_key is None: break else: marker = last_key
boto3.clientの場合、MarkerではなくContinuationTokenを使用します。
s3 = boto3.client('s3') # オブジェクト取得 response = s3.list_objects_v2(Bucket=BUCKET_NAME, MaxKeys=5) while True: # オブジェクト表示 for obj in response['Contents']: print(obj['Key']) # 'NextContinuationToken'が存在する場合は、次のデータ取得。 if 'NextContinuationToken' in response: token = response['NextContinuationToken'] response = s3.list_objects_v2(Bucket=BUCKET_NAME, MaxKeys=5, ContinuationToken=token) else: break
[4-2-5] resourceとclientで得られる情報の違い
上の例ではオブジェクトの「key」情報のみを取得していますが、他にも含まれる情報があります。そして、boto3.resourceとboto3.clientで持つ情報が若干異なります。
boto3.resourceで得られる情報は次の通りです。
# 〜〜〜(省略)〜〜〜 for obj in bucket.objects.all(): print(obj) # s3.ObjectSummary(bucket_name='bucket_name', key='dir1/') print(obj.bucket_name) # bucket_name print(obj.key) # dir1/ print(obj.e_tag) # "d41d8cd98f00b204e9800998ecf8427e" print(obj.last_modified) # 2021-06-30 09:28:47+00:00 print(obj.owner) # None print(obj.size) # 0 print(obj.storage_class) # STANDARD
boto3.clientで得られる情報は次の通りです。
# 〜〜〜(省略)〜〜〜 for obj in response['Contents']: print(obj) # {'Key': 'dir1/', # 'LastModified': datetime.datetime(2021, 6, 30, 9, 28, 47, tzinfo=tzlocal()), # 'ETag': '"d41d8cd98f00b204e9800998ecf8427e"', # 'Size': 0, # 'StorageClass': 'STANDARD'}
[4-3] バケットからファイルをダウンロード
[4-3-1] ファイルにダウンロード
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir1/file1.txt' FILE_NAME1 = 'file1.txt' s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).download_file(OBJECT_NAME1, FILE_NAME1)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME2 = 'dir1/file2.txt' FILE_NAME2 = 'file2.txt' s3 = boto3.client('s3') s3.download_file(BUCKET_NAME, OBJECT_NAME2, FILE_NAME2)
S3 — Boto3 Docs 1.17.103 documentation
[4-3-2] ファイルライクオブジェクトにダウンロード
ファイルを直接ダウンロードするだけで無く、ファイルライクオブジェクトへのダウンロードも可能です。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir2/file3.csv' FILE_NAME3 = 'file3.csv' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) with open(FILE_NAME3, 'wb') as f: bucket.download_fileobj(OBJECT_NAME3, f)
あまり使いどころが無いかもしれませんが、以下のように一時ファイルに出力する等が可能です。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir2/file3.csv' FILE_NAME3 = 'file3.csv' s3 = boto3.client('s3') with tempfile.NamedTemporaryFile(mode='wb') as f: s3.download_fileobj(BUCKET_NAME, OBJECT_NAME4, f) print(f.name) # /tmp/tmppjvqnyf5 print(f.tell) # <function BufferedWriter.tell at 0xffff90ff9290>
[4-4] バケットにファイルをアップロード
アップロードもダウンロードと同様の手順です。
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir3/file1.txt' FILE_NAME1 = 'file1.txt' OBJECT_NAME2 = 'dir3/file2.txt' FILE_NAME2 = 'file2.txt' s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).upload_file(FILE_NAME1, OBJECT_NAME1) s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) with open(FILE_NAME2, 'rb') as f: bucket.upload_fileobj(f, OBJECT_NAME2)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' FILE_NAME3 = 'file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' FILE_NAME4 = 'file4.txt' s3 = boto3.resource('s3') s3.meta.client.upload_file(FILE_NAME3, BUCKET_NAME, OBJECT_NAME3) s3 = boto3.client('s3') with open(FILE_NAME4, 'rb') as f: s3.upload_fileobj(f, BUCKET_NAME, OBJECT_NAME4)
S3 — Boto3 Docs 1.17.103 documentation
[4-5] バケットのオブジェクトを削除
[4-5-1] 単一オブジェクトの削除
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir3/file1.txt' s3 = boto3.resource('s3') s3.Object(BUCKET_NAME, OBJECT_NAME1).delete()
S3 — Boto3 Docs 1.17.105 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME2 = 'dir3/file2.txt' s3 = boto3.client('s3') s3.delete_object(Bucket=BUCKET_NAME, Key=OBJECT_NAME2)
S3 — Boto3 Docs 1.17.105 documentation
[4-5-2] 複数オブジェクトの削除
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) bucket.delete_objects( Delete={ 'Objects': [ {'Key': OBJECT_NAME3}, {'Key': OBJECT_NAME4} ] }, )
S3 — Boto3 Docs 1.17.105 documentation
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' s3 = boto3.client('s3') s3.delete_objects( Bucket=BUCKET_NAME, Delete={ 'Objects': [ {'Key': OBJECT_NAME3}, {'Key': OBJECT_NAME4} ] }, )
S3 — Boto3 Docs 1.17.105 documentation
終わりに
同じことをやるにも色々なやり方があり混乱しました。ですが、どの手順でも大きな差はありませんでした。手順自体も簡単なため、自分が使いやすいと思うものを使えばいいようです。
補足
[補足1] IAMロールをマネージメントコンソールで作成する手順
IAMロールを作成します。

ユースケースの選択で[S3]を選びます。
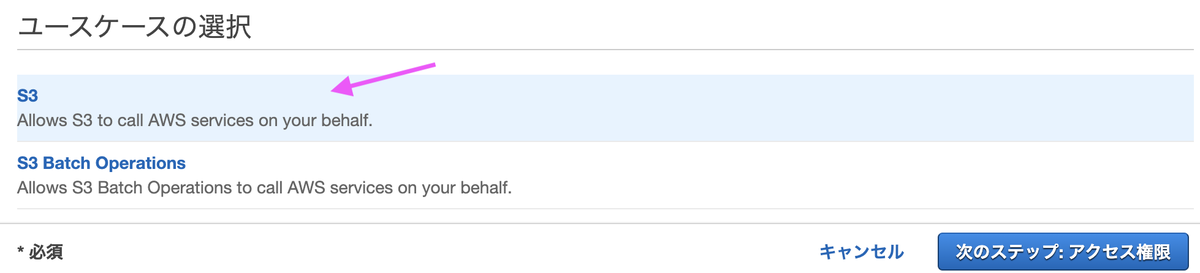
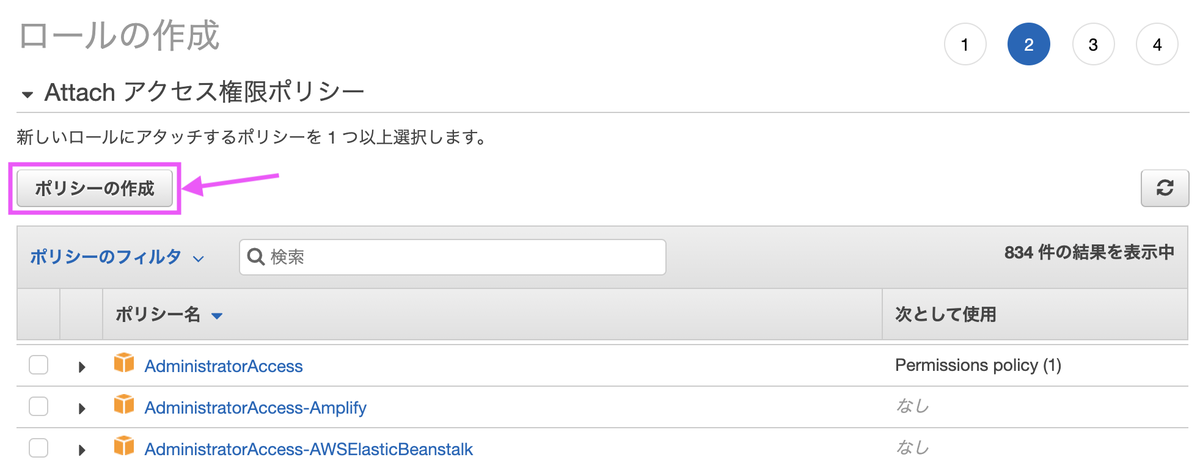
[ポリシーの作成]を選びます。
本文に記載したJSONを貼り付けます。バケット名はご自身のバケットの名称に置き換えます。
ポリシー名は任意の名称で構いません。

ロールの作成画面に戻ったら、作成したポリシーを割り当てます。更新ボタンを押してポリシー名を検索ボックスに入力すると、選択肢に出てきます。
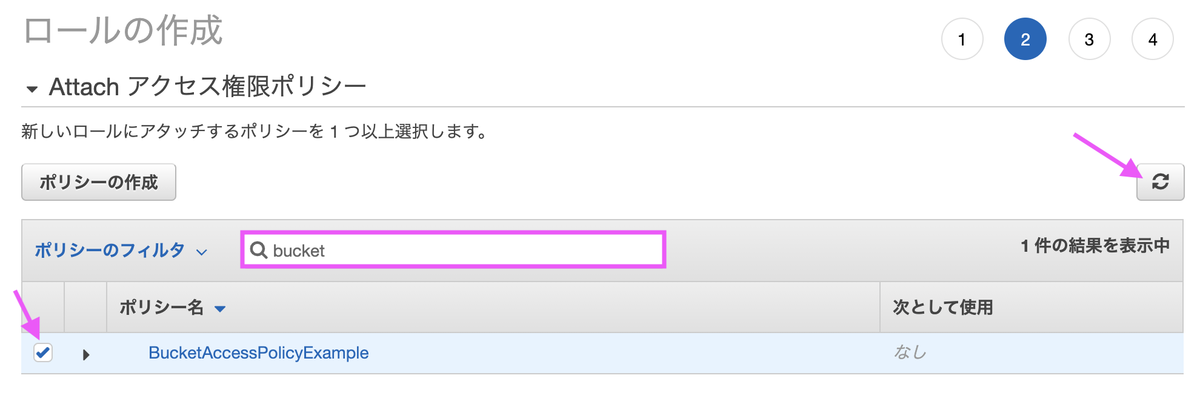
ロール名は任意の名称で構いません。

[補足2] IAMロールをCloudFormationで作成する場合
テンプレートファイルに以下の記述を追加します(Resourcesは元々書いてあるはずなので追加不要です)。長ったらしく感じますが「バケット名」以外は決まりきった書き方です。
Resources: # (...途中省略...) S3AccessRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "ec2.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" S3AccessPolicies: Type: AWS::IAM::Policy Properties: PolicyName: s3access PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - "s3:ListAllMyBuckets" - "s3:GetBucketLocation" Resource: "arn:aws:s3:::*" - Effect: Allow Action: - "s3:ListBucket" Resource: - "arn:aws:s3:::{バケット名}" - Effect: Allow Action: - "s3:GetObject" - "s3:PutObject" - "s3:DeleteObject" Resource: - "arn:aws:s3:::{バケット名}/*" Roles: - !Ref S3AccessRole S3AccessInstanceProfile: Type: AWS::IAM::InstanceProfile Properties: Path: "/" Roles: - !Ref S3AccessRole
追加した「S3AccessInstanceProfile」をEC2インスタンスと紐づければ終わりです。
# (...途中省略...) Instance: Type: AWS::EC2::Instance Properties: # (...途中省略...) IamInstanceProfile: !Ref S3AccessInstanceProfile
出典
アイキャッチはOpenClipart-VectorsによるPixabayからの画像
【読書】現代のビジネスパーソンがクラウゼヴィッツから学べることは何か
前記事に引き続き「戦略の世界史(上)」で印象に残ったところを紹介します。
https://predora005.hatenablog.com/entry/2021/07/07/190000predora005.hatenablog.com
ナポレオンの時代
ナポレオンといえばフランス革命で有名な人物です。フランス革命が起きた1700年代末は戦争の形が変わりつつありました。大きな変化は、国民軍の誕生です。それまでは騎士や傭兵が活躍していましたが、国民の徴兵・志願により軍隊が形成されました。騎士や傭兵などのプロに比べれば練度で劣るなど問題もあったようですが、大規模な軍隊となりました。
また、技術の発展により長距離移動が発達も合わさり、戦争が大規模化しました。それまでの陣取りを目的とした制限戦争から、国家同士の全面戦争へと変容しました。
クラウゼヴィッツの戦争論
クラウゼヴィッツは1800年代前半、ナポレオン戦争の時代に生きた人物です。「戦争論」という書籍で有名な人物です。クラウゼヴィッツはプロイセンの軍人でした。フランスとは対立する立場にありました。戦争論は主に40代の頃に執筆し、51歳で亡くなりました。
「戦争論」では戦争とはなにかという本質が描かれました。戦争の方法・戦術ではないため、時代を経ても廃れず後世においても影響を及ぼしました。
戦争の三要素
戦争は特異な三位一体を為していると、クラウゼヴィッツは考えました。三要素の相互作用によって戦争が起こるという考え方です。
- 原初的な暴力、憎悪、敵意
- 賭けの要素 (偶然性や蓋然性)
- 政策に対する従属性 (戦争は政策の手段)
摩擦という概念
三要素に加えてクラウゼヴィッツは「摩擦」という概念を取り入れました。戦争では予想できなかった無数の小さな出来事が起き、それらが重なることでまったく推測できなかった諸現象が引き起こされる。当初の見込みを下回り、目標のはるか手前までしか達しないのは常であるということです。
つまり実際の物事は、机上の計画通りには進まないということです。いま考えると当たり前な気もしますが、当時の軍事思想では明確化されていませんでした。摩擦という概念を取り入れたことは、軍事思想の発展への大きな寄与とされています。
戦略に意味はないのか?
計画通りに進まないのであれば、戦略に意味はないのかと考えてしまいます。しかし、作戦の明確な計画を立てることは重要だとクラウゼヴィッツは述べました。そして、その計画を実行に移したら修正すべきではないと説きました。その理由として3つの要因を挙げています。
1つめは、何もかもが予測できないわけではないからです。予測不要なものもありますが、予測できるものもあります。天候や奇策は予測できませんが、敵国の状況や兵力や地形といったことは事前に予測できます。予測可能な要素をもとに、確率的に考えることはできるということです。
2つめは、情報は不確かなものだからです。戦争中に得られる情報は不確実なものが多く、悲観的な方向に偏りがちである。当初の計画に自身を失いかねないが、自らの判断を信じた方がよいということです。これは現代のような通信手段がなかった当時の時代背景が影響しています。
3つめは、どちらの陣営も摩擦の影響を受けるから。敵も摩擦の影響により、当初の計画通りに行かない場合がある。どちらがより摩擦に対処し克服できるかが、勝敗に寄与するということです。
規模は大事
ここまで戦略は重要という話をしてきました。ですがクラウゼヴィッツは、勝利のために最も頼りになるのは「数の優位性」だと説いています。「二倍の戦力はすぐれた指揮官の能力に匹敵しうる」と述べました。これは指揮官の戦略が重要であることを示していますが、それ以上に戦力が重要であるということです。
ただし、両陣営の個々の戦力に大きな差がないことが前提です。ハイテク兵器が使われる近代の戦争では、必ずしも当てはまらないでしょう。
勝利の限界点
それ以上攻撃を続けると、優位だった形成が逆転する時点を意味します。この言葉の意味は、ナポレオンのロシア遠征の事例から窺い知れます。
ナポレオン軍はロシアに侵攻し、モスクワを制圧しました。ですが、ロシア軍は国の存続のためにモスクワを犠牲にすることに決めていました。後に各所で火がおこり、町の三分の二が焼けました。ナポレオン軍は期待していた食糧が得られず、加えてロシアの冬の寒さに耐えられませんでした。結果フランスへ退却することになりましたが、帰路は困難を伴い多くの犠牲が出ました。
現代人がクラウゼヴィッツから学べることは何か
私個人が、クラウゼヴィッツの戦略論から学べると思った点は2つあります。
1つめは、予測できないことへの対応力です。「摩擦」の項で物事は計画通りに進まないとされていますが、それはビジネスの世界でも同じです。事前に勝率の高いだろう計画を立て、実際に動きだしたら状況を見つつ対応する点は変わらないと思いました。違うと感じたのは、情報の正確さと早さです。1800年代では情報は不確かなものとされていましたが、現代では情報収集と有効活用が必要でしょう。
2つめは、戦略だけでも規模だけでもダメということです。私が改めて言うまでもなく、昔からの大企業が新興企業に負けること、存在が消えることは珍しくありません。GAFAMは創業されてから50年も経っていません。一時的には規模で勝てても、長期的に勝てるわけではありません。
一方、戦略だけでも勝てません。勝ちの定義にも依りますが、数人のスタートアップ企業がGAFAMと真っ向勝負できるかというと勝率はかなり低いでしょう。特定の領域で勝つことは可能だと思いますが、規模が重要というのも確かなことです。
出典
- アイキャッチはwal_172619によるPixabayからの画像
【読書】孫子が読み継がれる理由
前記事に引き続き「戦略の世界史(上)」で印象に残ったところを紹介します。
https://predora005.hatenablog.com/entry/2021/07/05/190000predora005.hatenablog.com
戦略と策略の違い
goo辞書によれば、策略は相手を貶めるネガティブイメージがあります。それは古代ローマにおいても同様でした。
戦略とは「1 戦争に勝つための総合的・長期的な計略。」「2 組織などを運営していくについて、将来を見通しての方策。」
策略とは「自分の目的を達成するために相手をおとしいれるはかりごと。計略。」
しかしながら、策略にも批判に該当しないものがあるとされていました。現代でも、人のためになる嘘なら許されるという考え方もありますね。古代ローマ人の歴史家ウァレリウス・マクシムスによれば、次の6項が該当します。
- 士気を高めるための「健全な嘘」
- 内部から敵をおとしいれるニセ亡命者
- 包囲している側の士気をくじくために包囲されている側が用いる心理的策略
- 自軍が敵の一軍と対峙していると見せかけておいて、敵の別の一軍を二倍の戦力で攻撃する計略
- 敵を混乱させておいて奇襲をしかける作戦
- 自国の都市を包囲しようとしている敵国の都市を包囲する奇策
ローレンス・フリードマン. 戦略の世界史(上) 戦争・政治・ビジネス (戦略の世界史 戦争・政治・ビジネス) (Japanese Edition) (Kindle の位置No.1365-1370). Kindle 版. より抜粋
古代ローマでは、「戦略」「策略」は戦争と結びつけて考えられていました。自国の利益になるなら許されるという考え方でした。一方、現代では許されませんね。現代では戦争に直接関わる人は少ないです。古代と現代とで「戦略」に対するイメージは異なるということです。
孫子が読み継がれる理由
孫子は紀元前500年ごろに中国で書かれた兵法書です。だいぶ古い本ですが現代でも参考になると言われています。著名な起業家が参考にしたと言われていますし、孫子を紹介する記事や書籍も多く目にします。
孫子の根底にあるテーマは「戦わずに敵を屈服させる」ことにあります。最も効果的なところで力を使う策略の名手たれと述べています。
最上の戦い方は「謀を伐つ(敵の計略を未然に防ぐこと」。次に「交(敵と連合国との外交関係)を絶つこと」。次が「兵(敵の軍)を攻撃すること」。最も稚劣なのは「敵の城を包囲すること」としています。いかに戦わずして有利な状況を作るか、を重要視していますね。
悪い例として、危険な指揮官の典型例も5つ挙げています。
- 決死の覚悟ばかりで思慮に欠ける者
- 生き延びることしか考えていない、勇気に欠ける者
- 怒りっぽく短気な者
- 名誉を重んじる清廉潔白な者
- 人情深く兵士をいたわる者
ローレンス・フリードマン. 戦略の世界史(上) 戦争・政治・ビジネス (戦略の世界史 戦争・政治・ビジネス) (Japanese Edition) (Kindle の位置No.1419-1421). Kindle 版.
5.は一見良さそうに見えますが、兵士の世話に煩い本分を見失うということです。これは現代の指揮官にも当てはまると思いました。
孫子は軍事手法の戦術を書いた本でありません。もし具体的な戦術を示した本だったなら、現代には語り継がれていなかったでしょう。紀元前500年と現代ではあまりにも時代背景が異なりますから、現代ではまったく役に立たなかったでしょう。
当時、孫子を学ぶことはいいこと尽くめだったように思います。しかし、敵も孫子を学んでいた場合、相手も同じことをしてくるため優位性は失われます。これは現代ビジネスでも同じですね。一時的な優位を築いても、競合が同じ情報・技術を得れば優位性が無くなるというのはよくあることです。
策略の難しさ
紀元前においては、策略は必要なものとされていました。しかし、実際に策略を用いることには困難が伴いました。
自分の支配下にある人を騙すことは比較的簡単です。自分も相手を理解しており、相手も自分のことを信頼する傾向が強いためです。しかし、味方を騙す行為は避難の対象になります。一方、敵を騙すことは容認されがちです。ですが、敵を騙すほうが味方を騙すよりも難しいです。
また、ひとたび策略家という評判が絶つと警戒されることになります。そうすると、策略を成功する可能性は低くなります。
そのため、策略は小規模かつ個人的な形で用いた場合に最も効果を発揮しました。大規模なケースでは、一時的かつ限定的な優位を築くのに留まりました。やがて戦争が大規模化するに伴い、策略よりも武力の方が重視されるようになっていきます。
終わりに
策略は賛否両論ありますし、現代では法律などのルールを守らなければなりません。しかし何も考えず力で正面突破するのではなく、相手を知り策を練ることは現代でも重要ですね。そういった意味で、現代でも孫子から学ぶことが多くあるということでしょう。
出典
【読書】戦略は人類よりも前から存在した
「戦略の世界史(上)」という本を読みました。「戦略」の本ですが、皆さんが想像する意味とは違うと思います。私が最初に思い浮かべたのは、経営戦略やマーケティング戦略、軍事戦略です。後半では紹介されていますが、始まりはチンパンジーからでした。
チンパンジーはピンと来ないかもしれませんが、紀元前以前の人類であれば歴史の授業で学んだことがあるはずです。昔の人類には、戦争はあっても経営なんてものは存在しませんでした。戦争でもハイテク兵器は当然存在しておらず、剣や弓で戦っていました。そんな時代から戦略は存在していました。
「戦略の世界史(上)」は歴史の本です。神話や哲学的な要素も含まれます。戦略は主に政治や戦争と関連してきました。なので、人類がどういう風に政治や戦争を捉えてきたのか知るのには良い本です。
決して読みやすい本ではありませんでした。読みやすい文章とは言えず、読み終えるのには骨が折れました。しかし面白い内容ではありましたので、いくつか印象に残ったところを書き残していきます。
政治の起源はチンパンジーまでさかのぼる
チンパンジーにも社会が存在します。アルファオスを頂点としたコロニーで行動します。コロニーには階層序列があるわけですが、肉体的な力関係だけで築かれるわけではありません。
アルファオスは権力闘争によって交代します。世襲制であったり、同じオスが亡くなるまで保持するわけではありません。権力闘争では、欺き行為や同盟関係といった戦略が用いられていました。
挑発や威嚇により自分の方が強いように見せたり、別のオスと手を組んでアルファオスを蹴落とすといった行動が行われました。現代の戦略に比べれば原始的ですが、戦略の類はチンパンジーの時代からすでに存在していたわけです。
また、別のコロニーとの争いでも戦略が用いられていました。例えば、縄張り境界のパトロールです。チンパンジーには力関係を見きわめる力がありました。
パトロール中に弱そうな標的を見つけた場合は、集団かつ不意打ちで攻撃していました。一方、少数でのパトロールで、敵の大集団に出くわすと逃げていました。同数の集団に対しては、戦いを避けて視覚的・聴覚的な示威行動を示していました。
本書では以下のようにまとめられています。
これらの特徴は、紛争を招く社会構造の中から生じている。戦略的な行動には、強烈な印象を与えたり、欺いたりすることで、敵あるいは味方になる可能性がある他者の行動を左右できるように、そうした相手の際立った特性を認識し、その置かれた状況をおもんぱかる力が必要だ。最も効果的な戦略は、暴力だけに頼るのではなく(暴力は優位性を誇示したり、攻撃性を表したりする手段として使えるが)、同盟関係を組む能力を生かすことである。
ローレンス・フリードマン. 戦略の世界史(上) 戦争・政治・ビジネス (戦略の世界史 戦争・政治・ビジネス) (Japanese Edition) (Kindle の位置No.477-481). Kindle 版.
古代ギリシャにおける戦略
人間の戦略は、古代ギリシャ時代には存在していました。古代ギリシャより前は、神々に忠実に従うことこそ最良の戦略とされていました。しかし、紀元前5世紀にギリシャ啓蒙が起きた時代には変わりました。物事は神々ではなく人間の行動と決断によって動くという考え方が生まれました。
このころには国家が誕生していました。国家間の戦争はそれまでの戦争よりも複雑化しており、ひとりの英雄によって勝利できる規模ではなくなりました。協調や計画が必要になり、優れた指導力を発揮できる将が求められました。
これは戦闘面に限った話でなく、他国との同盟など政治面も含みます。戦闘面で優れていたとしても、周りの国家がすべて敵となれば数の暴力に負けてしまいます。この頃は原始的な戦い方でり、現代よりも数がより重要だった背景もあります。
哲学者の登場
政治で影響力を発揮するには弁舌が必要でした。優れた戦略を策定しても、それを言葉で明確に示せなければ人々を説得できないからです。肉体的な力ではなく、言葉がより力を持ち始めたのがこの時代です。
紀元前4世紀ごろには政治的な弁論術ではなく、倫理的な真理を追求する哲学が力を持ち始めました。ソクラテスやプラトンと言えば、知っている方も多いでしょう。この時代に、哲学という専門的職業分野が確立されました。
終わりに
現代と共通する点が2つありましたね。1つめは、単純な力技では数には勝てないこと。周りを味方に付ける、勝機を伺い不利な戦いを避ける点は同じですね。
2つめは、言葉が重要ということ。仕事で言えば、上司の言葉に説得力がなければ部下は十分な成果を出すことができませんね。言う通りやれというだけの上司もイヤですし、単純に説明下手なのもイヤですよね。自分も気をつけなければと思いました。
出典
男女の失業率で独立性検定をやってみる
「2020年 労働力調査:e-Stat 政府統計の窓口」によれば、日本の失業率は「2.8%」です。
性別でみると男性が「3.0%」、女性が「2.5%」で差があります。今回はこの差が統計的に有意なもの(性別が失業率に影響するか)か検定しました。
仮説を立てる
帰無仮説を「失業率と性別は独立(無関係)」とします。なので、対立仮説は「失業率と性別は独立では無い(関係がある)」となります。
有意水準は5%とします。有意水準とは、誤って帰無仮説を棄却する確率です。この場合、帰無仮説「失業率と性別は独立(無関係)」を誤って棄却する確率が5%ということです。
クロス集計表
まずは、調査結果を表にまとめます。割合(失業率)ではなく、失業者・非失業者数を表にします。

理論度数表
「性別による失業率の差は無い」と仮定した場合の理論値を算出します。性別による差が無ければ、割合(失業率)は男女で同じになるはずです。
理論値は以下の式で求めます。

一例を示すと次の通りです。fi, fjは対応する行・列の合計値、nは全体の合計です。

他も同様に計算を行うと以下の表ができます。

相対誤差
続いて、相対誤差を表にします。相対誤差は以下の式で求めます。

一例を示すと次の通りです。fi・fj/nは理論値のため、既に求めた理論値を使います。

他も同様に計算を行うと以下の表ができます。

相対誤差の合計(表の右下)である「16389.945」がカイ二乗値になります。

この値と、有意水準5%のカイ二乗値とを比較して、帰無仮説が棄却されるか/されないかが決まります。
カイ二乗値
クロス集計表は2x2です。自由度は(行数-1)x(列数-1)なので、今回の自由度は1となります。
有意水準5%、自由度1のカイ二乗値は「3.841」です。ExcelやNumbersでは「CHIINV」関数で求めることができます。
結論は?
「16389.9 > 3.841」なので、帰無仮説「失業率と性別は独立(無関係)」は棄却されます。
つまり「失業率と性別とは関係がある」と言えます。
考えてみれば、当然の結果と言えます。男女それぞれ約3,000万人ほど集計して0.5%(約15万人分)差があるので、性別による影響があると想定できます。
女性の失業率が低い理由
結論わかりませんが、一般的には「女性の方が非正規でも良し(やむ無し)とする」という理由が挙げられています。
私は、夫婦のうち奥さんが共働きを断念するケースが多いからでもあると考えています。日本の失業者・労働力人口の定義では、就業を諦めた人を含みません。
【労働力人口】5歳以上の人口のうち,「就業者」と「完全失業者」を合わせたもの
【完全失業者】次の3つの条件を満たす者
1. 仕事がなくて調査週間中に少しも仕事をしなかった(就業者ではない。)。
2. 仕事があればすぐ就くことができる。
3. 調査週間中に,仕事を探す活動や事業を始める準備をしていた(過去の求職活動の結果を待っている場合を含む。)。
引用元:統計局ホームページ/労働力調査 用語の解説
共働きしたいけど不景気や家庭の事情で、奥さんが就業を断念するケースが多いのではないかと。そもそも、お子さんがいながら共働きする家庭はいつもすごいなと思います。
終わりに
身近なデータで独立性検定をやってみました。そんなに難しいことはやっていないのですが、慣れていないと思った以上に大変なものでした。
出典
アイキャッチはMediamodifierによるPixabayからの画像
参考文献
平均身長と体重から母平均と母分散の検定を復習する
だいぶ以前に読んだ「完全独習 統計学入門」の内容を思い出しがてら、記事を書きました。
小学生や中学生の頃、年に何回か身体測定をしていた記憶があります。小さい頃は身長も体重もどんどん変わっていくため、一喜一憂していました。
大人になってからも毎年の健康診断で測定しますが、大きく変わることはもう無いので子供の頃のようなワクワク感はありませんね。
毎年、全国の学校で測定したデータを用いて、各年齢の平均身長と体重が算出されています。詳しいデータは「政府統計 e-Stat」から見ることができます。
2019年度のデータを参照して「完全独習 統計学入門」の内容を復習しました。
17歳の平均身長と体重
「2019年度 学校保健統計調査」によれば、17歳の平均身長と体重は次の通りです。
男性:身長 170.6 cm、体重 62.5 kg
女性:身長 157.9 cm、体重 53.0 kg
この数字はあくまで平均です。当たり前ですが、全員がこの身長・体重というわけではありません。人によって異なり、全体としてはバラ付きがあります。
身長や体重は正規分布に従うと言われています。学校保健統計調査には、平均だけでなく標準偏差も載っています。平均と標準偏差を元に以下のようなグラフで表せます。

縦軸は確率密度、横軸は身長です。平均身長を中心に左右に分布しています。
全高校生の平均ではない
この平均身長と体重は、すべての高校生の平均ではありません。全高校生の身長と体重を測定するのは大変なため、全国の高校から抜粋して調査を実施します。
身長・体重の調査対象人数は126,900人で、全体の5.2%を抽出しています。詳しくは下記リンク先に載っています。
学校保健統計調査-令和元年度(確定値)の結果の概要:文部科学省
本当の平均身長は?
t分布を用いて、17歳男性の本当の平均身長を求めてみます。

(sは不偏分散ではありません)
統計量Tの式に、実際の数値を当てはめてみます。標本数は126,900人です。男女の比率は分からないので、ここでは半々と仮定します。男女とも63,450人とします。

自由度は標本数から1引いて63,459です。自由度63,459のときのt分布の95%信頼区間を確認すると「1.960」です。よって、以下の式を解けばよいことになります。

この式から「本当の平均μ」は「170.55〜170.65 cm」の範囲に95%含まれます。
これは、ほとんど平均と差がありません。0.05cmなんてほぼ0に等しく、測定誤差の方が0.05cmよりも大きそうです。
測定した人数が十分多いので、全体の5.2%から抽出した平均身長でも十分と言えるわけです。
ちなみに、その他の平均についても95%信頼区間を求めると次の通りです。
- 17歳男性 平均身長 170.55〜170.65 cm
- 17歳男性 平均体重 62.42〜62.58 kg
- 17歳女性 平均身長 157.86〜157.93 cm
- 17歳女性 平均体重 52.94〜53.06 kg
本当の標準偏差は?

統計量Wの式に、実際の数値を当てはめます。

自由度63,459のときのカイ二乗分布の95%信頼区間を確認すると、相対度数97.5%が「62,753」、相対度数2.5%が「63,447」です。よって、以下の式を解けばよいことになります。

この式から「本当の母標準偏差σ」は「5.870〜5.903」の範囲に95%含まれます。
標準偏差も平均と同じで、ほとんど差がありませんでした。つまり、標準偏差5.87は十分信頼できる数値と言っていいでしょう。
終わりに
「完全独習 統計学入門」は読みやすい本でした。筆者が超入門書と謳っている通り、統計が苦手そうな人にも分かりやすいよう工夫されています。
久々に読みましたが、あまり覚えていませんでした。しばらく使わないと忘れてしまうものですね。
出典
アイキャッチの画像はTumisuによるPixabayからの画像
参考文献
文章を書ける人は仕事ができる
ここで言う「文章を書ける人」とは、わかりやすい文章を書ける人のことです。人に伝わる文章が書けるかどうかです。
「仕事ができる」は定義が難しいですが、上司の指示を正しく理解して作業を行い、結果を正確に報告できる人と考えてください。
私はSEであり、文章を書く専門家ではありません。ですが、毎日文章は書いています。メールや仕様書や手順書など様々です。他の人が書いた文章も毎日のように目にしますが、書く人によって文章のわかりやすさは違います。
何を言いたいのか文章から読み取れず、何度もメールやチャットをすることになったり、口頭で聞くことになったりすることはよくあります。
わかりやすい文章を書けるか否かは、仕事のできる/できないに大いに関係します。文章を書けるにも関わらず仕事のできが悪い人には、いままで会った記憶がありません。仕事のできと一言に言っても、人それぞれ得意不得意があります。あくまで、トータルで見た場合の評価です。
文章を書く仕事の割合は?
そもそも文章を書く仕事でなければ関係ないと反論されれば、その通りです。いわゆるブルーカラーの仕事に携わっている方は、文章を書く機会がないかもしれません。正確な数字は分かりませんが、ホワイトカラーに従事する人は少なく見積もると4人に1人くらいです。なので、この話は4人に3人には関係のない話かもしれません。
それでも日本の就業者数が約6,000万人なので、4人に1人でも約1,500万人です。結構な人が文章を書くであろう仕事に携わっています。
文章のわかりやすさと仕事の関係
なぜ文章と仕事のできに関係があるのか。それは、文章を書ける人は論理的に考えられる人だからです。一見、文章と論理は関係ないように思えますが、わかりやすい文章を書くためには論理が必須です。
企業のリストラが進み、日本の終身雇用制度は崩壊した。能力主義の浸透は、若手にとっては大きなチャンスでもある。若い世代の前途は明るい。学生たちは自信を持って就職活動に励んでほしい。
古賀史健. 20歳の自分に受けさせたい文章講義 (Japanese Edition) (Kindle の位置No.628-629). Kindle 版.
以前、紹介させていただいた「20歳の自分に受けさせたい文章講義 」に載っていた例文です。一見それっぽいことを書いているように見えるものの、論理が破綻しています。それぞれの文の意味がつながっていません。
文章では表情も分かりませんし、身振り手振りや雰囲気で伝えることもできません。文章は書いてあることがすべてです。論理立てて不足なく書かないと、意図が正確に伝わりません。なので、わかりやすい文章を書くためには論理が必要なのです。
ホワイトカラーの仕事≒文章を書く仕事においては、論理的思考力を持っていた方が滞りなく物事を進められます。身体能力や特殊技術が関わる仕事であれば話は別ですし、組織におけるその人の役割にもよるでしょう。しかし総じて言えば、論理が組み立てられる方が仕事ができると言えます。
文章を書けないとダメか
文章を書くのは苦手だけど、仕事ができている人も数多くいます。文章は書けないけど会話は得意であったり、特定の作業がものすごく得意な人など、挙げれば様々です。なので、文章が書けない=仕事ができないとはならないです。その逆で、文章は書けるのに仕事ができない人は少ないという話です。
終わりに
私はもともと、文章を書くのが得意ではありませんでした。新入社員の頃は先輩に文章を添削してもらっていましたが、毎回真っ赤になって返ってきました。今では平均程度には書けるようになっていると思います。
私は文章が書けるようになって、仕事がラクになりました。毎回20分以上かけていたメールの返信も時間がかからなくなり、毎回大量のダメ出しをされていた文書作成も指摘が少なくなりました。
日々仕事で文章を書く人は、文章の書き方を勉強することをオススメします。勉強するのは面倒ですし、多少の時間はかかります。ですが、毎週何10時間もする仕事が少しでもラクになるなら、すぐに元は取れると思います。
出典
- アイキャッチはFree-PhotosによるPixabayからの画像
[補足] ホワイトカラー就業者の算出方法
就業者数=6,664万人に対して、明らかにホワイトカラーと判断できるのは1,493万人(管理的職業従事者と事務従事者)。よって少なくとも、就業者全体の22.4%以上はホワイトカラーと言えます。
労働力調査 基本集計 全都道府県 結果原表 全国 就業者 II-5 産業,職業別就業者数 年度次 2020年度 | ファイル | 統計データを探す | 政府統計の総合窓口