【機械学習】Kaggle Titanic competitionのチュートリアルが終わったあとにやったこと

Kaggle Titanic competitionのチュートリアルが終わったあとにやったこと*1
※ 2020/03/11にQrunchで書いた記事を移行しました。
チュートリアルを終え、予測結果の提出方法までは分かりました。 以降は、予測精度の向上を目指しました。
結果として、スコア(正解率)=0.80382まで達することが出来ました。 03/10時点では、1235/16508位でした。
ぶっちゃけ
今回参加したTitanic competitionはチュートリアル的コンペティションということもあり、先人方の残してくれた情報がたくさんありました。 様々なNotebooksや記事を参考にさせていただきました。 ありがとうございました。
[参考文献]
- Introduction to Ensembling/Stacking in Python | Kaggle
- Titanic Data Science Solutions | Kaggle
- Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~ - Qiita
- Kaggle Titanic competitionでようやくTop 5%に乗った話 - Qiita
- kaggle/titanic 欠損値の補完と特徴量エンジニアリング - Qiita
やったこと
「特徴量の作成」です。 予測精度を上げるためには、特徴量の作成が重要であり、多くの時間を割きます。 大雑把に言うと「特徴量≒機械学習の入力」であり、良い特徴量を作れたかで順位が決まるといっても過言ではありません。 特徴量の作成にあたり、まずは入力データの分析を行いました。
[1] データ分析
[1-1] Titanicコンペの入力データ
Titanicコンペでは、予測対象「Survived(生存したか)」を除くと、11パラメータあります。 11パラメータとSurvivedの関係、11パラメータ同士の関係を見ていきました。
| パラメータ | 説明 |
|---|---|
| PassengerId | 乗客ID |
| Pclass | 社会経済的地位 |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 乗船している兄弟・夫妻の数 |
| Parch | 乗船している親・子の数 |
| Ticket | チケット番号 |
| Fare | 運賃 |
| Cabin | キャビン番号 |
| Embarked | 乗船港 |
[1-2] 分析した結果
結論、以下の内容が分かりました。
- Ageが小さい人(子供)の生存率は高い
- Pclassが小さいほど生存率は高い
- 女性の方が男性よりも生存率は高い
- SibSp=1,2の人は生存率は高い
- Parch=1,2,3の人は生存率は高い
- Fareは高い方が生存率は高い
- Embarked=Cの人は生存率は高い
[1-3] 数値で見る
データの個数とNaNの数、平均値といった数値を確認しました。
[1-3-1] NaNの数
データの個数と、それに対するNaNの数を知ることは重要です。 NaNがあまりに多いデータはモデルへの入力として使うのを止めますし、NaNが少数であれば補間することも考えます。
データの個数とNaNの数は、pandas.DataFrameのinfo()で確認できます。
train_data.info() # <class 'pandas.core.frame.DataFrame'> # RangeIndex: 891 entries, 0 to 890 # Data columns (total 12 columns): # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 PassengerId 891 non-null int64 # 1 Survived 891 non-null int64 # 2 Pclass 891 non-null int64 # 3 Name 891 non-null object # 4 Sex 891 non-null object # 5 Age 714 non-null float64 # 6 SibSp 891 non-null int64 # 7 Parch 891 non-null int64 # 8 Ticket 891 non-null object # 9 Fare 891 non-null float64 # 10 Cabin 204 non-null object # 11 Embarked 889 non-null object # dtypes: float64(2), int64(5), object(5) # memory usage: 83.7+ KB
NaNの数だけを確認する場合は、isnull().sum()の方が見やすいです。
train_data.isnull().sum() # PassengerId 0 # Survived 0 # Pclass 0 # Name 0 # Sex 0 # Age 177 # SibSp 0 # Parch 0 # Ticket 0 # Fare 0 # Cabin 687 # Embarked 2 # dtype: int64
[1-3-2] 統計量
平均や標準偏差といった基本的な統計量は、pandas.DataFrameのdescribe()で確認できます。 NaNを除いた数値について、平均・標準偏差・最小・最大といった統計量が出力されます。
train_data.describe()
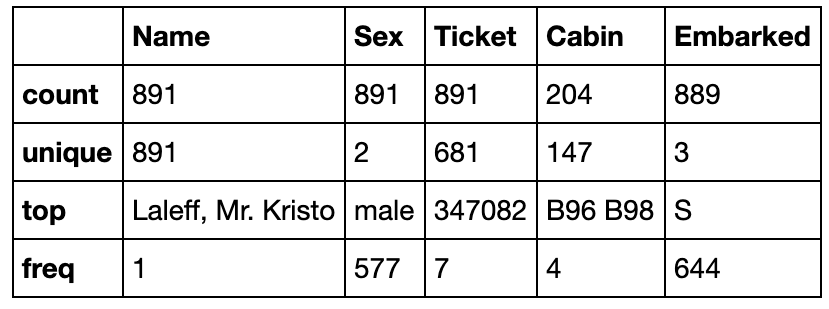
 カテゴリーデータについて見たい場合は、includeにO(大文字のオー)を指定します。
カテゴリーデータについて見たい場合は、includeにO(大文字のオー)を指定します。
train_data.describe(include='O')
[1-4] グラフで見る
seabornやmatplotlibを使って可視化しました。 数値として見ることも重要なのですが、視覚的に理解することも重要だと言うことも分かりました。
[1-4-1] seabornとmatplotlibを使う
使い方は難しくはありません。例えば、次のようなコードになります。
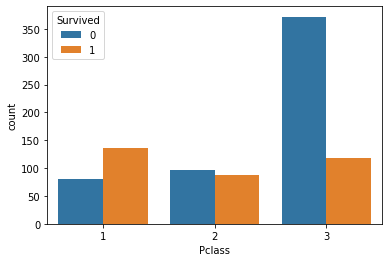
%matplotlib inline # Jupyter Notebook上にグラフを描画するためのおまじない import seaborn as sns sns.countplot(x='Pclass', data=train_data, hue='Survived')
seabornのインストールはpipで行いました。
pip3 install seaborn
[1-4-2] 可視化結果
全てではありませんが、seabornやmatplotlibで可視化した結果です。
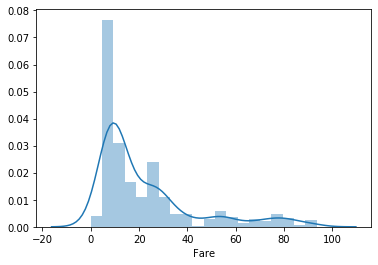
Fare(運賃)
low_fare_data = train_data[train_data["Fare"] < 100] sns.distplot(low_fare_data['Fare'], bins=20)
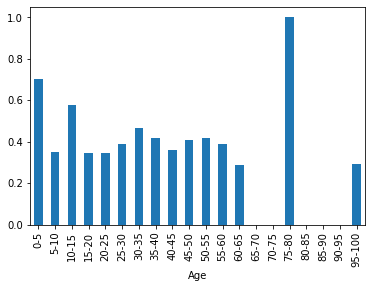
Age(年齢) & Survival rate(生存率)
# Ageの欠損値を99歳で埋める age_filled_data = train_data.fillna({'Age': 99}) # 5歳単位でビニング(-1始まりなのは0を含めたかったから。pd.cutは開始値を含まない) age_bins_list = [-1] + list(range(5, 101, 5)) age_bins_label = [ "{0}-{1}".format(age, age + 5) for age in list(range(0, 100, 5)) ] age_bins = pd.cut(age_filled_data['Age'], bins=age_bins_list, labels=age_bins_label) # Ageでグループ化し平均を取る age_grouped_data = age_filled_data.groupby(age_bins).mean() age_grouped_data['Survived'].plot(kind='bar')
Age(年齢) & Pclass(社会経済的地位)
grid = sns.FacetGrid(train_data, hue='Pclass', aspect=4) grid.map(sns.kdeplot,'Age', shade= True) max_age = train_data['Age'].max() grid.set(xlim=(0, max_age)) grid.add_legend()
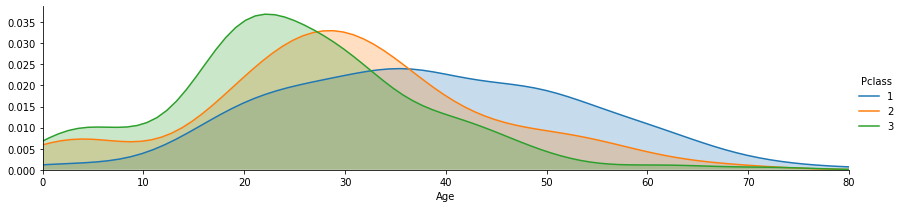
Sex(性別) & Pclass(社会経済的地位) & Survival rate(生存率)
sns.catplot(x='Pclass',y='Survived', hue='Sex', data=train_data, kind='point')

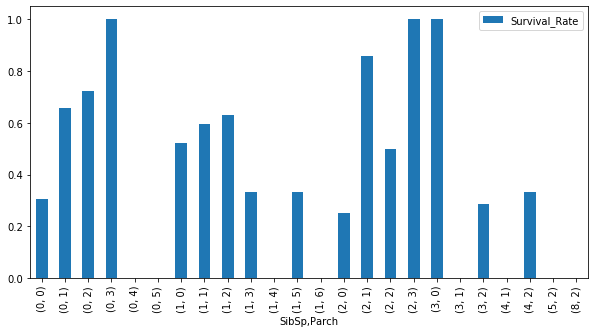
SibSp(兄弟・夫妻の数) & Parch(親・子の数) & Survival rate(生存率)
# SibSpとParchでグループ化し、生存者の合計(sum)と全人数(count)を算出 sibsp_parch_group = train_data.groupby(['SibSp', 'Parch']) survived = sibsp_parch_group['Survived'].sum() count = sibsp_parch_group['Survived'].count() # SibSpとParchの組み合わせごとの生存率を可視化 sibsp_parch_rate = pd.DataFrame(index=survived.index) sibsp_parch_rate['Survival_Rate'] = survived / count sibsp_parch_rate.plot.bar(figsize=(10, 5))
[1-5] どの特徴量が重要か
特徴量のうち、予測精度に影響するものとそうでないものを探します。 例えば、PassengerIdは影響しないと考えられます。
[1-5-1] NaNを埋める
とりあえず、すべての入力パラメータを特徴量として、ランダムフォレストで予測を行ってみます。 NaNがあると予測が出来ないので、NaNを適当な値で埋めます。
from sklearn.preprocessing import LabelEncoder train_all = train_data.copy() test_all = test_data.copy() train_all.fillna({'Age': 99, 'Ticket': 'Na', 'Fare': 999, 'Cabin': 'Na', 'Embarked': 'Na'}, inplace=True) test_all.fillna({'Age': 99, 'Ticket': 'Na', 'Fare': 999, 'Cabin': 'Na', 'Embarked': 'Na'}, inplace=True) all_data = pd.concat([train_all, test_all]) for column in ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']: encoder = LabelEncoder() encoder.fit(all_data[column]) train_all[column] = encoder.transform(train_all[column]) test_all[column] = encoder.transform(test_all[column])
[1-5-2] 重要度の可視化
NaNを埋めたら、特徴量の重要度を可視化します。
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import KFold, cross_val_score train_y = train_all['Survived'] train_x = train_all.drop(columns=['Survived']) test_x = test_all # Evaluation of features model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1) model.fit(train_x, train_y) # Visualize the importance of each feature importances = model.feature_importances_ feature_importances = pd.DataFrame(importances, index=train_x.columns, columns=['Importance']) feature_importances = feature_importances.sort_values(by='Importance', ascending=False) feature_importances.plot.bar()

PassengerIdより重要度の低い'Name', 'SibSp', 'Parch', 'Embarked'は、そのままでは予測精度に影響しないということが分かりました。
[2] 特徴量の作成
分析した結果をもとに新しい特徴量を作成したり、既存の特徴量を加工しました。
[2-1] Name(名前)から敬称を抽出
NameからMr., Miss.などの敬称を抽出します。 敬称自体も特徴量として使えますが、NaNを埋める際にも役に立つので、真っ先に敬称の抽出を行いました。
def preprocess_name(df): # Extract the character string corresponding to "~~." from Name. df["Title"] = df['Name'].str.extract("([A-Za-z]+)\.") pd.crosstab(df['Title'], [df['Sex'], df['Pclass']]) # Group into representative titles df['Title'] = df['Title'].replace(['Countess', 'Lady', 'Major', 'Sir'], 'Upper') df['Title'] = df['Title'].replace(['Capt', 'Col', 'Don', 'Dona', 'Jonkheer', 'Rev' ], 'Rare') df['Title'] = df['Title'].replace(['Mlle', 'Ms'], 'Miss') df['Title'] = df['Title'].replace(['Mme'], 'Mrs')
敬称自体も特徴量として有用性が高いので、数値に変換して特徴量として使えるようにしました。
def convert_title_to_scalar(df): df['TitleNumber'] = 0 temp = df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean().sort_values(by='Survived') temp['TitleNumber'] = np.arange(len(temp)) for i in range(len(temp)): title = temp.iloc[i]['Title'] number = temp.iloc[i]['TitleNumber'] df.loc[df['Title'] == title, 'TitleNumber'] = number
[2-2] 既にある特徴量の前処理
新しい特徴量を作成する前に、既にある特徴量に対して前処理を行いました。
[2-2-1] Sex(性別)
文字列を数値化しただけです。
def preprocess_sex(df): df['Sex'] = df['Sex'].replace({'male':0, 'female': 1})
[2-2-2] Age(年齢)
Ageを4つの区分に分類しました。0歳から5歳の生存率が高く、60歳以上の生存率が低かったので、下記分類にしました。
NaNは敬称ごとのメディアン(中央)で埋めました。 敬称ごとに統計量を算出して埋めるのは下記記事を参考にさせていただきました。
kaggle/titanic 欠損値の補完と特徴量エンジニアリング - Qiita
def preprocess_age(df): df['Age'] = df.groupby(['Title'])['Age'].apply(lambda age: age.fillna(age.dropna().median())) def generations(age): if age <= 6: return 0 if age <= 18: return 1 if age <= 60: return 2 return 3 df['Generation'] = df['Age'].map(lambda age : generations(age))
[2-2-3] Fare(運賃)
Fareが10以下の人が多くかつ生存率も低く、Fareが高い人は生存率が高かったです。 そのため、Fareの低い方を細かく、高い方は広く分類しました。 NaNはAgeと同様に、敬称ごとのメディアン(中央)で埋めました。
def preprocess_fare(df): df['Fare'] = df.groupby(['Title'])['Fare'].apply(lambda fare: fare.fillna(fare.dropna().median())) def fare_range(fare): if fare < 5: return 0 if fare < 10: return 1 if fare < 15: return 2 if fare < 20: return 3 if fare < 50: return 4 return 5 df['FareRange'] = df['Fare'].map(lambda fare : fare_range(fare))
[2-2-4] Cabin(キャビン番号)
CabinはNaNが多かったため、CabinがNaNかそれ以外かを特徴量にしました。
def preprocess_cabin(df): df["HasCabin"] = df['Cabin'].map(lambda cabin : 0 if type(cabin)==float else 1)
[2-2-5] Embarked(乗船港)
NaNをモード(最頻値)で埋め、数値に変換しました。
def preprocess_embarked(df): mode = df['Embarked'].mode()[0] df['Embarked'].fillna(mode, inplace=True) df = df.astype({'Embarked': int}) df['Embarked'] = df['Embarked'] .replace({'S':0, 'Q': 1, 'C': 2})
[2-3] 新しい特徴量を作成する
[2-3-1] FamilySize(家族の人数)
多くの先人方がFamilySizeを用いて精度を上げていました。 SibSp(兄弟・夫妻の数)とParch(親・子の数)を加算します。 加えて、IsAlone(家族の乗船有無)も加えました。
def preprocess_sibsp_parch(df): df['FamilySize'] = df['SibSp'] + df['Parch'] df['IsAlone'] = df['FamilySize'].map(lambda fsize : 1 if fsize==0 else 0)
[2-3-2] FamilyDeath(家族の生存率)
Kaggle Titanic competitionでようやくTop 5%に乗った話 - Qiitaを参考にさせていただきました。
LastNameが同じ、かつ、FamilySizeが同じ人は家族とみなし、家族の生存率を計算しFamilyDeathとしました。 家族の生存率が計算出来ない場合は0.5としました。
def create_family_death(df): df['LastName'] = df['Name'] .map(lambda name: name.split(",")[0]) df['FamilyDeath'] = np.nan col_no = df.columns.get_loc('FamilyDeath') for i in range(len(df)): if df.iloc[i]['FamilySize'] > 0: last_name = df.iloc[i]['LastName'] family_size = df.iloc[i]['FamilySize'] # Extract data of family members except yourself temp = pd.concat([df.iloc[:i], df.iloc[i+1:]]) family = temp[(temp['LastName'] == last_name) & (temp['FamilySize'] == family_size)] if len(family) == 0: continue # Set the average of the survival rate of the family excluding yourself df.iloc[i, col_no] = family.Survived.mean() df['FamilyDeath'].fillna(0.5, inplace=True) create_family_death(all_data)
[3] 評価
[3-1] 不要な特徴量を除去する
別の特徴量を作成済みのものや、明らかに不要と思われる特徴量を除去しました。
def drop_unnecessary_features(df): drop_columns = ['Name', 'Age', 'SibSp', 'Parch', 'Fare', 'Ticket', 'Cabin', 'Title', 'LastName'] df.drop(columns=drop_columns, inplace=True)
[3-2] どの特徴量が重要かを検証する
一度、クロスバリデーションで評価を行い、どの特徴量が重要かを確認しました。
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import KFold, StratifiedKFold, cross_val_score # Trainning with cross validation and and score calculation model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1) kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=1) result = cross_val_score(model, train_x, train_y, cv=kf, scoring='accuracy') print('Score:{0:.4f}'.format(result.mean())) # Evaluation of features model.fit(train_x, train_y) importances = model.feature_importances_ # Visualize the importance of each feature feature_importances = pd.DataFrame(importances, index=train_x.columns, columns=['Importance']) feature_importances = feature_importances.sort_values(by='Importance', ascending=False) feature_importances.plot.bar()
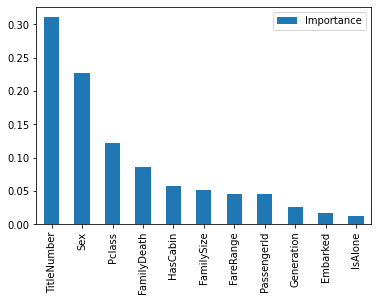
スコアは0.8373でした。
[3-3] 重要度の低い特徴量を除去する
PassengerIdより重要度の低い'Generation', 'Embarked', 'IsAlone'は、予測精度に大きく影響していないので除去します。
def drop_less_effective_features(df): drop_columns = ['PassengerId', 'Generation', 'Embarked', 'IsAlone'] df.drop(columns=drop_columns, inplace=True)
[3-4] 本番
ソースコードは[3-2]と同様です。
 スコアは0.8429でした。
スコアは0.8429でした。
[4] 結果を提出
[4-1] 予測結果を出力
# Prediction predictions = model.predict(test_x) # Output result to csv. output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions}) output.to_csv('my_submission.csv', index=False)
[4-2] 提出
冒頭で書いた通り、結果は0.80382でした。

最後に
今回は先人方の力を借りまくり、なんとか予測精度を上げることが出来ました。とは言っても、まだまだ上がいますが。
Titanic competitionはこれで終わりにします。新しいコンペに参加してみたいと思います。