【Python】Face Recognitionで顔検出
「Face Recognition」というPythonの顔認識ライブラリを使い、顔検出を行いました。
中身は「dlib」なので、顔検出の精度は「dlib」と変わりませんが、顔認識に用途を絞ってより使いやすく作られています。
Face Recognition — Face Recognition 1.4.0 documentation
[1] Face Recognitionのインストール
pip3 install face_recognition --user
前提として「dlib」のインストールが必要です。インストール方法は、以前の記事で紹介した内容の通りです。
https://predora005.hatenablog.com/entry/2021/08/30/190000predora005.hatenablog.com
[2] ソースコード
公式のExample2つを参考にしています。検出期にCNNを使うか否か以外は同じ内容です。
- face_recognition/find_faces_in_picture.py at master · ageitgey/face_recognition · GitHub
- face_recognition/find_faces_in_picture_cnn.py at master · ageitgey/face_recognition · GitHub
顔検出だけであれば「dlib」のみインポートで十分ですが、検出領域の表示等で「OpenCV」を使用しています。
[2-1] HOG特徴量ベースの顔検出
import os import cv2 import face_recognition # 顔検出する画像のファイルリスト filelist = [ 'sample1.jpg', 'sample2.jpg', 'sample3.jpg'] imgdir = os.path.join(os.path.expanduser('~'), 'img') filepaths = [os.path.join(imgdir, file) for file in filelist] # HOG特徴量ベースの顔検出 for filepath in filepaths: # 画像読み込み image = face_recognition.load_image_file(filepath) # HOGベースモデルの顔検出実行 face_locations = face_recognition.face_locations(image) # 検出した領域を表示 print("------------------------------") print("I found {} face(s) in this photograph.".format(len(face_locations))) for face_location in face_locations: top, right, bottom, left = face_location print("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right)) # 顔検出した領域を短形表示した画像を保存 save_face_located_image(filepath, face_locations, 'hog')
[2-2] CNNモデルの顔検出
HOG特徴量ベースの検出と変わるのはface_recognition.face_locationsの引数のみです。model="cnn"と指定することでCNNによる顔検出が行われます。
number_of_times_to_upsampleはアップサンプリングの回数です。デフォルトは1です。
# ここまではHOG特徴量ベースの検出と同じ # 学習済みCNNモデルによる顔検出 for filepath in filepaths: # 画像読み込み(HOG特徴量ベースの検出と同じ) image = face_recognition.load_image_file(filepath) # CNNベースモデルの顔検出実行 face_locations = face_recognition.face_locations( image, number_of_times_to_upsample=1, model="cnn") # 検出した領域を表示(HOG特徴量ベースの検出と同じ) print("------------------------------") print("I found {} face(s) in this photograph.".format(len(face_locations))) for face_location in face_locations: top, right, bottom, left = face_location print("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right)) # 顔検出した領域を短形表示した画像を保存 save_face_located_image(filepath, face_locations, 'cnn')
[2-3] 顔検出した領域を短形表示した画像を保存
上記ソースコードで使用したsave_face_located_imageのソースコードは以下の通りです。
画面に表示できる環境であれば、わざわざ保存せず表示する方が簡単です。dlib, Pillow, OpenCVなどを使えば表示することは可能です。
def save_face_located_image(filepath, face_locations, prefix): # 保存用の画像データを準備 save_img = cv2.imread(filepath) # 検出した範囲を保存用画像に短形表示 for face_location in face_locations: y1, x2, y2, x1 = face_location cv2.rectangle(save_img, (x1, y1), (x2, y2), color=(0,0,255), thickness=4) # 検出領域を示した画像を保存 filename = os.path.basename(filepath) filedir = os.path.dirname(filepath) save_filename = prefix + '_' + filename save_imgpath = os.path.join(filedir, save_filename) cv2.imwrite(save_imgpath, save_img)
[3] 顔検出の結果
中身が「dlib」なので検出精度は変わりません。以前紹介した記事と同じ画像で検出を行っても、同じ結果になります。
- https://predora005.hatenablog.com/entry/2021/08/30/190000
- https://predora005.hatenablog.com/entry/2021/09/02/190000
以前紹介したものとは異なる画像で検出を行ってみます。
[3-1] HOG特徴量ベースの検出結果
 <青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
<青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
 <jswashburnによるPixabayからの画像>
<jswashburnによるPixabayからの画像>
 <Joseph MuciraによるPixabayからの画像>
<Joseph MuciraによるPixabayからの画像>
[3-2] CNNモデルの検出結果
 <青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
<青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
 <jswashburnによるPixabayからの画像>
<jswashburnによるPixabayからの画像>
 <Joseph MuciraによるPixabayからの画像>
<Joseph MuciraによるPixabayからの画像>
終わりに
「Face Recognition」は「dlib」ベースです。「dlib」と精度は変わりませんが、より簡単に顔検出ができるようになっていました。
顔検出や顔認識をするのであれば「Face Recognition」を使うのが、精度も良くお手軽だと思います。
参考文献
画像の出典
【Python】dlibで顔検出(CNN版)
前回紹介した「dlib」の顔検出のうち、CNN版で顔検出を行いました。
前回、dlibで顔検出を行いOpenCVよりも精度は向上しました。しかしながら、横顔の検出などには課題が残りました。
https://predora005.hatenablog.com/entry/2021/08/30/190000predora005.hatenablog.com
CNN版を使用した結果を先に言うと、処理時間が長くなるものの精度は向上しました。

[1] 事前準備
[1-1] dlibのインストール
前回紹介した内容と同様です。
https://predora005.hatenablog.com/entry/2021/08/30/190000https://predora005.hatenablog.com/entry/2021/08/30/190000
[1-2] 顔検出器のダウンロード
学習済みのモデルをダウンロードし、解凍します。
curl -O http://dlib.net/files/mmod_human_face_detector.dat.bz2 bzip2 -d mmod_human_face_detector.dat.bz2
[2] ソースコード
公式のExampleを元に作成しています。
dlib/cnn_face_detector.py at master · davisking/dlib · GitHub
顔検出だけであれば「dlib」のみインポートで十分ですが、検出領域の表示等で「OpenCV」を使用しています。
mport os import cv2 import dlib # 顔検出器を取得 detector_file = 'mmod_human_face_detector.dat' detector_path = os.path.join(os.path.expanduser('~'), detector_file) cnn_face_detector = dlib.cnn_face_detection_model_v1(detector_path) # 読み込むファイルのリスト filelist = [ 'sample1.jpg', 'sample2.jpg', 'sample3.jpg'] for file in filelist: print("------------------------------") print("Processing file: {}".format(file)) # 画像を読み込み imgdir = os.path.join(os.path.expanduser('~'), 'img') imgpath = os.path.join(imgdir, file) img = dlib.load_rgb_image(imgpath) # 顔検出を実行 dets = cnn_face_detector(img, 1) # 検出した領域を出力 print("Number of faces detected: {}".format(len(dets))) for i, d in enumerate(dets): print("Detection {}: Left: {} Top: {} Right: {} Bottom: {} Confidence: {}".format( i, d.rect.left(), d.rect.top(), d.rect.right(), d.rect.bottom(), d.confidence)) # 保存用の画像データを準備 save_img = cv2.imread(imgpath) # 検出した範囲を保存用画像に短形表示 for d in dets: x1, y1, x2, y2 = d.rect.left(), d.rect.top(), d.rect.right(), d.rect.bottom() cv2.rectangle(save_img, (x1, y1), (x2, y2), color=(0,0,255), thickness=4) # 検出領域を示した画像を保存 save_file = 'dlib_cnn_' + file save_imgpath = os.path.join(imgdir, save_file) cv2.imwrite(save_imgpath, save_img)
[3] 顔検出の結果
以前に紹介したOpenCVと同じ画像で、顔検出を行いました。
https://predora005.hatenablog.com/entry/2021/08/23/190000predora005.hatenablog.com
[3-1] OpenCVでも上手くいった例

OpenCVと同様に、上手く検出できています。
[3-2] OpenCVでは微妙だった例
 <Werner HeiberによるPixabayからの画像>
<Werner HeiberによるPixabayからの画像>
CNN版では6人中5人まで検出できています。OpenCVでは6人中3人の検出、dlibでは6人中4人の検出でした。
[3-3] OpenCV, dlibでは上手くいかなかった例
OpenCV, dlibともに1人しか検出できていませんでしたが、CNN版では4人まで検出できています。
[4] 補足とトラブルシューティング
[4-1] Memory Error
t3.medium(メモリ 4GiB)では足りませんでした。r5.large(メモリ 16GiB)では足りました。
MemoryError: std::bad_alloc
終わりに
CNN版を用いることで、精度が大きく向上しました。
一方、精度が向上したトレードオフとして、処理時間が長くなり、メモリ使用量が増大しました。
マシンスペックがそれなりに無いと動きません。小スペックの場合にはCNNではない、顔検出器を用いるのが良さそうです。
参考文献
画像の出典
- ゆうせい モデルの紹介 - ぱくたそ
- Werner HeiberによるPixabayからの画像
- Sanu A SによるPixabayからの画像
【Python】dlibで顔検出
dlibで顔検出を行いました。dlibは機械学習を始め様々な機能が含まれたライブラリです。
検出精度はOpenCVよりも若干良く、横向きの顔もある程度検出できています。

[1] dlibのインストール
dlibインストール前にgcc, CMakeをインストールします。
sudo yum -y install gcc gcc-c++ sudo yum -y install cmake
インストール完了後にdlibをインストールします。インストール完了までに数十分かかりました。
pip3 install dlib --user
[2] ソースコード
公式のExampleを元に作成しました。
dlib/face_detector.py at master · davisking/dlib · GitHub
顔検出だけであれば「dlib」のみインポートで十分ですが、検出領域の表示等で「OpenCV」を使用しています。
import os import cv2 import dlib # 顔検出器を取得 detector = dlib.get_frontal_face_detector() # 読み込むファイルのリスト filelist = [ 'sample1.jpg', 'sample2.jpg', 'sample3.jpg'] for file in filelist: print("------------------------------") print("Processing file: {}".format(file)) # 画像を読み込み(画像はホーム下のimgディレクトリに置く想定) imgdir = os.path.join(os.path.expanduser('~'), 'img') imgpath = os.path.join(imgdir, file) img = dlib.load_rgb_image(imgpath) # 顔検出(第二引数はアップサンプリング(拡大)の回数) dets = detector(img, 1) print("Number of faces detected: {}".format(len(dets))) # 検出した範囲を表示 for i, d in enumerate(dets): print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format( i, d.left(), d.top(), d.right(), d.bottom())) # 検出した範囲を短形表示し、別画像として保存 save_img = cv2.imread(imgpath) # 検出した範囲を保存用画像に短形表示 for d in dets: x1, y1, x2, y2 = d.left(), d.top(), d.right(), d.bottom() cv2.rectangle(save_img, (x1, y1), (x2, y2), color=(0,0,255), thickness=4) # 別名ファイルで保存 save_file = 'dlib_' + file save_imgpath = os.path.join(imgdir, save_file) cv2.imwrite(save_imgpath, save_img)
[3] 顔検出の結果
以前に紹介したOpenCVと同じ画像で、顔検出を行いました。
https://predora005.hatenablog.com/entry/2021/08/23/190000predora005.hatenablog.com
[3-1] OpenCVでも上手くいった例

OpenCVと同様に、上手く検出できています。
[3-2] OpenCVでは微妙だった例
<Werner HeiberによるPixabayからの画像>
OpenCVでは6人中3人の検出でした。OpenCVに比べると若干よくなっています。
[3-3] OpenCVでは上手くいかなかった例

OpenCVでも1人しか検出できていませんでしたので、OpenCVと同じ結果でした。
[4] 補足とトラブルシューティング
[4-1] ERROR: CMake must be installed to build dlib
gcc, CMakeをインストールせずに、dlibをインストールしようと以下のエラーが発生します。
ERROR: CMake must be installed to build dlib
gcc, CMakeをインストールすれば解決します。
sudo yum -y install gcc gcc-c++ sudo yum -y install cmake
[4-2] 検出スコアの表示
公式のExampleには、顔検出のスコアを表示方法も載っています。
detector.run()を用いることでスコアを表示します。
また、第三引数が閾値のため負値にすることで、検出する領域を意図的に増やしています。
for file in filelist: print("------------------------------") print("Processing file: {}".format(file)) # 画像を読み込み imgdir = os.path.join(os.path.expanduser('~'), 'img') imgpath = os.path.join(imgdir, file) img = dlib.load_rgb_image(imgpath) # 検出結果のスコアを表示(第三引数は閾値。デフォルトは0.0) dets, scores, idx = detector.run(img, 1, -1) for i, d in enumerate(dets): # idxは、どのサブ検出器にマッチしたか print("Detection {}, score: {}, face_type:{}".format( d, scores[i], idx[i]))
以下のような結果が出力されます。
------------------------------ Processing file: sample1.jpg Detection [(134, 206) (455, 527)], score: 0.5904139076373007, face_type:2 Detection [(141, 498) (409, 766)], score: -0.7469268450893916, face_type:3 Detection [(125, 1010) (161, 1046)], score: -0.7642095983401345, face_type:4 Detection [(55, 305) (98, 348)], score: -0.815978666673002, face_type:2 Detection [(573, 870) (609, 906)], score: -0.9177183116772745, face_type:2 Detection [(270, 171) (345, 246)], score: -0.939228042476612, face_type:1 ------------------------------ Processing file: sample2.jpg Detection [(101, 147) (152, 199)], score: 2.2398508228792067, face_type:0 Detection [(210, 49) (262, 101)], score: 2.1349826012916986, face_type:1 Detection [(325, 55) (377, 107)], score: 1.57835485089497, face_type:1 Detection [(446, 153) (498, 205)], score: 1.0782284890480462, face_type:1 Detection [(561, 106) (597, 142)], score: -0.8876646961072061, face_type:2 Detection [(461, 138) (497, 174)], score: -0.9027303159609841, face_type:4 Detection [(255, 295) (344, 385)], score: -0.9184605087140176, face_type:2 Detection [(381, 300) (424, 343)], score: -0.9242407641874437, face_type:0 Detection [(193, 337) (245, 389)], score: -0.9605490173199747, face_type:2 ------------------------------ Processing file: sample3.jpg Detection [(299, 89) (343, 132)], score: 2.0312632118365195, face_type:2 Detection [(596, 285) (648, 337)], score: -0.6916471923688028, face_type:2 Detection [(96, -13) (185, 86)], score: -0.8069736323820238, face_type:0 Detection [(487, 118) (538, 170)], score: -0.8929136693850563, face_type:4 Detection [(497, 20) (605, 128)], score: -0.9076731051139411, face_type:1 Detection [(103, 152) (211, 259)], score: -0.9933327138796852, face_type:4
[4-3] Memory Error
t3.medium(メモリ 1GiB)では足りませんでした。t3.medium(メモリ 4GiB)では足りました。
MemoryError: std::bad_alloc
終わりに
dlibではOpenCVよりも若干ですが、精度の良い顔検出が行えました。
とは言え、横顔の検出精度はまだまだでした。やはりディープラーニング等の機械学習を使った方が、精度が出るのかなという印象でした。
参考文献
画像の出典
- ゆうせい モデルの紹介 - ぱくたそ
- Werner HeiberによるPixabayからの画像
- Sanu A SによるPixabayからの画像
【Python】OpenCVで顔検出
OpenCVはインストールも簡単で、ひとまず顔検出を試すにはもってこいです。
正面以外の検出精度は微妙ですが、正面の顔を検出するなら十分です。短時間かつ低精度で構わないの場面で用いるのが良いでしょう。

[1] OpenCVのインストール
pip3 install opencv-python --user
上記だけではインポートエラーが発生するため「mesa-libGL」をインストールします。
sudo yum -y install mesa-libGL
詳しくは以下の記事にまとめています。
[2] ソースコード
公式のDocumentationを元に作成しました。
公式の例ではカメラから画像を取り込んでいますが、ここではダウンロード済みの画像を扱う例を紹介します。
import cv2 import os # サンプルデータのパスを追加 homedir = os.path.expanduser('~') cv2dir = '.local/lib/python3.7/site-packages/cv2/' cv2path = os.path.join(homedir, cv2dir) cv2.samples.addSamplesDataSearchPath(cv2path) # サンプル分類器を取得 face_cascade_name = 'data/haarcascade_frontalface_alt.xml' eyes_cascade_name = 'data/haarcascade_eye_tree_eyeglasses.xml' face_cascade = cv2.CascadeClassifier() eyes_cascade = cv2.CascadeClassifier() face_cascade.load(cv2.samples.findFile(face_cascade_name)) eyes_cascade.load(cv2.samples.findFile(eyes_cascade_name)) # 画像を読み込み(imgディレクトリにsample.jpgを置く) imgdir = 'img' imgpath = os.path.join(imgdir, 'sample.jpg') img = cv2.imread(imgpath) # 画像をグレースケールに変換 img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 顔検出 faces = face_cascade.detectMultiScale(img_gray) for face in faces: # 顔検出した領域を赤枠で描画 xf, yf, wf, hf = face cv2.rectangle(img, (xf, yf), (xf+wf, yf+hf), color=(0,0,255), thickness=4) # 顔検出した領域から、目を検出 face_img = img[yf:yf+hf, xf:xf+wf] eyes = eyes_cascade.detectMultiScale(face_img) for eye in eyes: # 目を検出した領域を緑楕円で描画 xe, ye, we, he = eye eye_center = (xf + xe + we//2, yf + ye + he//2) cv2.ellipse(img, eye_center, axes=(we//2, he//2), angle=0, startAngle=0, endAngle=360, color=(0, 255, 0), thickness=4) # 検出領域を示した画像を表示 cv2.imshow('Capture - Face detection', img)
[3] 顔検出の結果
[3-1] 非常に上手くいった例
赤枠が顔検出した領域、緑枠が顔検出した領域内から目を検出した領域です。
これは非常に上手くいった例です。正面の顔であれば、このように高精度で検出してくれます。
[3-2] すこし微妙な例

<Werner HeiberによるPixabayからの画像>
6人中3人を顔検出できています。顔が正面以外の向きだと、検出精度が下がります。
[3-3] 上手くいかない例

5人中1人しか顔検出できていません。顔が正面以外の向きだと、検出精度が下がります。
[4] 補足とトラブルシューティング
[4-1] 検出器の種類
検出器は、OpenCVで用意されたものを利用しています。
Amazon Linux2の環境では/home/{ユーザ名}/.local/lib/python3.7/site-packages/cv2/dataに格納されています。
顔検出以外にも様々な分類器が用意されています。
ls /home/{ユーザ名}/.local/lib/python3.7/site-packages/cv2/data # haarcascade_eye_tree_eyeglasses.xml haarcascade_licence_plate_rus_16stages.xml # haarcascade_eye.xml haarcascade_lowerbody.xml # haarcascade_frontalcatface_extended.xml haarcascade_profileface.xml # haarcascade_frontalcatface.xml haarcascade_righteye_2splits.xml # haarcascade_frontalface_alt2.xml haarcascade_russian_plate_number.xml # haarcascade_frontalface_alt_tree.xml haarcascade_smile.xml # haarcascade_frontalface_alt.xml haarcascade_upperbody.xml # haarcascade_frontalface_default.xml __init__.py # haarcascade_fullbody.xml __pycache__ # haarcascade_lefteye_2splits.xml
各ファイルの役割は下記サイトなど、いくつかのサイトがまとめてくれています。
【Python版OpenCV】Haar Cascadeで顔検出、アニメ顔検出、顔にモザイク処理 | 西住工房
[4-2] 検出器の読込失敗
用意された検出器を読み込もうとすると、ファイルが見つからないエラーが発生します。
face_cascade_name = 'data/haarcascade_frontalface_alt.xml' face_cascade = cv.CascadeClassifier() face_cascade.load(cv.samples.findFile(face_cascade_name)) # OpenCV(4.5.3) /tmp/pip-req-build-l1r0y34w/opencv/modules/core/src/utils/samples.cpp:64: error: (-2:Unspecified error) OpenCV samples: Can't find required data file: data/haarcascade_frontalface_alt.xml in function 'findFile'
cv2.samples.addSamplesDataSearchPath()で格納先のパスを検索するようにします。
import os homedir = os.path.expanduser('~') cv2dir = '.local/lib/python3.7/site-packages/cv2/' cv2path = os.path.join(homedir, cvdir) cv2.samples.addSamplesDataSearchPath(cv2path)
OpenCV: Utility functions for OpenCV samples
[4-3] 検出器のパラメータ
検出器のパラメータを調整すること精度を高めることができます。
CascadeClassifier.detectMultiScale()のパラメータを変更します。主なパラメータは次の通りです。
- scaleFactor:各画像スケールにおいて、画像サイズをどれだけ縮小するかを指定するパラメータ。
- minNeighbors:各候補の矩形が保持されるために必要な隣接数を指定するパラメータ。
- minSize:可能なオブジェクトの最小サイズ.これよりも小さいオブジェクトは無視されます.
OpenCV: cv::CascadeClassifier Class Reference
詳細は以下のサイトなどが参考になります。
- [OpenCV] detectMultiScaleの使いかた | Tech控え帳
- 物体検出(detectMultiScale)をパラメータを変えて試してみる(scaleFactor編) | Workpiles
[4-4] 検出の仕組み
Haar特徴に基づくカスケード分類器で顔検出を行なっています。
公式のチュートリアルや以下のサイトが詳しいです。
- OpenCV: Cascade Classifier
- 【入門者向け解説】openCV顔検出の仕組と実践(detectMultiScale) - Qiita
- Haar Cascadeによる顔検出の原理 | 西住工房
終わりに
冒頭で述べた通り、OpenCVはインストールも比較的容易で簡単に顔検出ができました。しかし、精度は少々物足りません。
OpenCVよりも精度の良いライブラリを探してみることにします。
参考文献
- 【入門者向け解説】openCV顔検出の仕組と実践(detectMultiScale) - Qiita
- 【Python版OpenCV】Haar Cascadeで顔検出、アニメ顔検出、顔にモザイク処理 | 西住工房
- [OpenCV] detectMultiScaleの使いかた | Tech控え帳
- 物体検出(detectMultiScale)をパラメータを変えて試してみる(scaleFactor編) | Workpiles
- Python + OpenCVで顔検出を行う
画像の出典
- ゆうせい モデルの紹介 - ぱくたそ
- Werner HeiberによるPixabayからの画像
- Sanu A SによるPixabayからの画像
【python】OpenCVでImportErrorが出たときの対処法(Amazon Linux2)
「ImportError: libGL.so.1: cannot open shared object file: No such file or directory」が出たときの対応策です。
環境によって対応策は異なります。紹介するのはAmazon Linux2の対応策です。
環境
事象発生時の状況
import cv2
OpenCVをインポートすると、次のエラーが発生します。
--------------------------------------------------------------------------- ImportError Traceback (most recent call last) /tmp/ipykernel_22658/3138839957.py in <module> ----> 1 import cv2 ~/.local/lib/python3.7/site-packages/cv2/__init__.py in <module> 3 import sys 4 ----> 5 from .cv2 import * 6 from .data import * 7 ImportError: libGL.so.1: cannot open shared object file: No such file or directory
対応策
「mesa-libGL」をyumでインストールすると解決します。
sudo yum -y install mesa-libGL
参考文献
【Python】株価のテクニカル分析指標から売買タイミングを自動計算
以前に「pandas-datareader」と「mplfinance」を用いて、テクニカル分析チャートを作成しました。その際に「MACD」や「RSI」などのテクニカル分析指標を算出しました。
今回は、これらの指標から売買のタイミングを計算します。
1銘柄ずつチャートを目視していくのは大変です。注目した方がよい銘柄を自動で割り出して、その銘柄のチャートだけを見るようにして手間を省きたいのです。
- [1] 株価の取得、テクニカル分析指標の算出
- [2] 今回使用するデータ
- [3] ゴールデンクロス・デッドクロス(MACD)
- [4] ボトムアウト・ピークアウト(ヒストグラム)
- [5] RSI
- 終わりに
- 出典
[1] 株価の取得、テクニカル分析指標の算出
以前の記事で紹介した内容で行います。
ここまで済めば、テクニカル分析チャートまでは作れます。
[2] 今回使用するデータ
ソフトバンク(9984.JP)の2021/04/01〜07/13の株価を使用します。
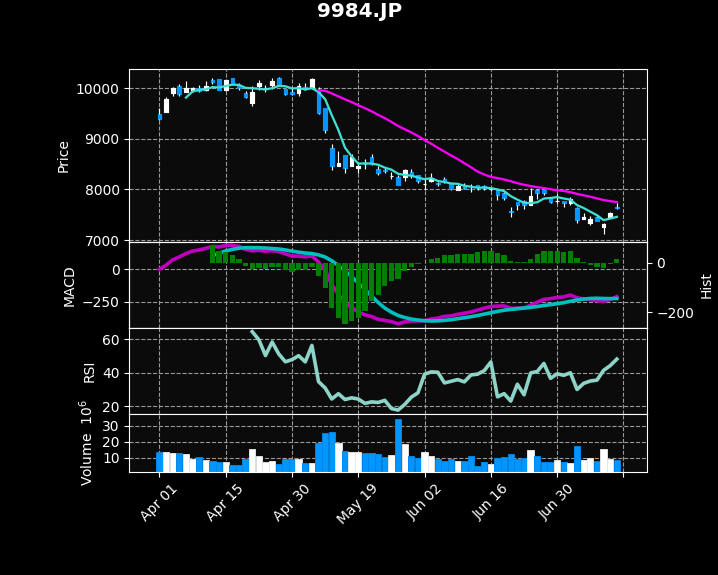
[3] ゴールデンクロス・デッドクロス(MACD)
MACDとシグナルが重なるときが、売買のタイミングと言われています。
詳しい説明は、下記サイト等を参考にしてみてください。
[3-1] ソースコード
MACDとシグナルが重なるのは差が0になるタイミングです。つまりヒストグラムが0を跨ぐタイミングです。
# ヒストグラムと日付を取り出す hists = df['Hist'] dates = df.index # 日数分ループ for i in range(1, hists.size): # 2日分取り出し h1 = hists.iloc[i-1] h2 = hists.iloc[i] # ゴールデンクロス・デッドクロスを判定 if h1 < 0 < h2: # ゴールデンクロス print(f'{dates[i]:%Y-%m-%d} {code} ゴールデンクロス {h1:.1f},{h2:.1f}') elif h1 > 0 > h2: # デッドクロス print(f'{dates[i]:%Y-%m-%d} {code} デッドクロス {h1:.1f},{h2:.1f}')
以下の出力結果が得られます。
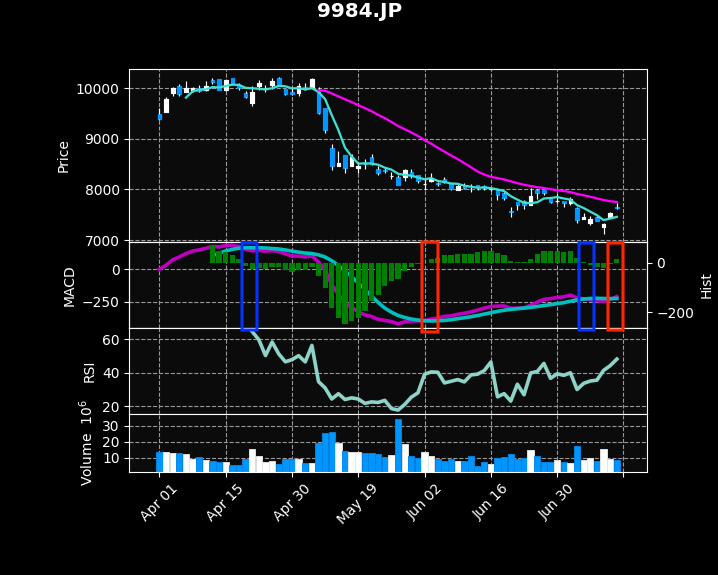
# 2021-04-20 9984.JP デッドクロス 13.8,-12.3 # 2021-06-03 9984.JP ゴールデンクロス -0.1,15.5 # 2021-07-07 9984.JP デッドクロス 1.6,-10.4 # 2021-07-13 9984.JP ゴールデンクロス -6.9
[3-2] チャート
出力結果をチャート上に示すと、赤枠と青枠の部分になります。赤枠がゴールデンクロス、青枠がデッドクロスです。
[3-3] 計算通りに売買したら成功したか
04/20の売りは、5月に入り株価が下落したため成功と言えます。一方、06/03の売りは7月中旬時点では成功とは言えません。
また、07/07, 07/13と短期間にデッドクロス・ゴールデンクロスが発生しています。頻繁に発生するような場合は、売買タイミングと考えるのは難しそうです。
[4] ボトムアウト・ピークアウト(ヒストグラム)
ヒストグラムが天井・天底をうつときも売買の目安と言われています。
ゴールデンクロス・デッドクロスよりも反応が早いと言われています。詳しい説明は、下記サイト等を参考にしてみてください。
[4-1] ソースコード
ヒストグラムを用いて計算しますが、小さな変化を拾いすぎないように以下の条件としています。
- ボトムアウト:2日連続で減少後に2日連続で上昇 and 負値
- ピークアウト:2日連続で上昇後に2日連続で減少 and 正値
減少・上昇は日毎の差分をh5d.diff()で取得し、差分の正負で判断しています。
# ヒストグラムと日付を取り出す hists = df['Hist'] dates = df.index # 日数分ループ for i in range(0, hists.size-5): # 5日分取り出し h5d = hists.iloc[i:i+5] # 日毎の差分を取得 hdiff = h5d.diff() # ボトムアウト・ピークアウトを判定 if (hdiff[1] < 0) and (hdiff[2] < 0) and \ (hdiff[3] > 0) and (hdiff[4] > 0) and \ (h5d[2] < 0): # ボトムアウト hist_values = f'{h5d[0]:.1f},{h5d[1]:.1f},{h5d[2]:.1f},{h5d[3]:.1f},{h5d[4]:.1f}' print(f'{dates[i+2]:%Y-%m-%d} {code} ボトムアウト {hist_values}') elif (hdiff[1] > 0) and (hdiff[2] > 0) and \ (hdiff[3] < 0) and (hdiff[4] < 0) and \ (h5d[2] > 0): # ピークアウト hist_values = f'{h5d[0]:.1f},{h5d[1]:.1f},{h5d[2]:.1f},{h5d[3]:.1f},{h5d[4]:.1f}' print(f'{dates[i+2]:%Y-%m-%d} {code} ピークアウト {hist_values}')```
以下の出力結果が得られます。
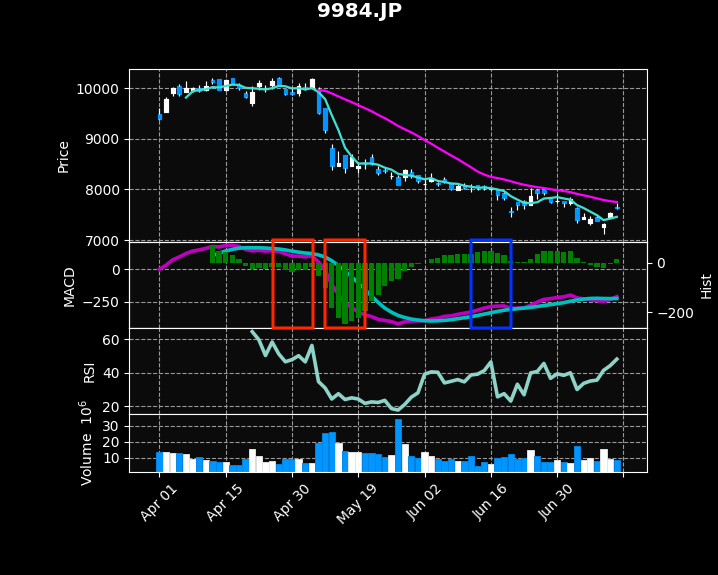
# 2021-04-30 9984.JP ボトムアウト -18.8,-30.0,-37.2,-30.4,-29.4 # 2021-05-17 9984.JP ボトムアウト -180.7,-221.7,-246.1,-234.2,-222.5 # 2021-06-16 9984.JP ピークアウト 41.9,45.6,47.1,40.6,32.8
参考までに、条件を2日連続ではなく1日とすると、ボトムアウト5回・ピークアウト5回という結果になります。
[4-2] チャート
出力結果をチャート上に示すと、赤枠と青枠の部分になります。
[4-3] 計算通りに売買したら成功したか
- 2021/04/30 ボトムアウトで買い:失敗
- 2021/05/17 ボトムアウトで買い:失敗
- 2021/06/16 ピークアウトで売り:成功
少なくとも今回の例では、良い結果が得られませんでした
[4-4] 条件を変えたらどうなるか
2日連続上昇後に減少の条件から「2日連続」を無くしてみます。
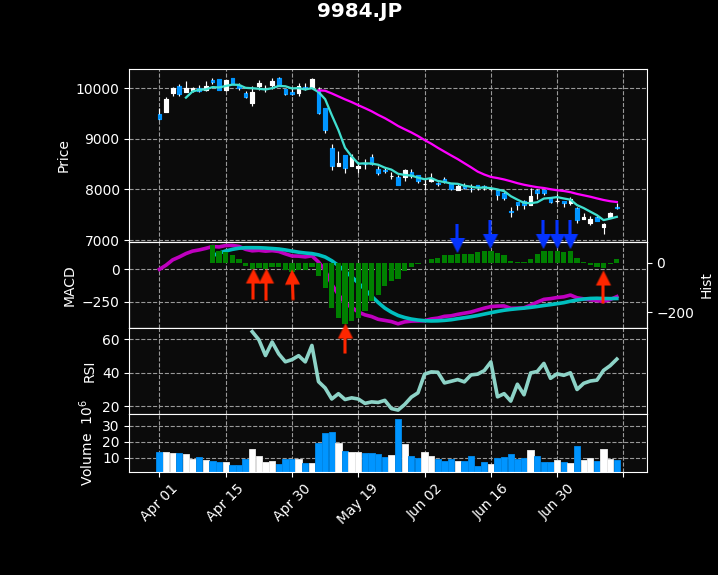
# 2021-04-21 9984.JP ボトムアウト -12.3,-23.9,-19.8 # 2021-04-23 9984.JP ボトムアウト -19.8,-23.8,-16.4 # 2021-04-30 9984.JP ボトムアウト -30.0,-37.2,-30.4 # 2021-05-17 9984.JP ボトムアウト -221.7,-246.1,-234.2 # 2021-06-07 9984.JP ピークアウト 20.9,30.9,29.9 # 2021-06-16 9984.JP ピークアウト 45.6,47.1,40.6 # 2021-06-28 9984.JP ピークアウト 33.4,47.1,45.9 # 2021-06-30 9984.JP ピークアウト 45.9,47.2,44.7 # 2021-07-02 9984.JP ピークアウト 44.7,46.8,17.1 # 2021-07-09 9984.JP ボトムアウト -17.9,-22.5,-6.9
売買のタイミングは判断できませんが、傾向を見るのには役立つかもしれません。ボトムアウト・ピークアウトは傾向を見るにとどめるのが良さそうです。
ソースコードは次の通りです。
# ヒストグラムと日付を取り出す hists = df['Hist'] dates = df.index # 日数分ループ for i in range(0, hists.size-3): # 3日分取り出し h3d = hists.iloc[i:i+3] # 日毎の差分を取得 hdiff = h3d.diff() # ボトムアウト・ピークアウトを判定 if (hdiff[1] < 0 < hdiff[2]) and (h3d[1] < 0): # ボトムアウト hist_values = f'{h3d[0]:.1f},{h3d[1]:.1f},{h3d[2]:.1f}' print(f'{dates[i+1]:%Y-%m-%d} {code} ボトムアウト {hist_values}') elif (hdiff[1] > 0 > hdiff[2]) and (h3d[1] > 0): # ピークアウト hist_values = f'{h3d[0]:.1f},{h3d[1]:.1f},{h3d[2]:.1f}' print(f'{dates[i+1]:%Y-%m-%d} {code} ピークアウト {hist_values}')
[5] RSI
RSIは70%以上だと買われすぎ、30%以下だと売られすぎと言われています。
- RSIが70%以上:買われすぎなので売りのタイミング
- RSIが30%以下:売られすぎなので買いのタイミング
詳しい説明は、下記サイト等を参考にしてみてください。
[5-1] ソースコード
単純にRSIの値で判断すれば良いので、これまで紹介した2つに比べてだいぶシンプルです。
# 日数分ループ for i, rsi in enumerate(df['RSI']): if rsi > 70: # RSI > 70% print(f'{df.index[i]} RSI>70% {rsi:.1f}') elif rsi < 30: # RSI < 30% print(f'{df.index[i]} RSI<30% {rsi:.1f}')
以下の出力結果が得られます。この例ではRSIが70%以上になりませんでした。
# 2021-05-13 00:00:00 RSI<30% 24.4 # 2021-05-14 00:00:00 RSI<30% 27.6 # 2021-05-17 00:00:00 RSI<30% 24.1 # 2021-05-18 00:00:00 RSI<30% 25.1 # 2021-05-19 00:00:00 RSI<30% 24.4 # 2021-05-20 00:00:00 RSI<30% 21.8 # 2021-05-21 00:00:00 RSI<30% 22.7 # 2021-05-24 00:00:00 RSI<30% 22.4 # 2021-05-25 00:00:00 RSI<30% 23.6 # 2021-05-26 00:00:00 RSI<30% 18.7 # 2021-05-27 00:00:00 RSI<30% 17.8 # 2021-05-28 00:00:00 RSI<30% 21.1 # 2021-05-31 00:00:00 RSI<30% 25.5 # 2021-06-17 00:00:00 RSI<30% 25.7 # 2021-06-18 00:00:00 RSI<30% 27.6 # 2021-06-21 00:00:00 RSI<30% 23.2 # 2021-06-23 00:00:00 RSI<30% 27.0
[5-2] チャート
出力結果をチャート上に示すと、赤線がRSI=30%のラインです。
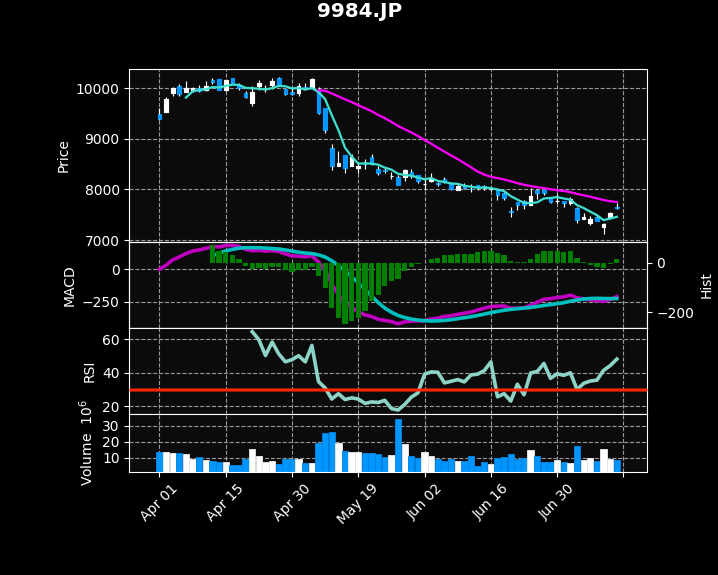
[5-3] 計算通りに売買したら成功したか
- 2021/05/13〜05/31 RSI<30%で買い:失敗
- 2021/06/17〜06/23 RSI<30%で買い:失敗
売られすぎ(RSI<30%)の期間が二度ありました。このタイミングで買っていたら、いずれも失敗でした。
RSIは横ばいの相場で有効と言われています。この例では下降トレンドであったため効力を発揮しなかったものと思われます。
[5-4] 別銘柄の場合はどうか
JR東日本(9020.JP)なら、どういう結果になったのか見てみます。

- 2021/04/21〜04/22 RSI<30%で買い:成功
- 2021/06/02〜06/14 RSI>70%で売り:成功
- 2021/06/29〜06/30 RSI<30%で買い:成功
逆に上手くいき過ぎていて気持ちが悪いです。
MACDを用いた指標で売買しても成功していました。
終わりに
テクニカル分析指標だけで売買を判断するは難しいようです。ですが、判断材料としては十分に使えそうです。
売買のタイミングを感情で左右してまうと失敗します。とくに慣れない頃はそうでした。客観的な指標も用いて、冷静に判断できればと思いました。
出典
【AWS】pythonでS3のファイルを操作する手順(Boto3)
pythonのプログラムからS3を操作する手順をまとめました。ファイルのアップロード/ダウンロードなど、基本的な手順を書いています。
- [1] 前提条件
- [2] 準備
- [3] Boto3を使った操作の概略
- [4] Boto3を使った操作の詳細
- 終わりに
- 補足
- 出典
[1] 前提条件
AWS EC2環境で実行する際の手順です。ライブラリとして「AWS SDK for Python (Boto3)」を使用しています。
- EC2
- Amazon Linux2
- Python3
- Boto3
[2] 準備
[2-1] boto3のインストール
pipを使ってインストールします。
pip3 install boto3 --user
Quickstart — Boto3 Docs 1.17.102 documentation
[2-2] EC2にIAMロールを付与する
詳細は末尾の補足に記載しますが、IAMロールを作成し、以下のIAMポリシーを適用します。作成したIAMロールをEC2インスタンスに設定します。
IAMポリシー以下の権限を付与しています。
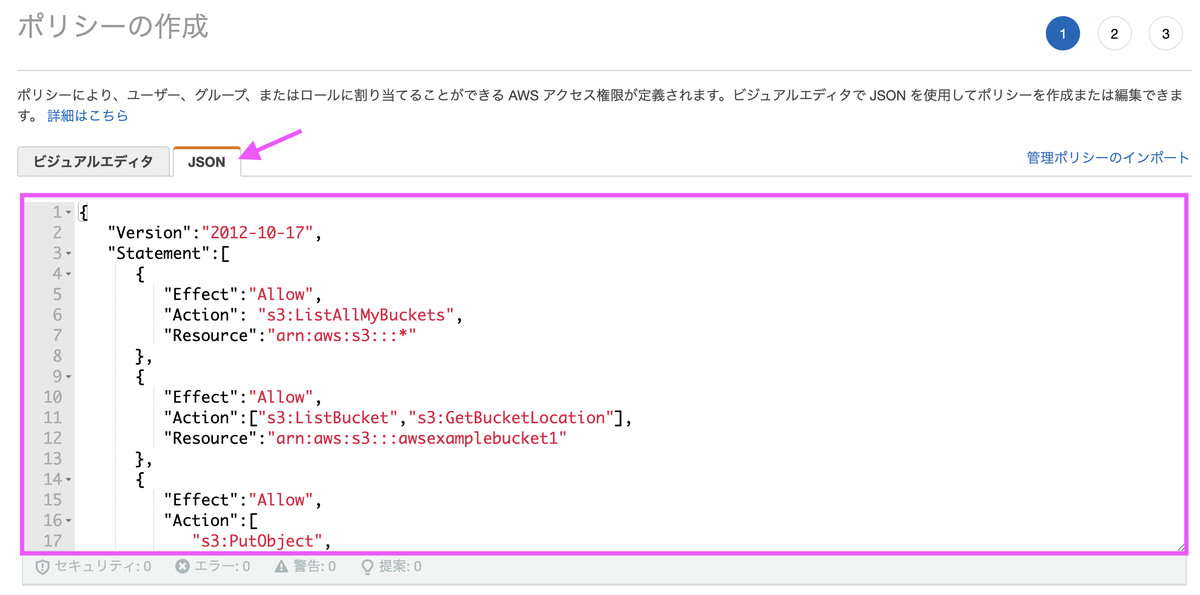
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ListAllBuckets", "Effect":"Allow", "Action": "s3:ListAllMyBuckets", "Resource":"arn:aws:s3:::*" }, { "Sid": "ListObjectsInBucket", "Effect": "Allow", "Action": ["s3:ListBucket","s3:GetBucketLocation"], "Resource": ["arn:aws:s3:::bucket-name"] }, { "Sid": "ObjectActions", "Effect": "Allow", "Action": ["s3:GetObject","s3:PutObject","s3:DeleteObject"], "Resource": ["arn:aws:s3:::bucket-name/*"] } ] }
IAMポリシーは下記資料を参考にしています。
- ユーザーポリシーの例 - Amazon Simple Storage Service
- Amazon S3: S3 バケットのオブジェクトへの読み取りおよび書き込みアクセスを許可する - AWS Identity and Access Management
[3] Boto3を使った操作の概略
やり方は色々とありますが、以下のソースコードで基本的なことは出来ます。
import boto3 BUCKET_NAME = 'bucket_name' # 全バケットを表示 s3 = boto3.resource('s3') for bucket in s3.buckets.all(): print(bucket.name) # バケット内の全オブジェクトを表示 bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.all() for obj in objects: print(obj.key) # オブジェクトをダウンロード bucket.download_file('input/file.txt', 'file.txt') # オブジェクトをアップロード bucket.upload_file('file.txt', 'output/file.txt') # オブジェクトを削除 s3.Object(BUCKET_NAME, 'output/file.txt').delete()
前半は全バケットの表示と、バケット内オブジェクトの表示です。後半はバケットからファイルをダウンロードし、別名でアップロードしたのち削除しています。
[4] Boto3を使った操作の詳細
boto3.resourceとboto3.client、2つの書き方があります。両者とも概ね同じことができるようになっています。
[4-1] 全バケットを表示
QuickStartに書いてあるソースコードです。非常に簡単です。
import boto3 s3 = boto3.resource('s3') for bucket in s3.buckets.all(): print(bucket.name)
Quickstart — Boto3 Docs 1.17.102 documentation
以下の書き方でも、同じことが実現できます。
s3 = boto3.client('s3') response = s3.list_buckets() print('Existing buckets:') for bucket in response['Buckets']: print(f' {bucket["Name"]}')
Amazon S3 buckets — Boto3 Docs 1.17.102 documentation
[4-2] バケット内のオブジェクトを表示
[4-2-1] 全オブジェクトを表示
boto3.resourceを使用した書き方は次の通りです。
BUCKET_NAME = 'bucket_name' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) for obj in bucket.objects.all(): print(obj.key)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientを使用した書き方は次の通りです。どちらを使用しても同じ出力結果が得られます。
BUCKET_NAME = 'bucket_name' s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME) for obj in response['Contents']: print(obj['Key'])
S3 — Boto3 Docs 1.17.102 documentation
例として以下のような出力結果が得られます。
# dir1/ # dir1/file1.txt # dir1/file2.txt # dir2/ # dir2/file3.csv # dir2/file4.txt # file5.csv
下記ファイル構成の場合の出力結果です。
bucket_name ├── dir1 │ ├── file1.txt │ └── file2.txt ├── dir2 │ ├── file3.csv │ └── file4.txt └── file5.csv
[4-2-2] Prefixに該当するオブジェクトを表示
指定したPrefixに該当するオブジェクトを表示することも可能です。
boto3.resourceを使用した書き方は以下の通りです。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.filter(Prefix='dir1') for obj in objects: print(obj.key) # dir1/ # dir1/file1.txt # dir1/file2.txt
boto3.clientを使用した書き方は以下の通りです。
s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME, Prefix='dir2') for obj in response['Contents']: print(obj['Key']) # dir2/ # dir2/file3.csv # dir2/file4.txt
[4-2-3] 階層化のオブジェクトのみ表示
Delimiterを使用することで階層直下のオブジェクトのみ表示します(再帰表示しない)。以下の例ではバケットの直下のみ表示しています。
boto3.resourceを使用した書き方は以下の通りです。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.filter(Delimiter='/') for obj in objects: print(obj.key) # file5.csv
boto3.clientを使用した書き方は以下の通りです。
s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME, Delimiter='/') for obj in response['Contents']: print(obj['Key']) # file5.csv
[4-2-4] Keyが1,000件以上になる場合の対処法
オブジェクト情報取得には制限があります。ワンオペレーションで取得できるKeyは最大で1,000件までです。1,000件を超えることが想定される場合、それを見越した処理が必要になります。
以下の処理では、テスト用に一度で5件までしか取得できないようにしています。MaxKeys=5です。Markerにキーを指定すると、そのキーの次のオブジェクトから取得します。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) marker = '' while True: # オブジェクト取得 objects = bucket.objects.filter(Marker=marker, MaxKeys=5) # オブジェクト表示 last_key = None for obj in objects: print(obj.key) last_key = obj.key # 最後のキーをMarkerにセットし次のオブジェクト取得を行う。 # オブジェクト取得が完了していたら終了。 if last_key is None: break else: marker = last_key
boto3.clientの場合、MarkerではなくContinuationTokenを使用します。
s3 = boto3.client('s3') # オブジェクト取得 response = s3.list_objects_v2(Bucket=BUCKET_NAME, MaxKeys=5) while True: # オブジェクト表示 for obj in response['Contents']: print(obj['Key']) # 'NextContinuationToken'が存在する場合は、次のデータ取得。 if 'NextContinuationToken' in response: token = response['NextContinuationToken'] response = s3.list_objects_v2(Bucket=BUCKET_NAME, MaxKeys=5, ContinuationToken=token) else: break
[4-2-5] resourceとclientで得られる情報の違い
上の例ではオブジェクトの「key」情報のみを取得していますが、他にも含まれる情報があります。そして、boto3.resourceとboto3.clientで持つ情報が若干異なります。
boto3.resourceで得られる情報は次の通りです。
# 〜〜〜(省略)〜〜〜 for obj in bucket.objects.all(): print(obj) # s3.ObjectSummary(bucket_name='bucket_name', key='dir1/') print(obj.bucket_name) # bucket_name print(obj.key) # dir1/ print(obj.e_tag) # "d41d8cd98f00b204e9800998ecf8427e" print(obj.last_modified) # 2021-06-30 09:28:47+00:00 print(obj.owner) # None print(obj.size) # 0 print(obj.storage_class) # STANDARD
boto3.clientで得られる情報は次の通りです。
# 〜〜〜(省略)〜〜〜 for obj in response['Contents']: print(obj) # {'Key': 'dir1/', # 'LastModified': datetime.datetime(2021, 6, 30, 9, 28, 47, tzinfo=tzlocal()), # 'ETag': '"d41d8cd98f00b204e9800998ecf8427e"', # 'Size': 0, # 'StorageClass': 'STANDARD'}
[4-3] バケットからファイルをダウンロード
[4-3-1] ファイルにダウンロード
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir1/file1.txt' FILE_NAME1 = 'file1.txt' s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).download_file(OBJECT_NAME1, FILE_NAME1)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME2 = 'dir1/file2.txt' FILE_NAME2 = 'file2.txt' s3 = boto3.client('s3') s3.download_file(BUCKET_NAME, OBJECT_NAME2, FILE_NAME2)
S3 — Boto3 Docs 1.17.103 documentation
[4-3-2] ファイルライクオブジェクトにダウンロード
ファイルを直接ダウンロードするだけで無く、ファイルライクオブジェクトへのダウンロードも可能です。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir2/file3.csv' FILE_NAME3 = 'file3.csv' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) with open(FILE_NAME3, 'wb') as f: bucket.download_fileobj(OBJECT_NAME3, f)
あまり使いどころが無いかもしれませんが、以下のように一時ファイルに出力する等が可能です。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir2/file3.csv' FILE_NAME3 = 'file3.csv' s3 = boto3.client('s3') with tempfile.NamedTemporaryFile(mode='wb') as f: s3.download_fileobj(BUCKET_NAME, OBJECT_NAME4, f) print(f.name) # /tmp/tmppjvqnyf5 print(f.tell) # <function BufferedWriter.tell at 0xffff90ff9290>
[4-4] バケットにファイルをアップロード
アップロードもダウンロードと同様の手順です。
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir3/file1.txt' FILE_NAME1 = 'file1.txt' OBJECT_NAME2 = 'dir3/file2.txt' FILE_NAME2 = 'file2.txt' s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).upload_file(FILE_NAME1, OBJECT_NAME1) s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) with open(FILE_NAME2, 'rb') as f: bucket.upload_fileobj(f, OBJECT_NAME2)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' FILE_NAME3 = 'file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' FILE_NAME4 = 'file4.txt' s3 = boto3.resource('s3') s3.meta.client.upload_file(FILE_NAME3, BUCKET_NAME, OBJECT_NAME3) s3 = boto3.client('s3') with open(FILE_NAME4, 'rb') as f: s3.upload_fileobj(f, BUCKET_NAME, OBJECT_NAME4)
S3 — Boto3 Docs 1.17.103 documentation
[4-5] バケットのオブジェクトを削除
[4-5-1] 単一オブジェクトの削除
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir3/file1.txt' s3 = boto3.resource('s3') s3.Object(BUCKET_NAME, OBJECT_NAME1).delete()
S3 — Boto3 Docs 1.17.105 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME2 = 'dir3/file2.txt' s3 = boto3.client('s3') s3.delete_object(Bucket=BUCKET_NAME, Key=OBJECT_NAME2)
S3 — Boto3 Docs 1.17.105 documentation
[4-5-2] 複数オブジェクトの削除
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) bucket.delete_objects( Delete={ 'Objects': [ {'Key': OBJECT_NAME3}, {'Key': OBJECT_NAME4} ] }, )
S3 — Boto3 Docs 1.17.105 documentation
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' s3 = boto3.client('s3') s3.delete_objects( Bucket=BUCKET_NAME, Delete={ 'Objects': [ {'Key': OBJECT_NAME3}, {'Key': OBJECT_NAME4} ] }, )
S3 — Boto3 Docs 1.17.105 documentation
終わりに
同じことをやるにも色々なやり方があり混乱しました。ですが、どの手順でも大きな差はありませんでした。手順自体も簡単なため、自分が使いやすいと思うものを使えばいいようです。
補足
[補足1] IAMロールをマネージメントコンソールで作成する手順
IAMロールを作成します。

ユースケースの選択で[S3]を選びます。
[ポリシーの作成]を選びます。
本文に記載したJSONを貼り付けます。バケット名はご自身のバケットの名称に置き換えます。
ポリシー名は任意の名称で構いません。

ロールの作成画面に戻ったら、作成したポリシーを割り当てます。更新ボタンを押してポリシー名を検索ボックスに入力すると、選択肢に出てきます。
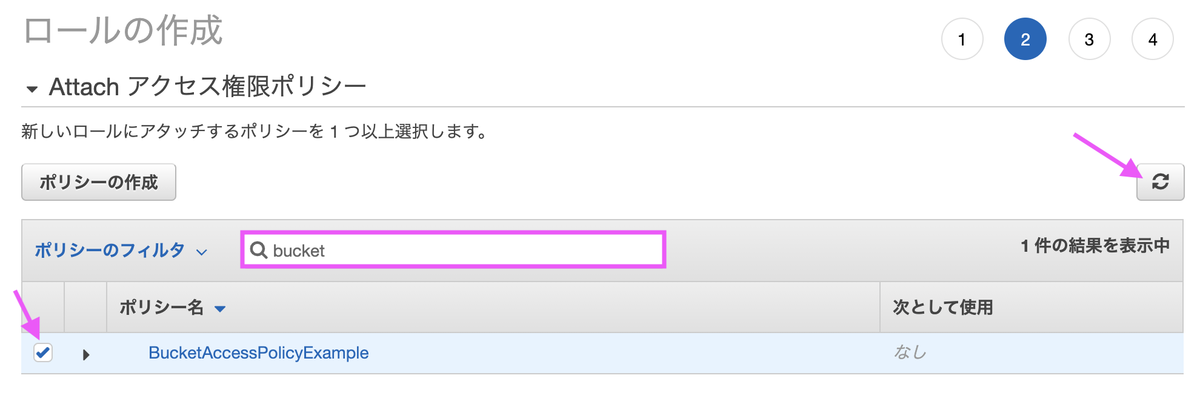
ロール名は任意の名称で構いません。

[補足2] IAMロールをCloudFormationで作成する場合
テンプレートファイルに以下の記述を追加します(Resourcesは元々書いてあるはずなので追加不要です)。長ったらしく感じますが「バケット名」以外は決まりきった書き方です。
Resources: # (...途中省略...) S3AccessRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "ec2.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" S3AccessPolicies: Type: AWS::IAM::Policy Properties: PolicyName: s3access PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - "s3:ListAllMyBuckets" - "s3:GetBucketLocation" Resource: "arn:aws:s3:::*" - Effect: Allow Action: - "s3:ListBucket" Resource: - "arn:aws:s3:::{バケット名}" - Effect: Allow Action: - "s3:GetObject" - "s3:PutObject" - "s3:DeleteObject" Resource: - "arn:aws:s3:::{バケット名}/*" Roles: - !Ref S3AccessRole S3AccessInstanceProfile: Type: AWS::IAM::InstanceProfile Properties: Path: "/" Roles: - !Ref S3AccessRole
追加した「S3AccessInstanceProfile」をEC2インスタンスと紐づければ終わりです。
# (...途中省略...) Instance: Type: AWS::EC2::Instance Properties: # (...途中省略...) IamInstanceProfile: !Ref S3AccessInstanceProfile
出典
アイキャッチはOpenClipart-VectorsによるPixabayからの画像