【Python】Face Recognitionで顔検出
「Face Recognition」というPythonの顔認識ライブラリを使い、顔検出を行いました。
中身は「dlib」なので、顔検出の精度は「dlib」と変わりませんが、顔認識に用途を絞ってより使いやすく作られています。
Face Recognition — Face Recognition 1.4.0 documentation
[1] Face Recognitionのインストール
pip3 install face_recognition --user
前提として「dlib」のインストールが必要です。インストール方法は、以前の記事で紹介した内容の通りです。
https://predora005.hatenablog.com/entry/2021/08/30/190000predora005.hatenablog.com
[2] ソースコード
公式のExample2つを参考にしています。検出期にCNNを使うか否か以外は同じ内容です。
- face_recognition/find_faces_in_picture.py at master · ageitgey/face_recognition · GitHub
- face_recognition/find_faces_in_picture_cnn.py at master · ageitgey/face_recognition · GitHub
顔検出だけであれば「dlib」のみインポートで十分ですが、検出領域の表示等で「OpenCV」を使用しています。
[2-1] HOG特徴量ベースの顔検出
import os import cv2 import face_recognition # 顔検出する画像のファイルリスト filelist = [ 'sample1.jpg', 'sample2.jpg', 'sample3.jpg'] imgdir = os.path.join(os.path.expanduser('~'), 'img') filepaths = [os.path.join(imgdir, file) for file in filelist] # HOG特徴量ベースの顔検出 for filepath in filepaths: # 画像読み込み image = face_recognition.load_image_file(filepath) # HOGベースモデルの顔検出実行 face_locations = face_recognition.face_locations(image) # 検出した領域を表示 print("------------------------------") print("I found {} face(s) in this photograph.".format(len(face_locations))) for face_location in face_locations: top, right, bottom, left = face_location print("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right)) # 顔検出した領域を短形表示した画像を保存 save_face_located_image(filepath, face_locations, 'hog')
[2-2] CNNモデルの顔検出
HOG特徴量ベースの検出と変わるのはface_recognition.face_locationsの引数のみです。model="cnn"と指定することでCNNによる顔検出が行われます。
number_of_times_to_upsampleはアップサンプリングの回数です。デフォルトは1です。
# ここまではHOG特徴量ベースの検出と同じ # 学習済みCNNモデルによる顔検出 for filepath in filepaths: # 画像読み込み(HOG特徴量ベースの検出と同じ) image = face_recognition.load_image_file(filepath) # CNNベースモデルの顔検出実行 face_locations = face_recognition.face_locations( image, number_of_times_to_upsample=1, model="cnn") # 検出した領域を表示(HOG特徴量ベースの検出と同じ) print("------------------------------") print("I found {} face(s) in this photograph.".format(len(face_locations))) for face_location in face_locations: top, right, bottom, left = face_location print("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right)) # 顔検出した領域を短形表示した画像を保存 save_face_located_image(filepath, face_locations, 'cnn')
[2-3] 顔検出した領域を短形表示した画像を保存
上記ソースコードで使用したsave_face_located_imageのソースコードは以下の通りです。
画面に表示できる環境であれば、わざわざ保存せず表示する方が簡単です。dlib, Pillow, OpenCVなどを使えば表示することは可能です。
def save_face_located_image(filepath, face_locations, prefix): # 保存用の画像データを準備 save_img = cv2.imread(filepath) # 検出した範囲を保存用画像に短形表示 for face_location in face_locations: y1, x2, y2, x1 = face_location cv2.rectangle(save_img, (x1, y1), (x2, y2), color=(0,0,255), thickness=4) # 検出領域を示した画像を保存 filename = os.path.basename(filepath) filedir = os.path.dirname(filepath) save_filename = prefix + '_' + filename save_imgpath = os.path.join(filedir, save_filename) cv2.imwrite(save_imgpath, save_img)
[3] 顔検出の結果
中身が「dlib」なので検出精度は変わりません。以前紹介した記事と同じ画像で検出を行っても、同じ結果になります。
- https://predora005.hatenablog.com/entry/2021/08/30/190000
- https://predora005.hatenablog.com/entry/2021/09/02/190000
以前紹介したものとは異なる画像で検出を行ってみます。
[3-1] HOG特徴量ベースの検出結果
 <青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
<青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
 <jswashburnによるPixabayからの画像>
<jswashburnによるPixabayからの画像>
 <Joseph MuciraによるPixabayからの画像>
<Joseph MuciraによるPixabayからの画像>
[3-2] CNNモデルの検出結果
 <青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
<青空の下、スマホで記念写真3 - No: 315218|写真素材なら「写真AC」無料(フリー)ダウンロードOK>
 <jswashburnによるPixabayからの画像>
<jswashburnによるPixabayからの画像>
 <Joseph MuciraによるPixabayからの画像>
<Joseph MuciraによるPixabayからの画像>
終わりに
「Face Recognition」は「dlib」ベースです。「dlib」と精度は変わりませんが、より簡単に顔検出ができるようになっていました。
顔検出や顔認識をするのであれば「Face Recognition」を使うのが、精度も良くお手軽だと思います。
参考文献
画像の出典
【Python】dlibで顔検出(CNN版)
前回紹介した「dlib」の顔検出のうち、CNN版で顔検出を行いました。
前回、dlibで顔検出を行いOpenCVよりも精度は向上しました。しかしながら、横顔の検出などには課題が残りました。
https://predora005.hatenablog.com/entry/2021/08/30/190000predora005.hatenablog.com
CNN版を使用した結果を先に言うと、処理時間が長くなるものの精度は向上しました。

[1] 事前準備
[1-1] dlibのインストール
前回紹介した内容と同様です。
https://predora005.hatenablog.com/entry/2021/08/30/190000https://predora005.hatenablog.com/entry/2021/08/30/190000
[1-2] 顔検出器のダウンロード
学習済みのモデルをダウンロードし、解凍します。
curl -O http://dlib.net/files/mmod_human_face_detector.dat.bz2 bzip2 -d mmod_human_face_detector.dat.bz2
[2] ソースコード
公式のExampleを元に作成しています。
dlib/cnn_face_detector.py at master · davisking/dlib · GitHub
顔検出だけであれば「dlib」のみインポートで十分ですが、検出領域の表示等で「OpenCV」を使用しています。
mport os import cv2 import dlib # 顔検出器を取得 detector_file = 'mmod_human_face_detector.dat' detector_path = os.path.join(os.path.expanduser('~'), detector_file) cnn_face_detector = dlib.cnn_face_detection_model_v1(detector_path) # 読み込むファイルのリスト filelist = [ 'sample1.jpg', 'sample2.jpg', 'sample3.jpg'] for file in filelist: print("------------------------------") print("Processing file: {}".format(file)) # 画像を読み込み imgdir = os.path.join(os.path.expanduser('~'), 'img') imgpath = os.path.join(imgdir, file) img = dlib.load_rgb_image(imgpath) # 顔検出を実行 dets = cnn_face_detector(img, 1) # 検出した領域を出力 print("Number of faces detected: {}".format(len(dets))) for i, d in enumerate(dets): print("Detection {}: Left: {} Top: {} Right: {} Bottom: {} Confidence: {}".format( i, d.rect.left(), d.rect.top(), d.rect.right(), d.rect.bottom(), d.confidence)) # 保存用の画像データを準備 save_img = cv2.imread(imgpath) # 検出した範囲を保存用画像に短形表示 for d in dets: x1, y1, x2, y2 = d.rect.left(), d.rect.top(), d.rect.right(), d.rect.bottom() cv2.rectangle(save_img, (x1, y1), (x2, y2), color=(0,0,255), thickness=4) # 検出領域を示した画像を保存 save_file = 'dlib_cnn_' + file save_imgpath = os.path.join(imgdir, save_file) cv2.imwrite(save_imgpath, save_img)
[3] 顔検出の結果
以前に紹介したOpenCVと同じ画像で、顔検出を行いました。
https://predora005.hatenablog.com/entry/2021/08/23/190000predora005.hatenablog.com
[3-1] OpenCVでも上手くいった例

OpenCVと同様に、上手く検出できています。
[3-2] OpenCVでは微妙だった例
 <Werner HeiberによるPixabayからの画像>
<Werner HeiberによるPixabayからの画像>
CNN版では6人中5人まで検出できています。OpenCVでは6人中3人の検出、dlibでは6人中4人の検出でした。
[3-3] OpenCV, dlibでは上手くいかなかった例
OpenCV, dlibともに1人しか検出できていませんでしたが、CNN版では4人まで検出できています。
[4] 補足とトラブルシューティング
[4-1] Memory Error
t3.medium(メモリ 4GiB)では足りませんでした。r5.large(メモリ 16GiB)では足りました。
MemoryError: std::bad_alloc
終わりに
CNN版を用いることで、精度が大きく向上しました。
一方、精度が向上したトレードオフとして、処理時間が長くなり、メモリ使用量が増大しました。
マシンスペックがそれなりに無いと動きません。小スペックの場合にはCNNではない、顔検出器を用いるのが良さそうです。
参考文献
画像の出典
- ゆうせい モデルの紹介 - ぱくたそ
- Werner HeiberによるPixabayからの画像
- Sanu A SによるPixabayからの画像
【Python】dlibで顔検出
dlibで顔検出を行いました。dlibは機械学習を始め様々な機能が含まれたライブラリです。
検出精度はOpenCVよりも若干良く、横向きの顔もある程度検出できています。

[1] dlibのインストール
dlibインストール前にgcc, CMakeをインストールします。
sudo yum -y install gcc gcc-c++ sudo yum -y install cmake
インストール完了後にdlibをインストールします。インストール完了までに数十分かかりました。
pip3 install dlib --user
[2] ソースコード
公式のExampleを元に作成しました。
dlib/face_detector.py at master · davisking/dlib · GitHub
顔検出だけであれば「dlib」のみインポートで十分ですが、検出領域の表示等で「OpenCV」を使用しています。
import os import cv2 import dlib # 顔検出器を取得 detector = dlib.get_frontal_face_detector() # 読み込むファイルのリスト filelist = [ 'sample1.jpg', 'sample2.jpg', 'sample3.jpg'] for file in filelist: print("------------------------------") print("Processing file: {}".format(file)) # 画像を読み込み(画像はホーム下のimgディレクトリに置く想定) imgdir = os.path.join(os.path.expanduser('~'), 'img') imgpath = os.path.join(imgdir, file) img = dlib.load_rgb_image(imgpath) # 顔検出(第二引数はアップサンプリング(拡大)の回数) dets = detector(img, 1) print("Number of faces detected: {}".format(len(dets))) # 検出した範囲を表示 for i, d in enumerate(dets): print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format( i, d.left(), d.top(), d.right(), d.bottom())) # 検出した範囲を短形表示し、別画像として保存 save_img = cv2.imread(imgpath) # 検出した範囲を保存用画像に短形表示 for d in dets: x1, y1, x2, y2 = d.left(), d.top(), d.right(), d.bottom() cv2.rectangle(save_img, (x1, y1), (x2, y2), color=(0,0,255), thickness=4) # 別名ファイルで保存 save_file = 'dlib_' + file save_imgpath = os.path.join(imgdir, save_file) cv2.imwrite(save_imgpath, save_img)
[3] 顔検出の結果
以前に紹介したOpenCVと同じ画像で、顔検出を行いました。
https://predora005.hatenablog.com/entry/2021/08/23/190000predora005.hatenablog.com
[3-1] OpenCVでも上手くいった例

OpenCVと同様に、上手く検出できています。
[3-2] OpenCVでは微妙だった例
<Werner HeiberによるPixabayからの画像>
OpenCVでは6人中3人の検出でした。OpenCVに比べると若干よくなっています。
[3-3] OpenCVでは上手くいかなかった例

OpenCVでも1人しか検出できていませんでしたので、OpenCVと同じ結果でした。
[4] 補足とトラブルシューティング
[4-1] ERROR: CMake must be installed to build dlib
gcc, CMakeをインストールせずに、dlibをインストールしようと以下のエラーが発生します。
ERROR: CMake must be installed to build dlib
gcc, CMakeをインストールすれば解決します。
sudo yum -y install gcc gcc-c++ sudo yum -y install cmake
[4-2] 検出スコアの表示
公式のExampleには、顔検出のスコアを表示方法も載っています。
detector.run()を用いることでスコアを表示します。
また、第三引数が閾値のため負値にすることで、検出する領域を意図的に増やしています。
for file in filelist: print("------------------------------") print("Processing file: {}".format(file)) # 画像を読み込み imgdir = os.path.join(os.path.expanduser('~'), 'img') imgpath = os.path.join(imgdir, file) img = dlib.load_rgb_image(imgpath) # 検出結果のスコアを表示(第三引数は閾値。デフォルトは0.0) dets, scores, idx = detector.run(img, 1, -1) for i, d in enumerate(dets): # idxは、どのサブ検出器にマッチしたか print("Detection {}, score: {}, face_type:{}".format( d, scores[i], idx[i]))
以下のような結果が出力されます。
------------------------------ Processing file: sample1.jpg Detection [(134, 206) (455, 527)], score: 0.5904139076373007, face_type:2 Detection [(141, 498) (409, 766)], score: -0.7469268450893916, face_type:3 Detection [(125, 1010) (161, 1046)], score: -0.7642095983401345, face_type:4 Detection [(55, 305) (98, 348)], score: -0.815978666673002, face_type:2 Detection [(573, 870) (609, 906)], score: -0.9177183116772745, face_type:2 Detection [(270, 171) (345, 246)], score: -0.939228042476612, face_type:1 ------------------------------ Processing file: sample2.jpg Detection [(101, 147) (152, 199)], score: 2.2398508228792067, face_type:0 Detection [(210, 49) (262, 101)], score: 2.1349826012916986, face_type:1 Detection [(325, 55) (377, 107)], score: 1.57835485089497, face_type:1 Detection [(446, 153) (498, 205)], score: 1.0782284890480462, face_type:1 Detection [(561, 106) (597, 142)], score: -0.8876646961072061, face_type:2 Detection [(461, 138) (497, 174)], score: -0.9027303159609841, face_type:4 Detection [(255, 295) (344, 385)], score: -0.9184605087140176, face_type:2 Detection [(381, 300) (424, 343)], score: -0.9242407641874437, face_type:0 Detection [(193, 337) (245, 389)], score: -0.9605490173199747, face_type:2 ------------------------------ Processing file: sample3.jpg Detection [(299, 89) (343, 132)], score: 2.0312632118365195, face_type:2 Detection [(596, 285) (648, 337)], score: -0.6916471923688028, face_type:2 Detection [(96, -13) (185, 86)], score: -0.8069736323820238, face_type:0 Detection [(487, 118) (538, 170)], score: -0.8929136693850563, face_type:4 Detection [(497, 20) (605, 128)], score: -0.9076731051139411, face_type:1 Detection [(103, 152) (211, 259)], score: -0.9933327138796852, face_type:4
[4-3] Memory Error
t3.medium(メモリ 1GiB)では足りませんでした。t3.medium(メモリ 4GiB)では足りました。
MemoryError: std::bad_alloc
終わりに
dlibではOpenCVよりも若干ですが、精度の良い顔検出が行えました。
とは言え、横顔の検出精度はまだまだでした。やはりディープラーニング等の機械学習を使った方が、精度が出るのかなという印象でした。
参考文献
画像の出典
- ゆうせい モデルの紹介 - ぱくたそ
- Werner HeiberによるPixabayからの画像
- Sanu A SによるPixabayからの画像
【Python】OpenCVで顔検出
OpenCVはインストールも簡単で、ひとまず顔検出を試すにはもってこいです。
正面以外の検出精度は微妙ですが、正面の顔を検出するなら十分です。短時間かつ低精度で構わないの場面で用いるのが良いでしょう。

[1] OpenCVのインストール
pip3 install opencv-python --user
上記だけではインポートエラーが発生するため「mesa-libGL」をインストールします。
sudo yum -y install mesa-libGL
詳しくは以下の記事にまとめています。
[2] ソースコード
公式のDocumentationを元に作成しました。
公式の例ではカメラから画像を取り込んでいますが、ここではダウンロード済みの画像を扱う例を紹介します。
import cv2 import os # サンプルデータのパスを追加 homedir = os.path.expanduser('~') cv2dir = '.local/lib/python3.7/site-packages/cv2/' cv2path = os.path.join(homedir, cv2dir) cv2.samples.addSamplesDataSearchPath(cv2path) # サンプル分類器を取得 face_cascade_name = 'data/haarcascade_frontalface_alt.xml' eyes_cascade_name = 'data/haarcascade_eye_tree_eyeglasses.xml' face_cascade = cv2.CascadeClassifier() eyes_cascade = cv2.CascadeClassifier() face_cascade.load(cv2.samples.findFile(face_cascade_name)) eyes_cascade.load(cv2.samples.findFile(eyes_cascade_name)) # 画像を読み込み(imgディレクトリにsample.jpgを置く) imgdir = 'img' imgpath = os.path.join(imgdir, 'sample.jpg') img = cv2.imread(imgpath) # 画像をグレースケールに変換 img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 顔検出 faces = face_cascade.detectMultiScale(img_gray) for face in faces: # 顔検出した領域を赤枠で描画 xf, yf, wf, hf = face cv2.rectangle(img, (xf, yf), (xf+wf, yf+hf), color=(0,0,255), thickness=4) # 顔検出した領域から、目を検出 face_img = img[yf:yf+hf, xf:xf+wf] eyes = eyes_cascade.detectMultiScale(face_img) for eye in eyes: # 目を検出した領域を緑楕円で描画 xe, ye, we, he = eye eye_center = (xf + xe + we//2, yf + ye + he//2) cv2.ellipse(img, eye_center, axes=(we//2, he//2), angle=0, startAngle=0, endAngle=360, color=(0, 255, 0), thickness=4) # 検出領域を示した画像を表示 cv2.imshow('Capture - Face detection', img)
[3] 顔検出の結果
[3-1] 非常に上手くいった例
赤枠が顔検出した領域、緑枠が顔検出した領域内から目を検出した領域です。
これは非常に上手くいった例です。正面の顔であれば、このように高精度で検出してくれます。
[3-2] すこし微妙な例

<Werner HeiberによるPixabayからの画像>
6人中3人を顔検出できています。顔が正面以外の向きだと、検出精度が下がります。
[3-3] 上手くいかない例

5人中1人しか顔検出できていません。顔が正面以外の向きだと、検出精度が下がります。
[4] 補足とトラブルシューティング
[4-1] 検出器の種類
検出器は、OpenCVで用意されたものを利用しています。
Amazon Linux2の環境では/home/{ユーザ名}/.local/lib/python3.7/site-packages/cv2/dataに格納されています。
顔検出以外にも様々な分類器が用意されています。
ls /home/{ユーザ名}/.local/lib/python3.7/site-packages/cv2/data # haarcascade_eye_tree_eyeglasses.xml haarcascade_licence_plate_rus_16stages.xml # haarcascade_eye.xml haarcascade_lowerbody.xml # haarcascade_frontalcatface_extended.xml haarcascade_profileface.xml # haarcascade_frontalcatface.xml haarcascade_righteye_2splits.xml # haarcascade_frontalface_alt2.xml haarcascade_russian_plate_number.xml # haarcascade_frontalface_alt_tree.xml haarcascade_smile.xml # haarcascade_frontalface_alt.xml haarcascade_upperbody.xml # haarcascade_frontalface_default.xml __init__.py # haarcascade_fullbody.xml __pycache__ # haarcascade_lefteye_2splits.xml
各ファイルの役割は下記サイトなど、いくつかのサイトがまとめてくれています。
【Python版OpenCV】Haar Cascadeで顔検出、アニメ顔検出、顔にモザイク処理 | 西住工房
[4-2] 検出器の読込失敗
用意された検出器を読み込もうとすると、ファイルが見つからないエラーが発生します。
face_cascade_name = 'data/haarcascade_frontalface_alt.xml' face_cascade = cv.CascadeClassifier() face_cascade.load(cv.samples.findFile(face_cascade_name)) # OpenCV(4.5.3) /tmp/pip-req-build-l1r0y34w/opencv/modules/core/src/utils/samples.cpp:64: error: (-2:Unspecified error) OpenCV samples: Can't find required data file: data/haarcascade_frontalface_alt.xml in function 'findFile'
cv2.samples.addSamplesDataSearchPath()で格納先のパスを検索するようにします。
import os homedir = os.path.expanduser('~') cv2dir = '.local/lib/python3.7/site-packages/cv2/' cv2path = os.path.join(homedir, cvdir) cv2.samples.addSamplesDataSearchPath(cv2path)
OpenCV: Utility functions for OpenCV samples
[4-3] 検出器のパラメータ
検出器のパラメータを調整すること精度を高めることができます。
CascadeClassifier.detectMultiScale()のパラメータを変更します。主なパラメータは次の通りです。
- scaleFactor:各画像スケールにおいて、画像サイズをどれだけ縮小するかを指定するパラメータ。
- minNeighbors:各候補の矩形が保持されるために必要な隣接数を指定するパラメータ。
- minSize:可能なオブジェクトの最小サイズ.これよりも小さいオブジェクトは無視されます.
OpenCV: cv::CascadeClassifier Class Reference
詳細は以下のサイトなどが参考になります。
- [OpenCV] detectMultiScaleの使いかた | Tech控え帳
- 物体検出(detectMultiScale)をパラメータを変えて試してみる(scaleFactor編) | Workpiles
[4-4] 検出の仕組み
Haar特徴に基づくカスケード分類器で顔検出を行なっています。
公式のチュートリアルや以下のサイトが詳しいです。
- OpenCV: Cascade Classifier
- 【入門者向け解説】openCV顔検出の仕組と実践(detectMultiScale) - Qiita
- Haar Cascadeによる顔検出の原理 | 西住工房
終わりに
冒頭で述べた通り、OpenCVはインストールも比較的容易で簡単に顔検出ができました。しかし、精度は少々物足りません。
OpenCVよりも精度の良いライブラリを探してみることにします。
参考文献
- 【入門者向け解説】openCV顔検出の仕組と実践(detectMultiScale) - Qiita
- 【Python版OpenCV】Haar Cascadeで顔検出、アニメ顔検出、顔にモザイク処理 | 西住工房
- [OpenCV] detectMultiScaleの使いかた | Tech控え帳
- 物体検出(detectMultiScale)をパラメータを変えて試してみる(scaleFactor編) | Workpiles
- Python + OpenCVで顔検出を行う
画像の出典
- ゆうせい モデルの紹介 - ぱくたそ
- Werner HeiberによるPixabayからの画像
- Sanu A SによるPixabayからの画像
【政府統計】日本人の寿命と死因(年次推移や年齢別割合など)
「LIFE SPAN」を読んで、老化・長寿の研究が進んでいることを以前に紹介しました。寿命や死因に興味が沸いたので、政府統計をもとに調べました。
https://predora005.hatenablog.com/entry/2021/08/09/190000predora005.hatenablog.com
[1] 平均寿命の推移
以下は、厚生労働省の資料を引用した資料になります。周知の通り、戦後以降の平均寿命は延び続けてきました。2040年には現在よりもさらに2年平均寿命が延びる予想になっています。
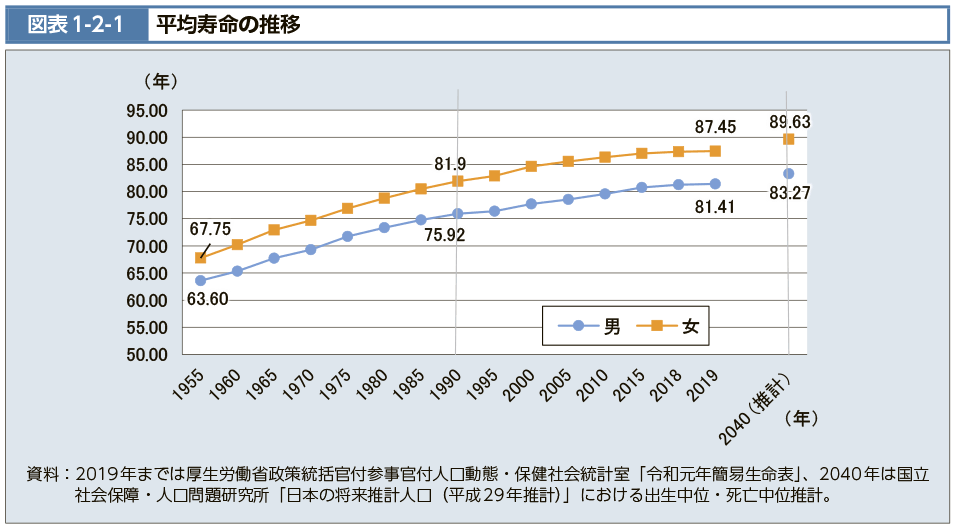
<図表1-2-1 平均寿命の推移|令和2年版厚生労働白書-令和時代の社会保障と働き方を考える-|厚生労働省より引用>
[2] 年齢別の死亡率
令和元年簡易生命表によると、2019年の年齢別死亡率は次の通りでした。
生命表 簡易生命表 | データベース | 統計データを探す | 政府統計の総合窓口
[2-1] 全年齢
年齢を重ねるに応じて、指数関数的に増えています。

0歳〜60歳
0歳(出生後)の死亡率は高いですが、それ以外は年齢を重ねるつれて徐々に上昇します。
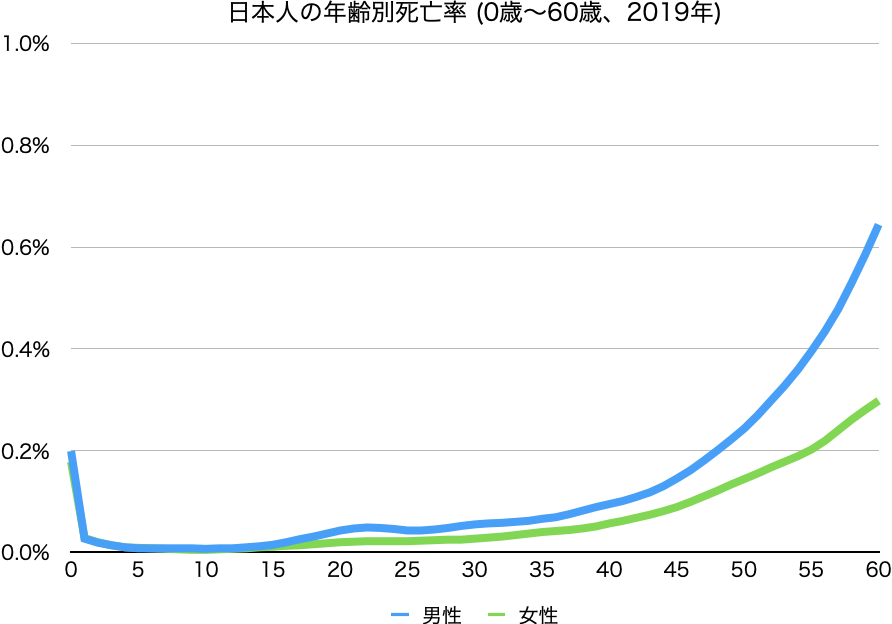
60歳〜
60歳では1%に満たないですが、80歳になると男性が8.2%、女性が4.5%とだいぶ高くなっています。90歳では、男性が14.5%、女性が9.3%です。

[3] 死因
人口動態調査の表5-12から、1,899年以降のデータを見ることができました。
人口動態調査 人口動態統計 確定数 死亡 年次 2019年 | ファイル | 統計データを探す | 政府統計の総合窓口
[3-1] 死因別死亡者数の年次推移
人口の増加に伴い死亡者数は増えていますが、死因の割合には変化があります。
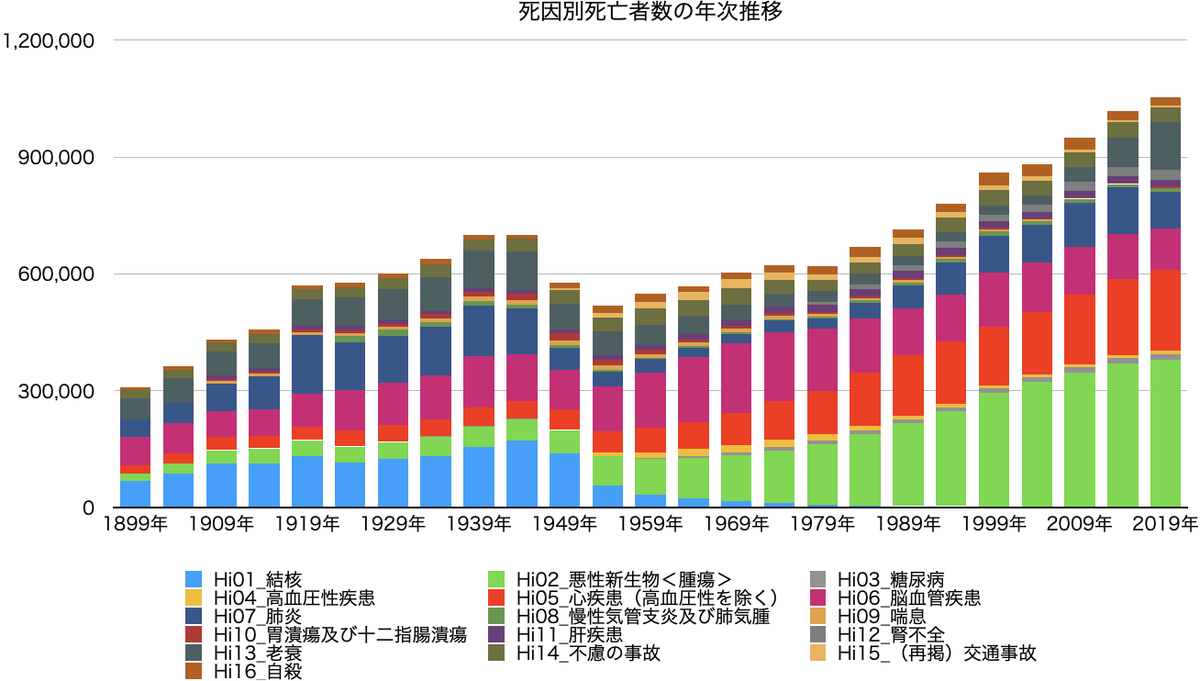
結核、脳血管疾患は減っています。一方、悪性新生物(がん)、老衰は増えています。肺炎は増加傾向でしたが最近は減少しています。
[3-2] 死因の割合(2019年)
2019年の死因上位は上から順に、悪性新生物(がん)、心疾患、老衰、脳血管疾患、肺炎となっています。

[3-3] 死因別死亡率の年次推移
以下のグラフは、人口10万に占める死亡者数の割合です。

参考文献・引用元データ
- 図表1-2-1 平均寿命の推移|令和2年版厚生労働白書-令和時代の社会保障と働き方を考える-|厚生労働省
- 生命表 簡易生命表 | データベース | 統計データを探す | 政府統計の総合窓口
- 人口動態調査 人口動態統計 確定数 死亡 年次 2019年 | ファイル | 統計データを探す | 政府統計の総合窓口
出典
【読書】寿命が延びた先にある未来
前回・前々回に引き続き「LIFE SPAN」の自分用のメモとしての要点まとめです。
https://predora005.hatenablog.com/entry/2021/08/11/190000predora005.hatenablog.com
第3部は未来の話です。健康寿命が延びることによる社会・経済への影響について語られています。
私は、生活や経済のシステムは長寿社会に適した形へ徐々に移行できると思います。ただ、移行の過程で、得をする人もいれば損をする人もいるだろうという不安はあります。
また、世代交代がなかなか起きないことへの不安も感じました。本書にもある通り政治家の顔ぶれが変わらないというのは有り得る話でしょう。それは政治家に限らず様々な組織においても起こりうると思います。
ただ、健康寿命が延びることには良い面もあります。現在は医療の発展もあり、不健康な状態に苦しみながら余生を十数年過ごし、亡くなる方も増えています。健康寿命が延びることで、亡くなる直前まで健康に過ごせる未来があるかもしれません。
第3部(未来)
長寿社会に対して誰もが抱く不安
- 地球が抱えきれる人口には限りがあり、人口の急増により食料不足や資源不足が起きると考える者も多い。
- 人類は環境を破壊し急速な地球温暖化を進めた。寿命が長くなれば人口が増え、環境破壊が進む。
100年辞めない政治家が牛耳る世界
- 現代は昔に比べて、優しく寛容で公正で、より多様性を受け入れる場所へと変貌してきた。その原動力は、人間が長くは生きないということ。旧来の見方に頑なにしがみついていた者が世を去ることで、新しい価値観が花開いてきた。
- 人間の寿命は長いため、文化や思想の進化には数十年を要してきた。
- ナショナリズムへの回帰は、高齢者の数と割合の増加が影響しているという見方がある。
- 高齢の有権者は高齢の政治家を支持する傾向にある。
- 数の多い高齢の有権者が長生きすれば、政治家の顔ぶれが変わらなくなる。
富裕層がより長生きする
- アメリカ人の収入上位10%は下位10%より13年長生きする(2018年時点)
- 富裕層の方が健康や医療に投資できる。健康を保ったまま長生きし、より一層の資産を蓄積することになる。
- 富裕層が長生きする影響は政治にも及ぶ。お金を持つ富裕層の政治への影響力が長期間にわたって及ぶ。
寿命を延ばすことは不自然か
- より良い暮らしを送るためにできることには限界がある、という考えを受け入れることの方が不自然。そのような発想は、人類の歴史が始まって以来現れていない。
- 寿命を延ばすことが不自然なら、文化や科学技術も不自然ということになる。
未来を悲観するのは恵まれていることの裏返し
- この先世界は良くなっていくと思うかという質問に「良くなる」と答えた人の割合は、先進国では少ないが、それ以外の国では多い。
- 中国、ブラジル、ロシア、インド、トルコなどでは未来を明るいものと捉える傾向が高い。生活水準が上向けば、貧困率が減少し、きれいな水や電気が利用しやすくなる。食料や住居も安定して確保できるようになり、医療も受けやすくなる。
- 過去100年で、子供の死亡率は36%から8%に減り、識字率は21%から80%に増えている。
高齢者が活躍できる社会へ
- 仕事の現場において、年齢による差別が蔓延している。高齢の労働者は病気になりやすく、仕事が遅く、新しいテクノロジーを扱えないと決めてかかっている。特に、指導者の立場にある人や経営者については当てはまらない。
- 定年退職する人がいなければ、若い労働者が仕事から締め出されると心配する人は大勢いる。
- 昔の人が恐れていたのは「人が多すぎて資源が不足する」か「人が多すぎて仕事が足りなくなる」か。1963年には、自動化が人間にとって変わり多くの人が職を追われると考えていた。しかし、現実はそうならなかった。
老化を遅らせることによる経済効果
- 現状では高齢化は経済にとって二重の打撃。病気になった人は経済活動が行えず、多額の医療費を必要とする。
- 健康寿命が延び、高齢者がもっと長く働けるようになったら経済面での打撃は緩和される。
- 医療費が削減されれば、科学研究や教育に予算が回せるようになる
出典
【読書】老化・長寿研究の現在
前回に引き続き「LIFE SPAN」の自分用のメモとしての要点まとめです。
https://predora005.hatenablog.com/entry/2021/08/09/190000predora005.hatenablog.com
前回は第1部-過去、これまでに分かっている老化の仕組みについてでした。第2部は現在です。現在といっても少し先の未来も含まれます。
老化に効く薬・成分については、私は半信半疑です。現時点では信じるでもなく否定するわけでもないというスタンスです。
面白かったのは少し未来の話で、第6章後半と第7章の内容です。老化治療が発展した先にある課題・倫理的問題が興味深かったです。細胞リプログラミングや臓器移植のドナー問題など。科学技術でブレイクスルーが起きる際に発生する倫理的問題や法整備、議論の必要性は、AIや自動運転と同じだと感じました。
また、第4章 : 長寿遺伝子を働かせる方法については素直に賛同できました。老化・長寿との関係は置いとくとしても、純粋に健康のために良いと思いました。
第2部(現在)
第4章 : 長寿遺伝子を働かせる方法
食事量を減らすと長生きする
間欠的断食
- 食事を抜く期間を周期的に差し挟む
- 朝食を抜いて遅い昼食を取る(16:8ダイエット)
- 週に2日はカロリーを75%に減らす(5:2ダイエット)
- 週に2,3日は食物をいっさい摂らない(イート・ストップ・イート法)
アミノ酸を制限する
- アミノ酸を摂取しないと人間は死ぬ。肉類には9つの必須アミノ酸がすべて含まれるエネルギー源だが代償を伴う。
- 動物性タンパク質に偏った食生活は、心血管系疾患による死亡率と癌の発症率が共に高まる
- 特に加工した赤身肉は発癌性が高いことが指摘されている。
運動する人ほどテロメアが長い
- 運動がテレメアの短縮を遅らせる。
- 運動とは体にストレスを与えること。運動をするとNADの濃度が上昇しサバイバルネットワークを作動させる。
- エネルギーの産生量が上がり、筋肉は酸素を運ぶ毛細血管をさらに増やすようになる。
- 新しい血管をつくらせ、心臓や肺を健康にし、体を丈夫にし、テロメアを長くする。
必要な運動強度
- 週に4〜5マイル(約6.5〜8km)走るだけでも、心臓発作で命を落とすリスクが45%減り、全死因死亡率が30%下がる。
- 健康を増進する遺伝子を一番多く活性化したのは「高強度インターバルトレーニング(HITT)」。HITTは高強度な短時間の運動と休憩を繰り返す。
寒さに身をさらして長寿遺伝子を働かせる
- 体温を一定に保てる環境の温度範囲を「熱的中性圏」と呼ぶ。この範囲から外れるとサバイバル回路が動く。とりわけ気温が低いときに顕著に現れる。
- 体の深部体温を下がる。これはカロリー制限をしたときにも見られる。
- 深部体温が下がることで褐色脂肪細胞が活性化する。
第5章 : 老化を治療する薬
イースター島に由来するラパマイシンの長寿効果
- 1960年代、モアイ像の下の土から新種の放射菌を発見した。その菌は抗真菌生の化合物を分泌することが判明した。その化合物はラパマイシンと名付けられた。
- ラパマイシンには強力な免疫抑制機能があることが分かった。臓器移植の拒絶反応を抑えるのに使われるようになった。
- 臓器移植とは別に、寿命を延ばす働きももつ。ラパマイシンはmTOR(高齢の父親をもつマウスで活発になりすぎるタンパク質)の働きを抑える。
糖尿病治療薬として手頃な価格で処方されるメトホルミン
- メトホルミンは世界で広く使われており安価。副作用も胃部の不快感と比較的低い。
- メトホルミンもラパマイシンと同様にカロリー制限に似た効果が現れる。
- ラパマイシンと異なりTOR阻害ではなく、ミトコンドリアの代謝反応を制限する方向に働く。制限によりAMPKという酵素が活性化し、ミトコンドリアの機能を回復させる。
- メトホルミンは癌の羅患率を下げるという研究結果がある。
サーチュインを活性化させる化学物質
- レスベラトロールは様々な植物がストレス時に生み出す天然の分子。赤ワインにも含まれている。
- 健康増進に役立つ様々な分子とその誘導体は、ストレスを受けた植物によって大量に作られる。
サーチュインの燃料となるNAD
- NADはサーチュイン活性化化合物(STAC)。NADはほかのSTACにはない利点がある。7種類あるサーチュインすべての活動を高めてくれる。
- 人間を対象にして、NAD濃度を高める様々な分子を使った研究が進められている。
第6章 : 若く健康な未来への躍進
老化に対する未来の選択肢
- 老化細胞を除去する
- レトロトランスポゾンを封じ込める
- 免疫系を活用するワクチンを使う
- 細胞のリプログラミング
老化細胞を除去する
- 老化の典型的特徴の1つが、老化細胞の蓄積。
- 人間の体が老化細胞を始末しない理由。一説には30,40代でがんにならないための予防策としての進化と言われている。老化細胞とは分裂しない細胞。がんで遺伝子が変異しても細胞が増殖して腫瘍を形成することがない。
- セノリティクスと呼ばれる老化細胞除去薬が期待されている。
レトロトランスポゾンを封じ込める
- ゲノム全域を移動することができる可動生のDNA配列をレトロトランスポゾンと呼ぶ。
- レトロトランスポゾンとそれが移動したことを示す痕跡が、ヒトゲノムの約半分を占めている。この領域はジャンクDNAと呼ばれており、遺伝子のお荷物とされている。
- 若いときはサーチュインによりレトロトランスポゾンを封じ込めている。
免疫系を活用するワクチンを使う
- がんの免疫療法の一つが免疫チェックポイント阻害療法。がん細胞の隠れ蓑を剥がし免疫系のT細胞がそれを見つけて破壊できるようにする。
- がんと同じことを老化細胞でもできると考えられている。
細胞のリプログラミング
- 細胞のプログラムを初期化して、最初の状態に戻す。
- 老いたDNAであっても、再び若くなるための情報を保持している。
- 4つの遺伝子が成熟細胞をiPS細胞(人工多能性幹細胞)に変える。
- 4つの遺伝子を若返りに使用するには未だリスクが高い。マウスの実験では奇形種の発生、腫瘍細胞ができる結果になることも多い。
- マウスの視神経性を再生させ、高齢マウスの視力に成功するという結果も得られている。視神経(脊髄神経などの中枢神経)は生まれ変わらない限り再生しないとされていた。
リプログラミング技術の倫理的問題
- 誰に対してこの技術の使用を許すか(富裕層、重病患者、末期患者等)
- 何歳でリプログラミングが行われるべきか
- 老化することを選ぶ権利もすべての人に与えるべきか
第7章 : 医療におけるイノベーション
個人に特化した精密医療
- いまの医療は、ほとんどの場面でほとんどの人に効果を発揮する方法であり、ほとんどはすべてではない。人によっては間違った医療が施され、かえって状態を悪化させる恐れもある。
- 新しいオーダーメイドのがん治療法も夢ではない。
自分の遺伝子を知ることで可能となること
- どんな病気にかかりやすいか、長生きするためにどんな予防策を講じればいいかがわかる
- 遺伝子が異なれば薬への反応も異なる。その人に適した薬の処方が可能となる。
センサーの活用
- パーソナル・バイオセンサーの時代が迫っている。すでにセンサー付きウォッチが心拍数を記録したり睡眠サイクルを測定したりする。血糖値や血液細胞のモニタリングも非常に簡単なっている。
- バイオモニターにより、何を食べればよいか、いつどれだけ運動すればよいかといった生活習慣の決断を助ける
- バイオトラッキングは突然死を防ぐのに役立つ。
- バイオトラッキングには、個人情報を明け渡すことへの懸念がある。得られる価値とリスクとを鑑みた選択は個人による。
ワクチン開発のミニ・ルネサンス
- 過去100年の間に寿命と健康寿命が伸びた背景には、ワクチンの影響がきわめて大きかった。
- ワクチンを製造するのは企業。資金不足によりワクチン製造が終了することもある。
臓器移植のドナー問題
- 臓器移植の元となる臓器の多くは、自動車の交通事故死亡者が主な供給源となっている。
- 自動運転の実現により自動車事故が減少すると、臓器移植に必要な臓器はより一層足りなくなる。
- 異種移植(例えば、人の臓器をもつ豚を育てる)、臓器印刷の実現が期待されている。
出典
アイキャッチはMichal JarmolukによるPixabayからの画像