【AWS】pythonでS3のファイルを操作する手順(Boto3)
pythonのプログラムからS3を操作する手順をまとめました。ファイルのアップロード/ダウンロードなど、基本的な手順を書いています。
- [1] 前提条件
- [2] 準備
- [3] Boto3を使った操作の概略
- [4] Boto3を使った操作の詳細
- 終わりに
- 補足
- 出典
[1] 前提条件
AWS EC2環境で実行する際の手順です。ライブラリとして「AWS SDK for Python (Boto3)」を使用しています。
- EC2
- Amazon Linux2
- Python3
- Boto3
[2] 準備
[2-1] boto3のインストール
pipを使ってインストールします。
pip3 install boto3 --user
Quickstart — Boto3 Docs 1.17.102 documentation
[2-2] EC2にIAMロールを付与する
詳細は末尾の補足に記載しますが、IAMロールを作成し、以下のIAMポリシーを適用します。作成したIAMロールをEC2インスタンスに設定します。
IAMポリシー以下の権限を付与しています。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ListAllBuckets", "Effect":"Allow", "Action": "s3:ListAllMyBuckets", "Resource":"arn:aws:s3:::*" }, { "Sid": "ListObjectsInBucket", "Effect": "Allow", "Action": ["s3:ListBucket","s3:GetBucketLocation"], "Resource": ["arn:aws:s3:::bucket-name"] }, { "Sid": "ObjectActions", "Effect": "Allow", "Action": ["s3:GetObject","s3:PutObject","s3:DeleteObject"], "Resource": ["arn:aws:s3:::bucket-name/*"] } ] }
IAMポリシーは下記資料を参考にしています。
- ユーザーポリシーの例 - Amazon Simple Storage Service
- Amazon S3: S3 バケットのオブジェクトへの読み取りおよび書き込みアクセスを許可する - AWS Identity and Access Management
[3] Boto3を使った操作の概略
やり方は色々とありますが、以下のソースコードで基本的なことは出来ます。
import boto3 BUCKET_NAME = 'bucket_name' # 全バケットを表示 s3 = boto3.resource('s3') for bucket in s3.buckets.all(): print(bucket.name) # バケット内の全オブジェクトを表示 bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.all() for obj in objects: print(obj.key) # オブジェクトをダウンロード bucket.download_file('input/file.txt', 'file.txt') # オブジェクトをアップロード bucket.upload_file('file.txt', 'output/file.txt') # オブジェクトを削除 s3.Object(BUCKET_NAME, 'output/file.txt').delete()
前半は全バケットの表示と、バケット内オブジェクトの表示です。後半はバケットからファイルをダウンロードし、別名でアップロードしたのち削除しています。
[4] Boto3を使った操作の詳細
boto3.resourceとboto3.client、2つの書き方があります。両者とも概ね同じことができるようになっています。
[4-1] 全バケットを表示
QuickStartに書いてあるソースコードです。非常に簡単です。
import boto3 s3 = boto3.resource('s3') for bucket in s3.buckets.all(): print(bucket.name)
Quickstart — Boto3 Docs 1.17.102 documentation
以下の書き方でも、同じことが実現できます。
s3 = boto3.client('s3') response = s3.list_buckets() print('Existing buckets:') for bucket in response['Buckets']: print(f' {bucket["Name"]}')
Amazon S3 buckets — Boto3 Docs 1.17.102 documentation
[4-2] バケット内のオブジェクトを表示
[4-2-1] 全オブジェクトを表示
boto3.resourceを使用した書き方は次の通りです。
BUCKET_NAME = 'bucket_name' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) for obj in bucket.objects.all(): print(obj.key)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientを使用した書き方は次の通りです。どちらを使用しても同じ出力結果が得られます。
BUCKET_NAME = 'bucket_name' s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME) for obj in response['Contents']: print(obj['Key'])
S3 — Boto3 Docs 1.17.102 documentation
例として以下のような出力結果が得られます。
# dir1/ # dir1/file1.txt # dir1/file2.txt # dir2/ # dir2/file3.csv # dir2/file4.txt # file5.csv
下記ファイル構成の場合の出力結果です。
bucket_name ├── dir1 │ ├── file1.txt │ └── file2.txt ├── dir2 │ ├── file3.csv │ └── file4.txt └── file5.csv
[4-2-2] Prefixに該当するオブジェクトを表示
指定したPrefixに該当するオブジェクトを表示することも可能です。
boto3.resourceを使用した書き方は以下の通りです。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.filter(Prefix='dir1') for obj in objects: print(obj.key) # dir1/ # dir1/file1.txt # dir1/file2.txt
boto3.clientを使用した書き方は以下の通りです。
s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME, Prefix='dir2') for obj in response['Contents']: print(obj['Key']) # dir2/ # dir2/file3.csv # dir2/file4.txt
[4-2-3] 階層化のオブジェクトのみ表示
Delimiterを使用することで階層直下のオブジェクトのみ表示します(再帰表示しない)。以下の例ではバケットの直下のみ表示しています。
boto3.resourceを使用した書き方は以下の通りです。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) objects = bucket.objects.filter(Delimiter='/') for obj in objects: print(obj.key) # file5.csv
boto3.clientを使用した書き方は以下の通りです。
s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket=BUCKET_NAME, Delimiter='/') for obj in response['Contents']: print(obj['Key']) # file5.csv
[4-2-4] Keyが1,000件以上になる場合の対処法
オブジェクト情報取得には制限があります。ワンオペレーションで取得できるKeyは最大で1,000件までです。1,000件を超えることが想定される場合、それを見越した処理が必要になります。
以下の処理では、テスト用に一度で5件までしか取得できないようにしています。MaxKeys=5です。Markerにキーを指定すると、そのキーの次のオブジェクトから取得します。
s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) marker = '' while True: # オブジェクト取得 objects = bucket.objects.filter(Marker=marker, MaxKeys=5) # オブジェクト表示 last_key = None for obj in objects: print(obj.key) last_key = obj.key # 最後のキーをMarkerにセットし次のオブジェクト取得を行う。 # オブジェクト取得が完了していたら終了。 if last_key is None: break else: marker = last_key
boto3.clientの場合、MarkerではなくContinuationTokenを使用します。
s3 = boto3.client('s3') # オブジェクト取得 response = s3.list_objects_v2(Bucket=BUCKET_NAME, MaxKeys=5) while True: # オブジェクト表示 for obj in response['Contents']: print(obj['Key']) # 'NextContinuationToken'が存在する場合は、次のデータ取得。 if 'NextContinuationToken' in response: token = response['NextContinuationToken'] response = s3.list_objects_v2(Bucket=BUCKET_NAME, MaxKeys=5, ContinuationToken=token) else: break
[4-2-5] resourceとclientで得られる情報の違い
上の例ではオブジェクトの「key」情報のみを取得していますが、他にも含まれる情報があります。そして、boto3.resourceとboto3.clientで持つ情報が若干異なります。
boto3.resourceで得られる情報は次の通りです。
# 〜〜〜(省略)〜〜〜 for obj in bucket.objects.all(): print(obj) # s3.ObjectSummary(bucket_name='bucket_name', key='dir1/') print(obj.bucket_name) # bucket_name print(obj.key) # dir1/ print(obj.e_tag) # "d41d8cd98f00b204e9800998ecf8427e" print(obj.last_modified) # 2021-06-30 09:28:47+00:00 print(obj.owner) # None print(obj.size) # 0 print(obj.storage_class) # STANDARD
boto3.clientで得られる情報は次の通りです。
# 〜〜〜(省略)〜〜〜 for obj in response['Contents']: print(obj) # {'Key': 'dir1/', # 'LastModified': datetime.datetime(2021, 6, 30, 9, 28, 47, tzinfo=tzlocal()), # 'ETag': '"d41d8cd98f00b204e9800998ecf8427e"', # 'Size': 0, # 'StorageClass': 'STANDARD'}
[4-3] バケットからファイルをダウンロード
[4-3-1] ファイルにダウンロード
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir1/file1.txt' FILE_NAME1 = 'file1.txt' s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).download_file(OBJECT_NAME1, FILE_NAME1)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME2 = 'dir1/file2.txt' FILE_NAME2 = 'file2.txt' s3 = boto3.client('s3') s3.download_file(BUCKET_NAME, OBJECT_NAME2, FILE_NAME2)
S3 — Boto3 Docs 1.17.103 documentation
[4-3-2] ファイルライクオブジェクトにダウンロード
ファイルを直接ダウンロードするだけで無く、ファイルライクオブジェクトへのダウンロードも可能です。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir2/file3.csv' FILE_NAME3 = 'file3.csv' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) with open(FILE_NAME3, 'wb') as f: bucket.download_fileobj(OBJECT_NAME3, f)
あまり使いどころが無いかもしれませんが、以下のように一時ファイルに出力する等が可能です。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir2/file3.csv' FILE_NAME3 = 'file3.csv' s3 = boto3.client('s3') with tempfile.NamedTemporaryFile(mode='wb') as f: s3.download_fileobj(BUCKET_NAME, OBJECT_NAME4, f) print(f.name) # /tmp/tmppjvqnyf5 print(f.tell) # <function BufferedWriter.tell at 0xffff90ff9290>
[4-4] バケットにファイルをアップロード
アップロードもダウンロードと同様の手順です。
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir3/file1.txt' FILE_NAME1 = 'file1.txt' OBJECT_NAME2 = 'dir3/file2.txt' FILE_NAME2 = 'file2.txt' s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).upload_file(FILE_NAME1, OBJECT_NAME1) s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) with open(FILE_NAME2, 'rb') as f: bucket.upload_fileobj(f, OBJECT_NAME2)
S3 — Boto3 Docs 1.17.102 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' FILE_NAME3 = 'file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' FILE_NAME4 = 'file4.txt' s3 = boto3.resource('s3') s3.meta.client.upload_file(FILE_NAME3, BUCKET_NAME, OBJECT_NAME3) s3 = boto3.client('s3') with open(FILE_NAME4, 'rb') as f: s3.upload_fileobj(f, BUCKET_NAME, OBJECT_NAME4)
S3 — Boto3 Docs 1.17.103 documentation
[4-5] バケットのオブジェクトを削除
[4-5-1] 単一オブジェクトの削除
boto3.resourceの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME1 = 'dir3/file1.txt' s3 = boto3.resource('s3') s3.Object(BUCKET_NAME, OBJECT_NAME1).delete()
S3 — Boto3 Docs 1.17.105 documentation
boto3.clientの手順は以下の通りです。
BUCKET_NAME = 'bucket_name' OBJECT_NAME2 = 'dir3/file2.txt' s3 = boto3.client('s3') s3.delete_object(Bucket=BUCKET_NAME, Key=OBJECT_NAME2)
S3 — Boto3 Docs 1.17.105 documentation
[4-5-2] 複数オブジェクトの削除
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) bucket.delete_objects( Delete={ 'Objects': [ {'Key': OBJECT_NAME3}, {'Key': OBJECT_NAME4} ] }, )
S3 — Boto3 Docs 1.17.105 documentation
BUCKET_NAME = 'bucket_name' OBJECT_NAME3 = 'dir3/file3.csv' OBJECT_NAME4 = 'dir3/file4.txt' s3 = boto3.client('s3') s3.delete_objects( Bucket=BUCKET_NAME, Delete={ 'Objects': [ {'Key': OBJECT_NAME3}, {'Key': OBJECT_NAME4} ] }, )
S3 — Boto3 Docs 1.17.105 documentation
終わりに
同じことをやるにも色々なやり方があり混乱しました。ですが、どの手順でも大きな差はありませんでした。手順自体も簡単なため、自分が使いやすいと思うものを使えばいいようです。
補足
[補足1] IAMロールをマネージメントコンソールで作成する手順
IAMロールを作成します。

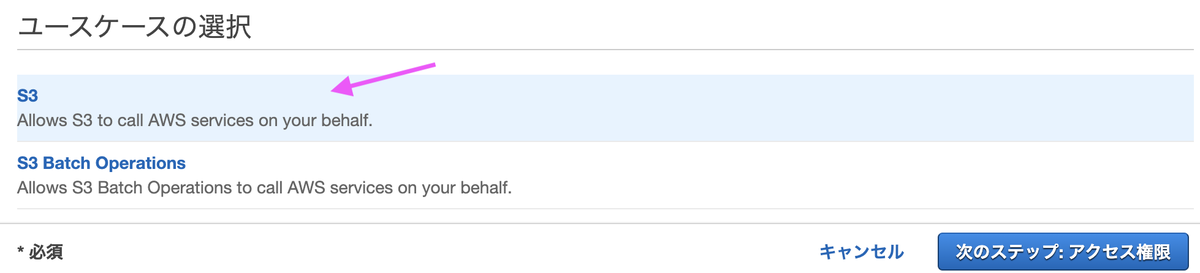
ユースケースの選択で[S3]を選びます。
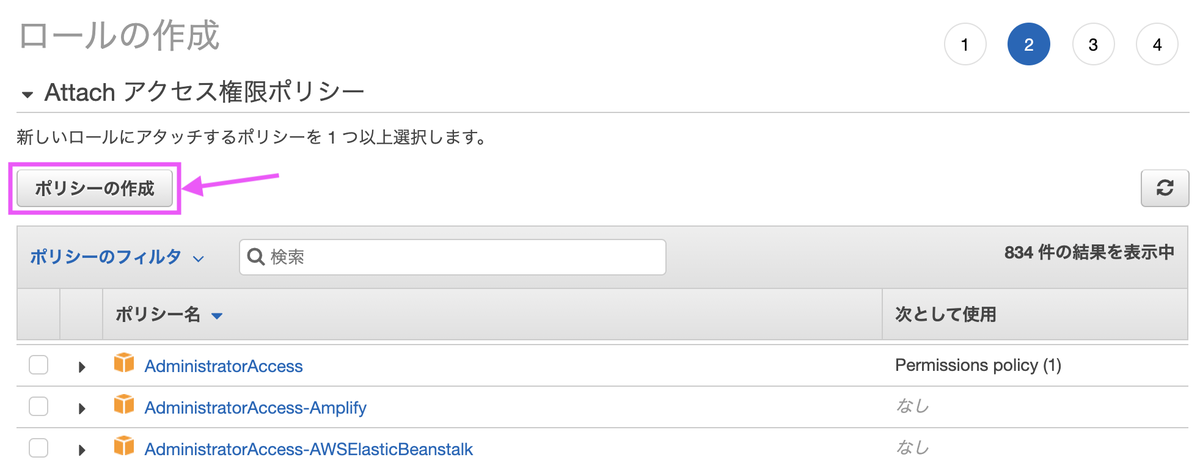
[ポリシーの作成]を選びます。
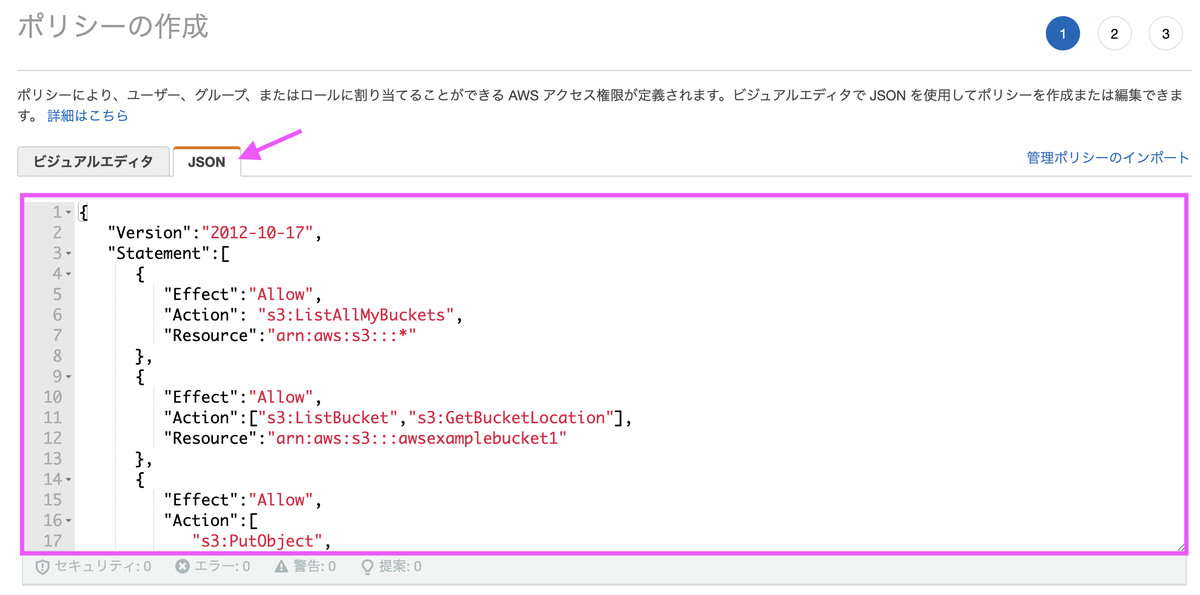
本文に記載したJSONを貼り付けます。バケット名はご自身のバケットの名称に置き換えます。
ポリシー名は任意の名称で構いません。

ロールの作成画面に戻ったら、作成したポリシーを割り当てます。更新ボタンを押してポリシー名を検索ボックスに入力すると、選択肢に出てきます。
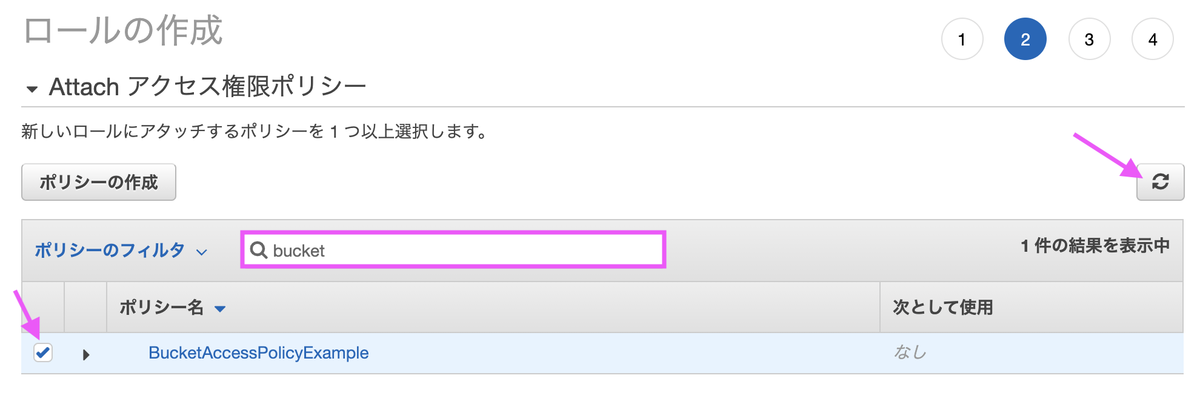
ロール名は任意の名称で構いません。

[補足2] IAMロールをCloudFormationで作成する場合
テンプレートファイルに以下の記述を追加します(Resourcesは元々書いてあるはずなので追加不要です)。長ったらしく感じますが「バケット名」以外は決まりきった書き方です。
Resources: # (...途中省略...) S3AccessRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "ec2.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" S3AccessPolicies: Type: AWS::IAM::Policy Properties: PolicyName: s3access PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - "s3:ListAllMyBuckets" - "s3:GetBucketLocation" Resource: "arn:aws:s3:::*" - Effect: Allow Action: - "s3:ListBucket" Resource: - "arn:aws:s3:::{バケット名}" - Effect: Allow Action: - "s3:GetObject" - "s3:PutObject" - "s3:DeleteObject" Resource: - "arn:aws:s3:::{バケット名}/*" Roles: - !Ref S3AccessRole S3AccessInstanceProfile: Type: AWS::IAM::InstanceProfile Properties: Path: "/" Roles: - !Ref S3AccessRole
追加した「S3AccessInstanceProfile」をEC2インスタンスと紐づければ終わりです。
# (...途中省略...) Instance: Type: AWS::EC2::Instance Properties: # (...途中省略...) IamInstanceProfile: !Ref S3AccessInstanceProfile
出典
アイキャッチはOpenClipart-VectorsによるPixabayからの画像