pandasのDataFrameをconcatすると型が変わってしまう場合の対処法

<pandasのDataFrameをconcatすると型が変わってしまう場合の対処法>*1
※ 2020/03/14にQrunchで書いた記事を移行しました。
pandasのDataFrameを連結する際はconcatを使用します。
このとき、DataFrameにNaNが含まれていると型が変わってしまう場合があります。
起きた事象
dtypeがintの列を結合するとき、結合元のいずれかにNaNが含まれていると、結合後にdtypeがfloatに変わってしまいました。
int_df1 = pd.DataFrame(data=[0, 1, 2, 3, 4], columns=['Int']) int_df2 = pd.DataFrame(data=[np.nan, 6, 7, 8, 9], columns=['Int']) int_df3 = pd.concat([int_df1, int_df2]) print(int_df3['Int'].dtype) # float64
結合元のdtypeを確認すると、NaNを含む方はfloatになっていました。
print('int_df1:', int_df1['Int'].dtype) print('int_df2:', int_df2['Int'].dtype)
NaNはfloat型
np.nanはfloat型なので、int型の中にnp.nanが含まれているとfloat型と認識されてしまいます。 文字列などのobject型の場合は、NaNが含まれていてもobject型のままです。
obj_df1 = pd.DataFrame(data=['0', '1', '2', '3', '4'], columns=['Object']) obj_df2 = pd.DataFrame(data=[np.nan, '6', '7', '8', '9'], columns=['Object']) obj_df3 = pd.concat([obj_df1, obj_df2], ignore_index=True) print(obj_df3['Object'].dtype) # object
対処法1
DataFrameを作成する際にdtypeを明示的にInt64と指定します。
すると、concatによる結合後も'dtypeはInt64'のままになっています。
int_df1 = pd.DataFrame(data=[0, 1, 2, 3, 4], columns=['Int'], dtype='Int64') int_df2 = pd.DataFrame(data=[np.nan, 6, 7, 8, 9], columns=['Int'], dtype='Int64') int_df3 = pd.concat([int_df1, int_df2], ignore_index=True) print(int_df3['Int'].dtype) # Int64
対処法2
結合後にNaNを他の値に変更してから、dtypeをInt64に変更する方法もあります。
この場合、対処法1とは異なりNaNが保持されず別の値に変わることになります。
int_df1 = pd.DataFrame(data=[0, 1, 2, 3, 4], columns=['Int']) int_df2 = pd.DataFrame(data=[np.nan, 6, 7, 8, 9], columns=['Int']) int_df3 = pd.concat([int_df1, int_df2], ignore_index=True) # NaNを0で埋める int_df3.fillna({'Int':0 }, inplace=True) # 'Int'列の型を変更する int_df3 = int_df3.astype( {'Int': 'Int64'} ) print(int_df3['Int'].dtype) # Int64
終わりに
世の中に存在する実データは欠損(NaN)を含む場合が多いので、対処法を知っておいて損はないと思います。 上に記載した内容の詳しい説明は、pandasのUserGuideに載っています。 Nullable integer data type — pandas 1.0.2 documentation
*1:Gerd AltmannによるPixabayからの画像
【機械学習】Kaggle Titanic competitionのチュートリアルが終わったあとにやったこと

Kaggle Titanic competitionのチュートリアルが終わったあとにやったこと*1
※ 2020/03/11にQrunchで書いた記事を移行しました。
チュートリアルを終え、予測結果の提出方法までは分かりました。 以降は、予測精度の向上を目指しました。
結果として、スコア(正解率)=0.80382まで達することが出来ました。 03/10時点では、1235/16508位でした。
ぶっちゃけ
今回参加したTitanic competitionはチュートリアル的コンペティションということもあり、先人方の残してくれた情報がたくさんありました。 様々なNotebooksや記事を参考にさせていただきました。 ありがとうございました。
[参考文献]
- Introduction to Ensembling/Stacking in Python | Kaggle
- Titanic Data Science Solutions | Kaggle
- Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~ - Qiita
- Kaggle Titanic competitionでようやくTop 5%に乗った話 - Qiita
- kaggle/titanic 欠損値の補完と特徴量エンジニアリング - Qiita
やったこと
「特徴量の作成」です。 予測精度を上げるためには、特徴量の作成が重要であり、多くの時間を割きます。 大雑把に言うと「特徴量≒機械学習の入力」であり、良い特徴量を作れたかで順位が決まるといっても過言ではありません。 特徴量の作成にあたり、まずは入力データの分析を行いました。
[1] データ分析
[1-1] Titanicコンペの入力データ
Titanicコンペでは、予測対象「Survived(生存したか)」を除くと、11パラメータあります。 11パラメータとSurvivedの関係、11パラメータ同士の関係を見ていきました。
| パラメータ | 説明 |
|---|---|
| PassengerId | 乗客ID |
| Pclass | 社会経済的地位 |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 乗船している兄弟・夫妻の数 |
| Parch | 乗船している親・子の数 |
| Ticket | チケット番号 |
| Fare | 運賃 |
| Cabin | キャビン番号 |
| Embarked | 乗船港 |
[1-2] 分析した結果
結論、以下の内容が分かりました。
- Ageが小さい人(子供)の生存率は高い
- Pclassが小さいほど生存率は高い
- 女性の方が男性よりも生存率は高い
- SibSp=1,2の人は生存率は高い
- Parch=1,2,3の人は生存率は高い
- Fareは高い方が生存率は高い
- Embarked=Cの人は生存率は高い
[1-3] 数値で見る
データの個数とNaNの数、平均値といった数値を確認しました。
[1-3-1] NaNの数
データの個数と、それに対するNaNの数を知ることは重要です。 NaNがあまりに多いデータはモデルへの入力として使うのを止めますし、NaNが少数であれば補間することも考えます。
データの個数とNaNの数は、pandas.DataFrameのinfo()で確認できます。
train_data.info() # <class 'pandas.core.frame.DataFrame'> # RangeIndex: 891 entries, 0 to 890 # Data columns (total 12 columns): # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 PassengerId 891 non-null int64 # 1 Survived 891 non-null int64 # 2 Pclass 891 non-null int64 # 3 Name 891 non-null object # 4 Sex 891 non-null object # 5 Age 714 non-null float64 # 6 SibSp 891 non-null int64 # 7 Parch 891 non-null int64 # 8 Ticket 891 non-null object # 9 Fare 891 non-null float64 # 10 Cabin 204 non-null object # 11 Embarked 889 non-null object # dtypes: float64(2), int64(5), object(5) # memory usage: 83.7+ KB
NaNの数だけを確認する場合は、isnull().sum()の方が見やすいです。
train_data.isnull().sum() # PassengerId 0 # Survived 0 # Pclass 0 # Name 0 # Sex 0 # Age 177 # SibSp 0 # Parch 0 # Ticket 0 # Fare 0 # Cabin 687 # Embarked 2 # dtype: int64
[1-3-2] 統計量
平均や標準偏差といった基本的な統計量は、pandas.DataFrameのdescribe()で確認できます。 NaNを除いた数値について、平均・標準偏差・最小・最大といった統計量が出力されます。
train_data.describe()
 カテゴリーデータについて見たい場合は、includeにO(大文字のオー)を指定します。
カテゴリーデータについて見たい場合は、includeにO(大文字のオー)を指定します。
train_data.describe(include='O')
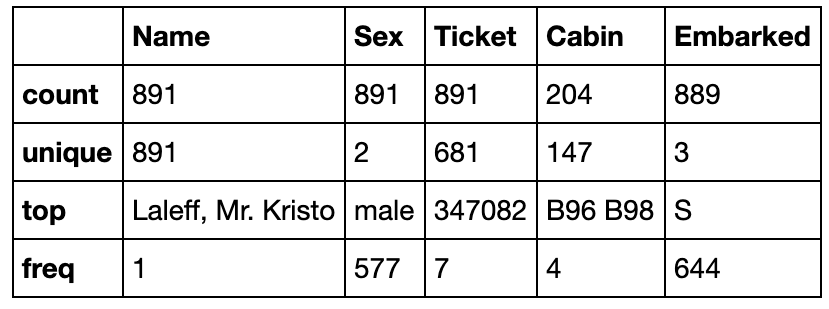
[1-4] グラフで見る
seabornやmatplotlibを使って可視化しました。 数値として見ることも重要なのですが、視覚的に理解することも重要だと言うことも分かりました。
[1-4-1] seabornとmatplotlibを使う
使い方は難しくはありません。例えば、次のようなコードになります。
%matplotlib inline # Jupyter Notebook上にグラフを描画するためのおまじない import seaborn as sns sns.countplot(x='Pclass', data=train_data, hue='Survived')
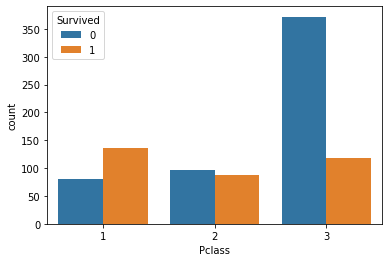
seabornのインストールはpipで行いました。
pip3 install seaborn
[1-4-2] 可視化結果
全てではありませんが、seabornやmatplotlibで可視化した結果です。
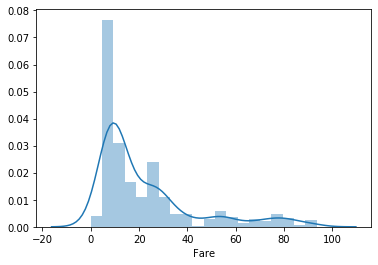
Fare(運賃)
low_fare_data = train_data[train_data["Fare"] < 100] sns.distplot(low_fare_data['Fare'], bins=20)
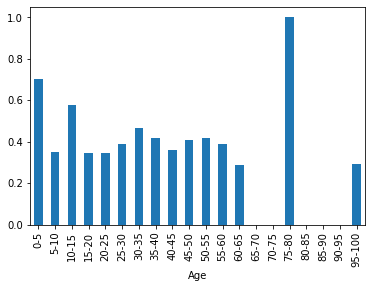
Age(年齢) & Survival rate(生存率)
# Ageの欠損値を99歳で埋める age_filled_data = train_data.fillna({'Age': 99}) # 5歳単位でビニング(-1始まりなのは0を含めたかったから。pd.cutは開始値を含まない) age_bins_list = [-1] + list(range(5, 101, 5)) age_bins_label = [ "{0}-{1}".format(age, age + 5) for age in list(range(0, 100, 5)) ] age_bins = pd.cut(age_filled_data['Age'], bins=age_bins_list, labels=age_bins_label) # Ageでグループ化し平均を取る age_grouped_data = age_filled_data.groupby(age_bins).mean() age_grouped_data['Survived'].plot(kind='bar')
Age(年齢) & Pclass(社会経済的地位)
grid = sns.FacetGrid(train_data, hue='Pclass', aspect=4) grid.map(sns.kdeplot,'Age', shade= True) max_age = train_data['Age'].max() grid.set(xlim=(0, max_age)) grid.add_legend()
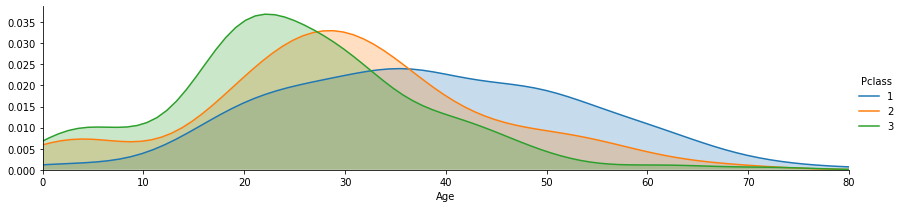
Sex(性別) & Pclass(社会経済的地位) & Survival rate(生存率)
sns.catplot(x='Pclass',y='Survived', hue='Sex', data=train_data, kind='point')

SibSp(兄弟・夫妻の数) & Parch(親・子の数) & Survival rate(生存率)
# SibSpとParchでグループ化し、生存者の合計(sum)と全人数(count)を算出 sibsp_parch_group = train_data.groupby(['SibSp', 'Parch']) survived = sibsp_parch_group['Survived'].sum() count = sibsp_parch_group['Survived'].count() # SibSpとParchの組み合わせごとの生存率を可視化 sibsp_parch_rate = pd.DataFrame(index=survived.index) sibsp_parch_rate['Survival_Rate'] = survived / count sibsp_parch_rate.plot.bar(figsize=(10, 5))
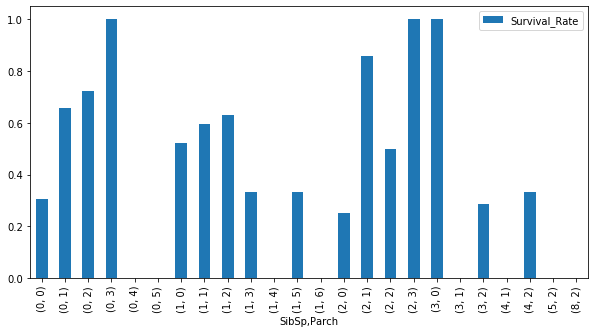
[1-5] どの特徴量が重要か
特徴量のうち、予測精度に影響するものとそうでないものを探します。 例えば、PassengerIdは影響しないと考えられます。
[1-5-1] NaNを埋める
とりあえず、すべての入力パラメータを特徴量として、ランダムフォレストで予測を行ってみます。 NaNがあると予測が出来ないので、NaNを適当な値で埋めます。
from sklearn.preprocessing import LabelEncoder train_all = train_data.copy() test_all = test_data.copy() train_all.fillna({'Age': 99, 'Ticket': 'Na', 'Fare': 999, 'Cabin': 'Na', 'Embarked': 'Na'}, inplace=True) test_all.fillna({'Age': 99, 'Ticket': 'Na', 'Fare': 999, 'Cabin': 'Na', 'Embarked': 'Na'}, inplace=True) all_data = pd.concat([train_all, test_all]) for column in ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']: encoder = LabelEncoder() encoder.fit(all_data[column]) train_all[column] = encoder.transform(train_all[column]) test_all[column] = encoder.transform(test_all[column])
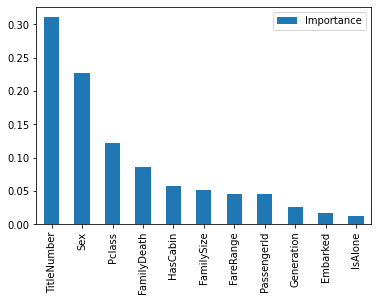
[1-5-2] 重要度の可視化
NaNを埋めたら、特徴量の重要度を可視化します。
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import KFold, cross_val_score train_y = train_all['Survived'] train_x = train_all.drop(columns=['Survived']) test_x = test_all # Evaluation of features model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1) model.fit(train_x, train_y) # Visualize the importance of each feature importances = model.feature_importances_ feature_importances = pd.DataFrame(importances, index=train_x.columns, columns=['Importance']) feature_importances = feature_importances.sort_values(by='Importance', ascending=False) feature_importances.plot.bar()

PassengerIdより重要度の低い'Name', 'SibSp', 'Parch', 'Embarked'は、そのままでは予測精度に影響しないということが分かりました。
[2] 特徴量の作成
分析した結果をもとに新しい特徴量を作成したり、既存の特徴量を加工しました。
[2-1] Name(名前)から敬称を抽出
NameからMr., Miss.などの敬称を抽出します。 敬称自体も特徴量として使えますが、NaNを埋める際にも役に立つので、真っ先に敬称の抽出を行いました。
def preprocess_name(df): # Extract the character string corresponding to "~~." from Name. df["Title"] = df['Name'].str.extract("([A-Za-z]+)\.") pd.crosstab(df['Title'], [df['Sex'], df['Pclass']]) # Group into representative titles df['Title'] = df['Title'].replace(['Countess', 'Lady', 'Major', 'Sir'], 'Upper') df['Title'] = df['Title'].replace(['Capt', 'Col', 'Don', 'Dona', 'Jonkheer', 'Rev' ], 'Rare') df['Title'] = df['Title'].replace(['Mlle', 'Ms'], 'Miss') df['Title'] = df['Title'].replace(['Mme'], 'Mrs')
敬称自体も特徴量として有用性が高いので、数値に変換して特徴量として使えるようにしました。
def convert_title_to_scalar(df): df['TitleNumber'] = 0 temp = df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean().sort_values(by='Survived') temp['TitleNumber'] = np.arange(len(temp)) for i in range(len(temp)): title = temp.iloc[i]['Title'] number = temp.iloc[i]['TitleNumber'] df.loc[df['Title'] == title, 'TitleNumber'] = number
[2-2] 既にある特徴量の前処理
新しい特徴量を作成する前に、既にある特徴量に対して前処理を行いました。
[2-2-1] Sex(性別)
文字列を数値化しただけです。
def preprocess_sex(df): df['Sex'] = df['Sex'].replace({'male':0, 'female': 1})
[2-2-2] Age(年齢)
Ageを4つの区分に分類しました。0歳から5歳の生存率が高く、60歳以上の生存率が低かったので、下記分類にしました。
NaNは敬称ごとのメディアン(中央)で埋めました。 敬称ごとに統計量を算出して埋めるのは下記記事を参考にさせていただきました。
kaggle/titanic 欠損値の補完と特徴量エンジニアリング - Qiita
def preprocess_age(df): df['Age'] = df.groupby(['Title'])['Age'].apply(lambda age: age.fillna(age.dropna().median())) def generations(age): if age <= 6: return 0 if age <= 18: return 1 if age <= 60: return 2 return 3 df['Generation'] = df['Age'].map(lambda age : generations(age))
[2-2-3] Fare(運賃)
Fareが10以下の人が多くかつ生存率も低く、Fareが高い人は生存率が高かったです。 そのため、Fareの低い方を細かく、高い方は広く分類しました。 NaNはAgeと同様に、敬称ごとのメディアン(中央)で埋めました。
def preprocess_fare(df): df['Fare'] = df.groupby(['Title'])['Fare'].apply(lambda fare: fare.fillna(fare.dropna().median())) def fare_range(fare): if fare < 5: return 0 if fare < 10: return 1 if fare < 15: return 2 if fare < 20: return 3 if fare < 50: return 4 return 5 df['FareRange'] = df['Fare'].map(lambda fare : fare_range(fare))
[2-2-4] Cabin(キャビン番号)
CabinはNaNが多かったため、CabinがNaNかそれ以外かを特徴量にしました。
def preprocess_cabin(df): df["HasCabin"] = df['Cabin'].map(lambda cabin : 0 if type(cabin)==float else 1)
[2-2-5] Embarked(乗船港)
NaNをモード(最頻値)で埋め、数値に変換しました。
def preprocess_embarked(df): mode = df['Embarked'].mode()[0] df['Embarked'].fillna(mode, inplace=True) df = df.astype({'Embarked': int}) df['Embarked'] = df['Embarked'] .replace({'S':0, 'Q': 1, 'C': 2})
[2-3] 新しい特徴量を作成する
[2-3-1] FamilySize(家族の人数)
多くの先人方がFamilySizeを用いて精度を上げていました。 SibSp(兄弟・夫妻の数)とParch(親・子の数)を加算します。 加えて、IsAlone(家族の乗船有無)も加えました。
def preprocess_sibsp_parch(df): df['FamilySize'] = df['SibSp'] + df['Parch'] df['IsAlone'] = df['FamilySize'].map(lambda fsize : 1 if fsize==0 else 0)
[2-3-2] FamilyDeath(家族の生存率)
Kaggle Titanic competitionでようやくTop 5%に乗った話 - Qiitaを参考にさせていただきました。
LastNameが同じ、かつ、FamilySizeが同じ人は家族とみなし、家族の生存率を計算しFamilyDeathとしました。 家族の生存率が計算出来ない場合は0.5としました。
def create_family_death(df): df['LastName'] = df['Name'] .map(lambda name: name.split(",")[0]) df['FamilyDeath'] = np.nan col_no = df.columns.get_loc('FamilyDeath') for i in range(len(df)): if df.iloc[i]['FamilySize'] > 0: last_name = df.iloc[i]['LastName'] family_size = df.iloc[i]['FamilySize'] # Extract data of family members except yourself temp = pd.concat([df.iloc[:i], df.iloc[i+1:]]) family = temp[(temp['LastName'] == last_name) & (temp['FamilySize'] == family_size)] if len(family) == 0: continue # Set the average of the survival rate of the family excluding yourself df.iloc[i, col_no] = family.Survived.mean() df['FamilyDeath'].fillna(0.5, inplace=True) create_family_death(all_data)
[3] 評価
[3-1] 不要な特徴量を除去する
別の特徴量を作成済みのものや、明らかに不要と思われる特徴量を除去しました。
def drop_unnecessary_features(df): drop_columns = ['Name', 'Age', 'SibSp', 'Parch', 'Fare', 'Ticket', 'Cabin', 'Title', 'LastName'] df.drop(columns=drop_columns, inplace=True)
[3-2] どの特徴量が重要かを検証する
一度、クロスバリデーションで評価を行い、どの特徴量が重要かを確認しました。
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import KFold, StratifiedKFold, cross_val_score # Trainning with cross validation and and score calculation model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1) kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=1) result = cross_val_score(model, train_x, train_y, cv=kf, scoring='accuracy') print('Score:{0:.4f}'.format(result.mean())) # Evaluation of features model.fit(train_x, train_y) importances = model.feature_importances_ # Visualize the importance of each feature feature_importances = pd.DataFrame(importances, index=train_x.columns, columns=['Importance']) feature_importances = feature_importances.sort_values(by='Importance', ascending=False) feature_importances.plot.bar()
スコアは0.8373でした。
[3-3] 重要度の低い特徴量を除去する
PassengerIdより重要度の低い'Generation', 'Embarked', 'IsAlone'は、予測精度に大きく影響していないので除去します。
def drop_less_effective_features(df): drop_columns = ['PassengerId', 'Generation', 'Embarked', 'IsAlone'] df.drop(columns=drop_columns, inplace=True)
[3-4] 本番
ソースコードは[3-2]と同様です。
 スコアは0.8429でした。
スコアは0.8429でした。
[4] 結果を提出
[4-1] 予測結果を出力
# Prediction predictions = model.predict(test_x) # Output result to csv. output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions}) output.to_csv('my_submission.csv', index=False)
[4-2] 提出
冒頭で書いた通り、結果は0.80382でした。

最後に
今回は先人方の力を借りまくり、なんとか予測精度を上げることが出来ました。とは言っても、まだまだ上がいますが。
Titanic competitionはこれで終わりにします。新しいコンペに参加してみたいと思います。
【機械学習】Kaggle Titanic competitionをチュートリアル通りに進めてみた
※ 2020/03/02にQrunchで書いた記事を移行しました。
前回:Kaggleの始め方(Titanicコンペに参加する)の続きです。
前回は提供されたサンプルファイルを提出しただけでした。 今回から予測精度の向上を図っていきます。
引き続き、チュートリアルを参考に進めていきます。
[1] Kaggleが用意してくれた環境を使う
KaggleではNotebook(旧Kernel)と呼ばれる、クラウドの実行環境を用意してくれています。
[1-1] Notebookを作成する
[Notebook]タブの[New Notebook]をクリックします。

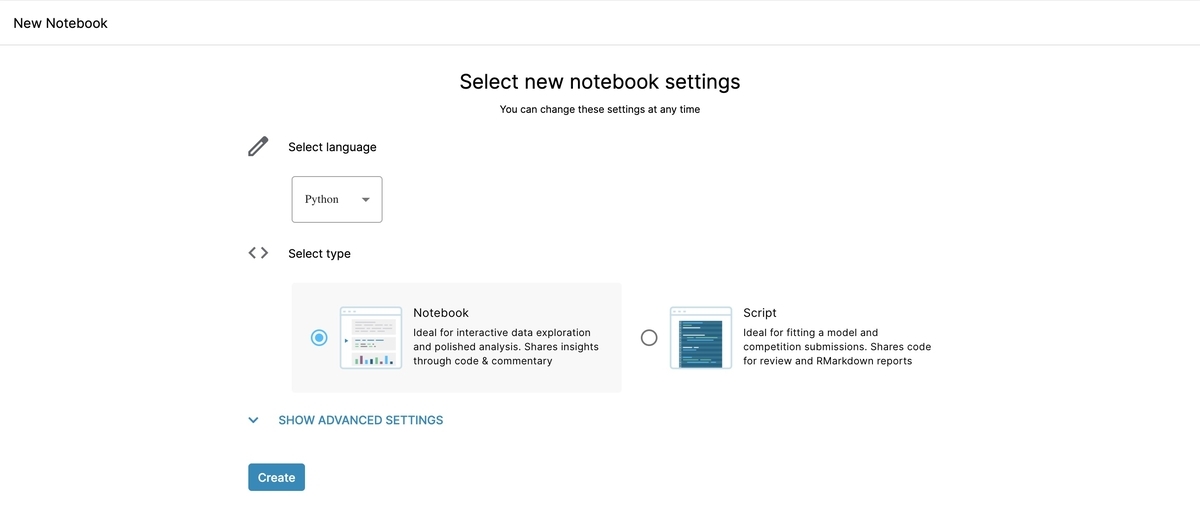
[1-2] Notebookの設定
言語は「Python」、タイプは「Notebook」を選択します。
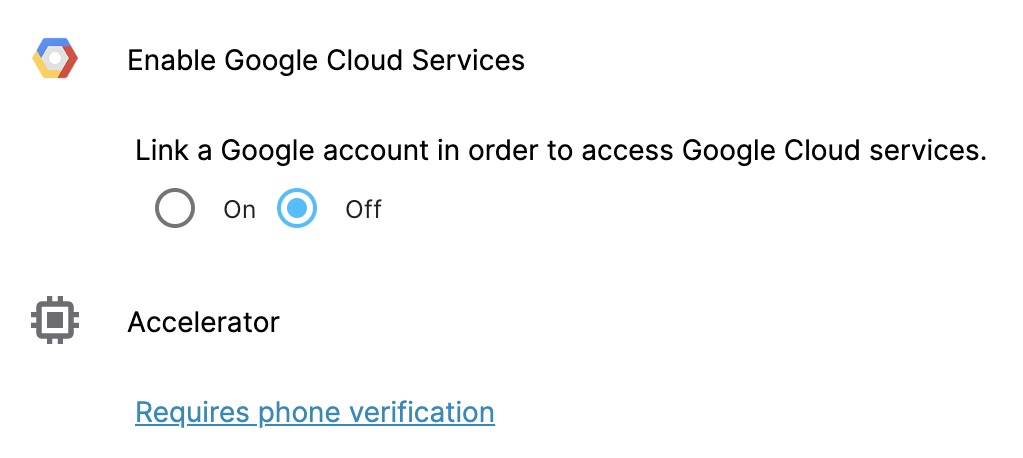
気になったのは私だけかもしれませんが、ADBANCED SETTINGSの内容は以下の通りでした。 Google Cloudとの連携は便利かもしれません。
[1-3] Notebookの作成完了
[Create]をクリックすると数10秒後に、Notebookの作成が完了します。
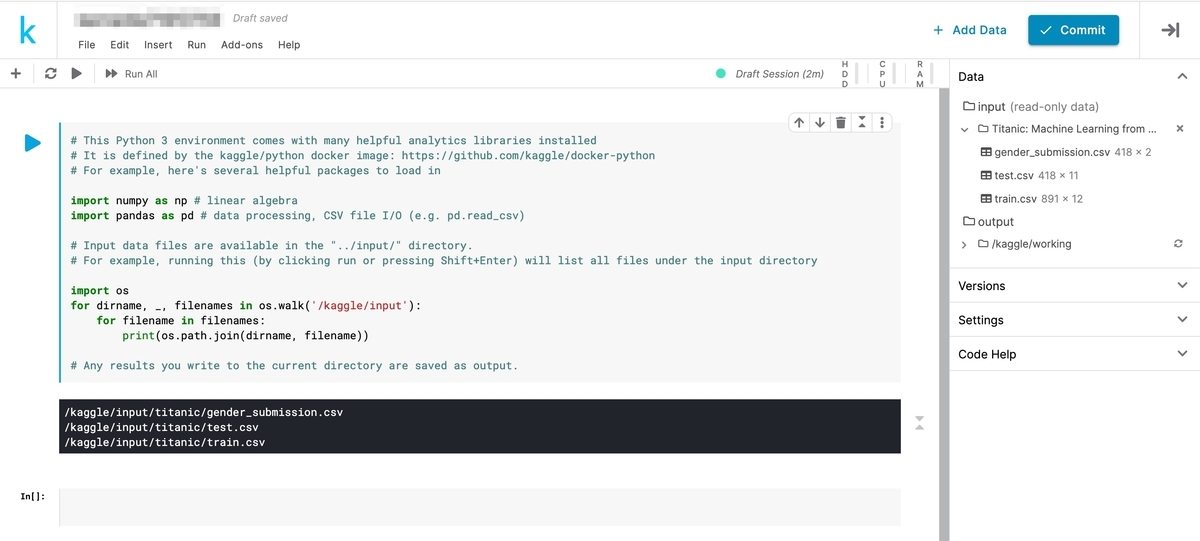
[1-4] ファイルの場所
作成時に用意されているコードをそのまま実行すると、ファイルの場所が出力されます。 画面右側の[Data]からも確認できます。
[1-5] Notebookのスペック
NotebokkのスペックはNotebooks Documentation | Kaggleに書いてありました。 本格的なデータ分析を行うにあたっては心許無いですが、無料でこれだけの環境を用意してくれているのはありがたいです。
| スペック | CPU環境 | GPU環境 |
|---|---|---|
| CPUコア | 4コア | 2コア |
| RAM | 16GB | 13GB |
| 実行時間 | 9時間 | 9時間 |
| 自動保存ディスク容量 | 5GB | 5GB |
[2] チュートリアル通りに進める
[2-1] データの中身を出力する


[2-2] ランダムフォレストを使う
チュートリアルではランダムフォレストを使っています。 ランダムフォレストは決定木の一種です。
チュートリアルに載っていたコードは次の通りです。 各コードの意味を整理していきます。
from sklearn.ensemble import RandomForestClassifier y = train_data["Survived"] features = ["Pclass", "Sex", "SibSp", "Parch"] X = pd.get_dummies(train_data[features]) X_test = pd.get_dummies(test_data[features]) model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1) model.fit(X, y) predictions = model.predict(X_test) output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions}) output.to_csv('my_submission.csv', index=False) print("Your submission was successfully saved!")
[2-3] 必要な特徴量だけを取り出す
予測結果に影響のありそうな'Pclass', 'Sex', 'SibSp', 'Parchのデータを取り出しています。
features = ['Pclass', 'Sex', 'SibSp', 'Parch']
[2-4] カテゴリ変数の数値化
features = ["Pclass", "Sex", "SibSp", "Parch"] X = pd.get_dummies(train_data[features]) X_test = pd.get_dummies(test_data[features])
元のデータは数値だけではありませんでした。 例えば、Sex(性別)はカテゴリデータ('male', 'female')ですが、機械学習を行うにあたり数値化する必要があります。pandasのget_dummiesで数値化しています。
下記が元データです。

下記が数値化後のデータです。 Sexが0と1だけで構成されるダミーデータ(Sex_female, Sex_male)に変換されています。

[2-5] モデルの作成
今回使用するモデルはランダムフォレストです。
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
n_estimators:決定木の数 max_depth:木の深さの最大値 random_state:乱数を制御するパラメータ(1はシード値)
[2-6] 学習
model.fitで学習を行います。
y = train_data['Survived']
model.fit(X, y)
y = train_data['Survived']は学習における正解の取り出しです。
正解に近づくように学習を行います。
[2-7] テスト
学習に使用していないデータで予測を行い、モデルの精度を確認します。
predictions = model.predict(X_test)
[2-8] 予測結果を出力する
予測結果のフォーマットは'PassengerId', 'Survived'の2列のデータでした。 フォーマットを合わせてCSVファイル出力します。
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submisson.csv', index=False)
[3] 予測結果の提出
出力した予測結果「my_submisson.csv」を提出します。
[3-1] チュートリアルの実行結果
以下の画像は、チュートリアルをNotebookで実行した結果です。 まずは編集したNotebookをコミットするために、右上の[Commit]ボタンをクリックします。
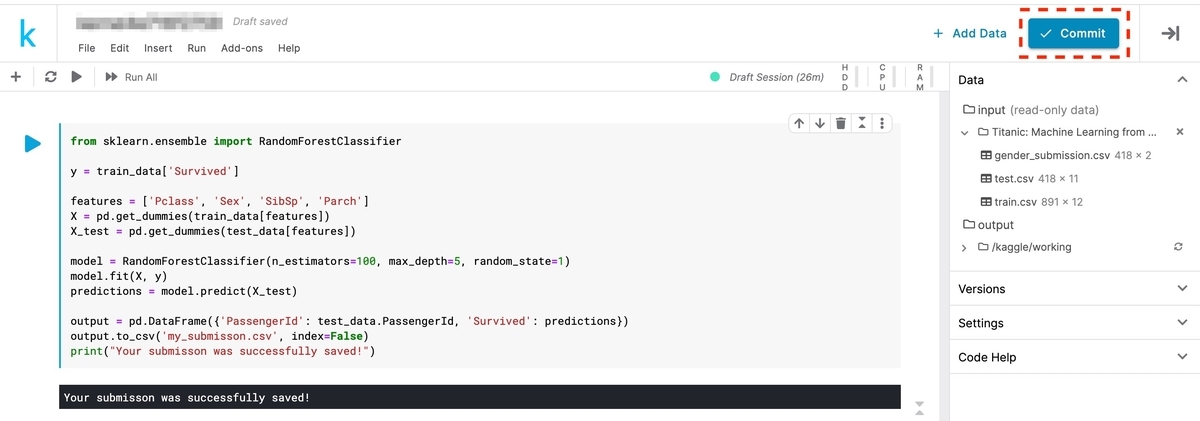
[3-2] コミット
少し待つとコミットが終了します。
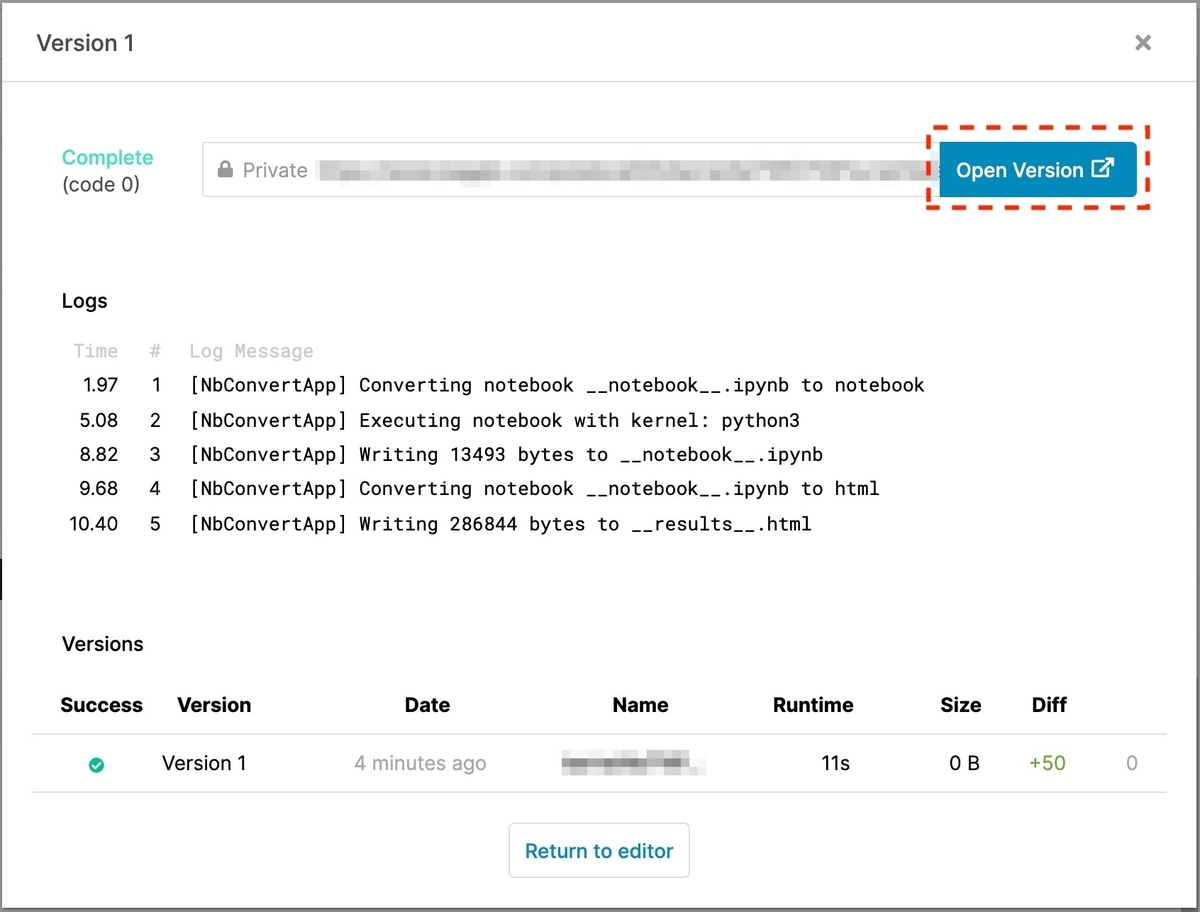
終了したら[Open Version]をクリックします。
[3-3] 予測結果の提出
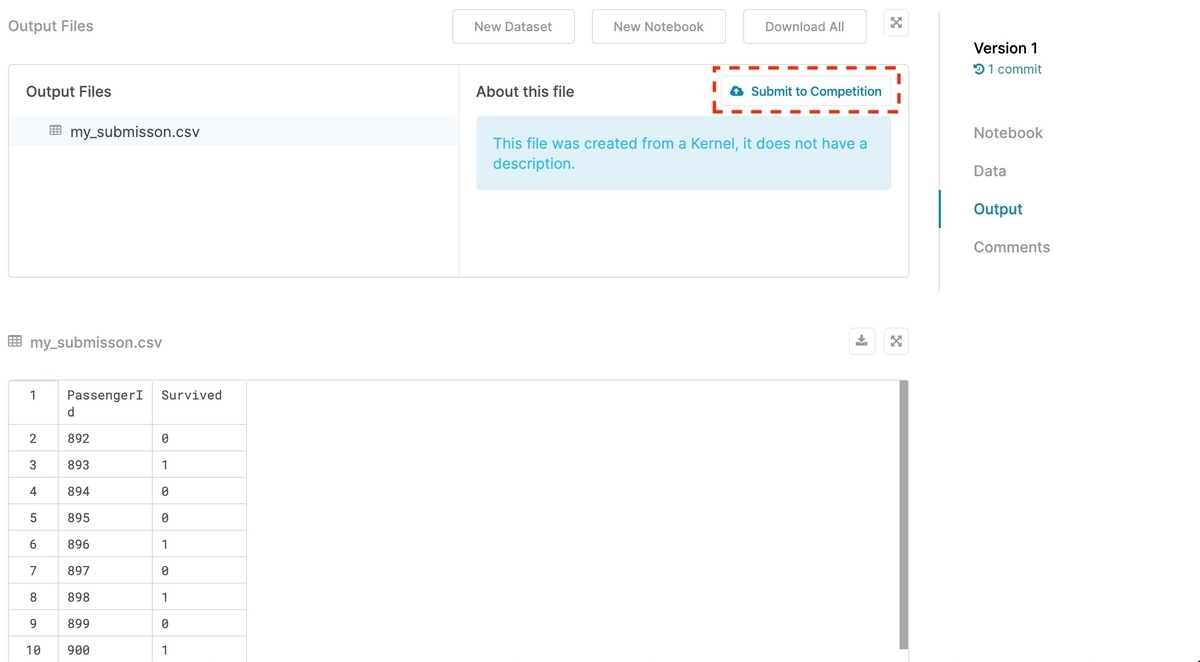
[Open Version]クリック後の画面で、右側の[Output]をクリックします。
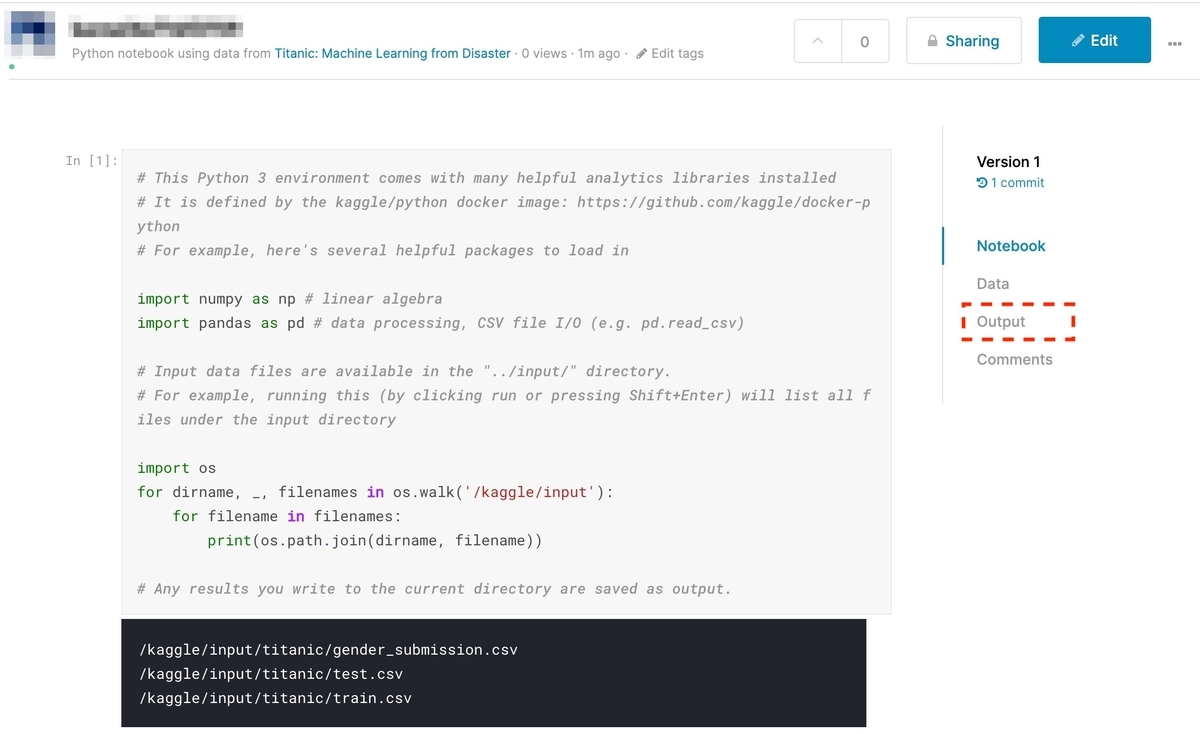
先ほど出力した「my_submisson.csv」が表示されるので、選択して[Submit to Competition]をクリックします。
[3-4] Leaderboardの確認
予測結果が提出されました。
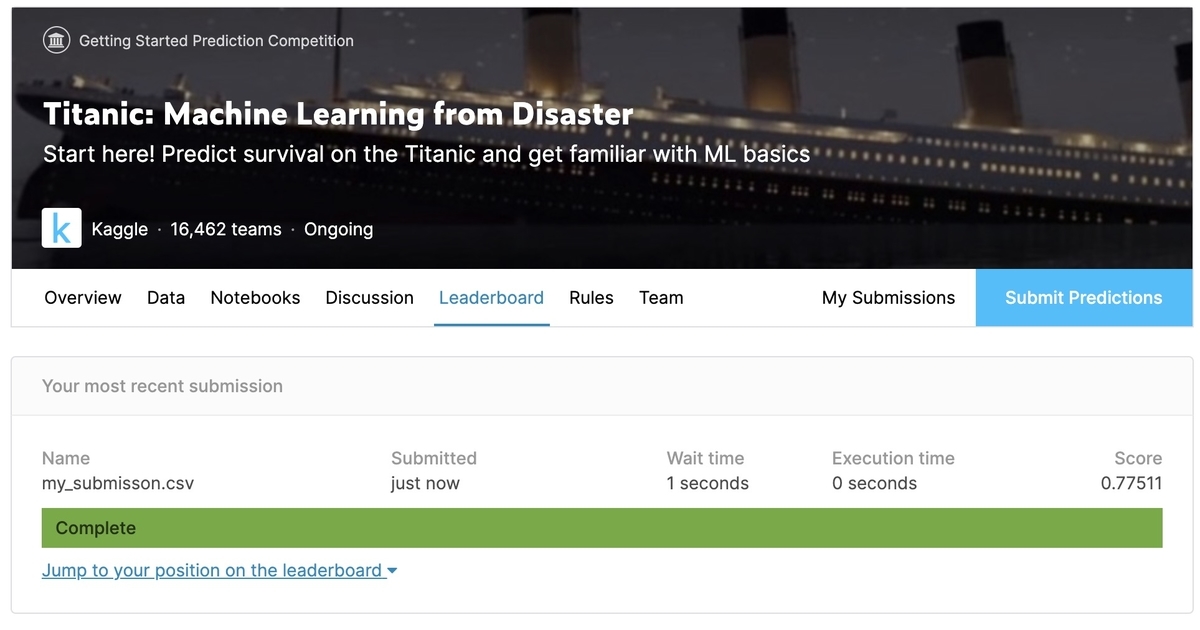
Leaderboardで順位を確認すると、前回の12900位から若干上がりました。

[4] 終わりに
チュートリアル通りに進めてみた結果、Kaggleで予測結果を提出するまでの流れが理解できました。
期限のある本番のコンペティションであれば、チームを組んだり、上位者のコードを参考にしたり、また新しく覚えることが増えるのかもしれません。 しかし、チュートリアルのおかげでスタートラインに立つことは出来た気がします。
最後に、お世話になったチュートリアルのいいねボタン?をクリックして感謝の意を示しましょう。
次の記事では精度向上を目指しました。
参考にさせていただいたサイト
【機械学習】Kaggleの始め方(Titanicコンペに参加する)
Kaggleの入門用コンペ「Titanic」の参加方法を紹介します。
※ 2020/02/29にQrunchで書いた記事を移行しました。
Titanicコンペは入門用コンペ
アカウント作成後にKaggleからメールが送られてきており、Titanicコンペへの参加を薦められます。 Titanicコンペは、タイタニック号の乗客のうち誰が生き延びたかを予測するコンペです。 期限のない「入門用コンペ」です。

[1] コンペに参加する
[1-1] Titanicコンペのページを開く
メールの[Check out the Titanic Machine Learning Competition]をクリックし、Titanicコンペのページを開きます。
[Join Competition]をクリックすると、ルールを読むように勧められます。

[1-2] ルール
ルールを日本語訳したものを表にしました。 チームを組むのはOK、チーム外で非公開に協力することはNG、提出物は1日に10個まで、というKaggleの中ではオーソドックスなルールのようです。 入門用コンペなので期限は無しとなっています。
| 見出し | 内容 |
|---|---|
| 参加者ごとに1つのアカウント | 複数のアカウントからKaggleにサインアップできないため、複数のアカウントから送信することはできません。 |
| チーム外のプライベート共有はありません | チーム外でコードやデータを個人的に共有することは許可されていません。フォーラムのすべての参加者が利用できるようになっている場合、コードを共有しても構いません。 |
| チーム合併 | チームの合併は許可されており、チームリーダーが実行できます。統合するには、統合チームの合計提出件数が、統合日時点で許可されている最大数以下でなければなりません。許可される最大数は、1日あたりの提出数に競争が行われた日数を掛けたものです。 |
| チームの制限 | チームの最大サイズはありません。 |
| 提出制限 | 1日に最大10個のエントリを送信できます。審査のために最大5つの最終提出物を選択できます。 |
| 競技タイムライン | 開始日:2012年9月28日午後9時13分UTC 合併期限:なし 応募締め切り:なし 終了日:なし これは、機械学習の開始を支援することを目的とした楽しいコンテストです。Titanicデータセットはインターネットで公開されていますが、回答を検索すると全体の目的に反します。真剣に、それをしないでください。 |
[1-3] 参加完了
ルールを確認し[I Understand And Accept]を押せば参加完了です。 [Join Competition]が[Submit Predictions]に替わっています。
[2] チュートリアルを参考に進める
公式の動画でも、Alexis Cook’s Titanic Tutorialを見るように勧めているので、まずはTutorialを参考に進めてみることにします。

[2-1] 概要を確認する
[Overview]タブで概要を確認します。 タイタニック号でどの乗客が生き延びたかを予測することが目的だと分かりました。
競争は単純です。機械学習を使用して、どの乗客がタイタニック号の難破船を生き延びたかを予測するモデルを作成します。
タイタニック号の沈没は、歴史上最も悪名高い難破船の1つです。 1912年4月15日、処女航海中に、広く考えられている「沈められない」RMSタイタニック号は、氷山と衝突した後、沈没しました。残念ながら、乗船する全員に十分な救命艇がなかったため、2224人の乗客と乗組員のうち1502人が死亡しました。 生き残るためには運の要素がいくつかありましたが、一部のグループは他のグループよりも生き残る可能性が高いようです。 この課題では、「どのような人々が生き残る可能性が高かった」という質問に答える予測モデルを構築するよう求めます。乗客データ(名前、年齢、性別、社会経済クラスなど)を使用します。
[2-2] データを確認する
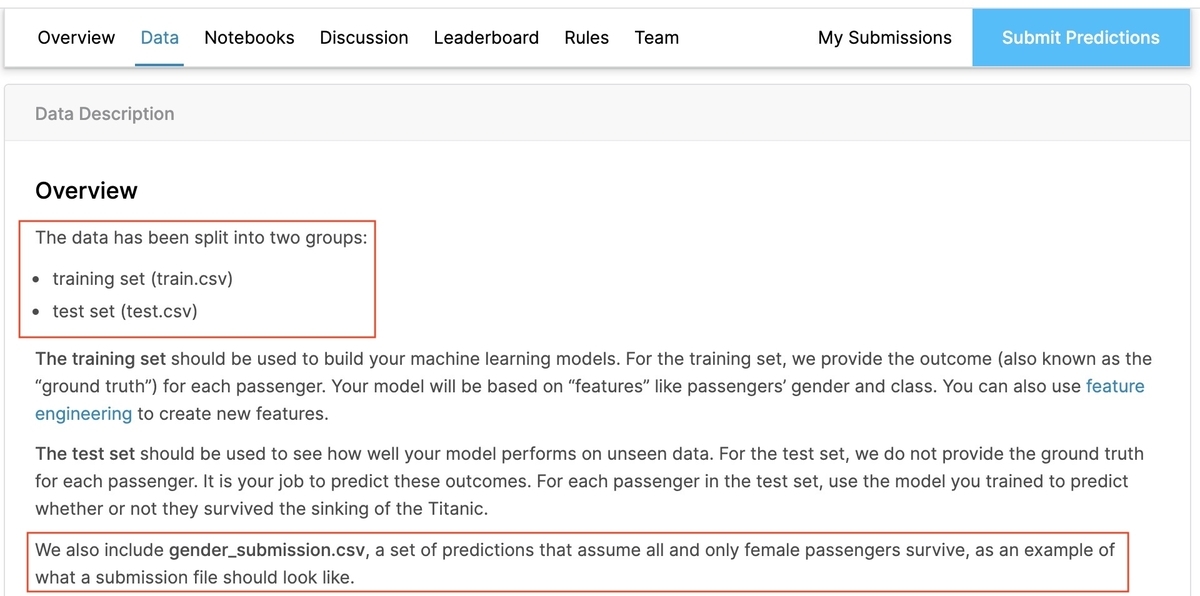
[Data]タブで概要を確認します。
[2-2-1] 入力データ
学習用データの「train.csv」、テスト用データの「test.csv」の2つが入力データであることが分かります。
[2-2-2] 提出ファイルのサンプル
Kaggleでは提出ファイルのサンプルも用意されており、Titanicコンペでは「gender_submission.csv 」が該当します。 自分の予測結果を提出する際は、サンプルと同じフォーマットで提出します。
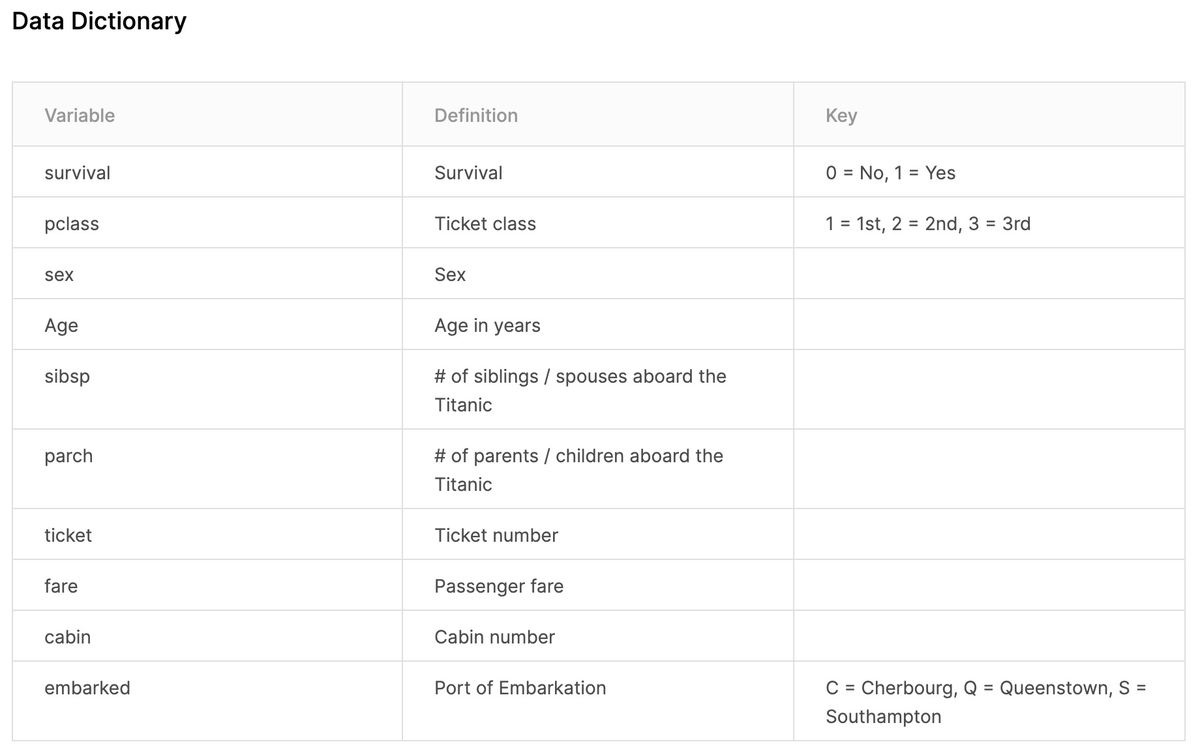
[2-2-3] 入力パラメータ
10パラメータについて説明が書かれています。
説明の必要なパラメータについては「Variable Notes」に詳細が書かれています。
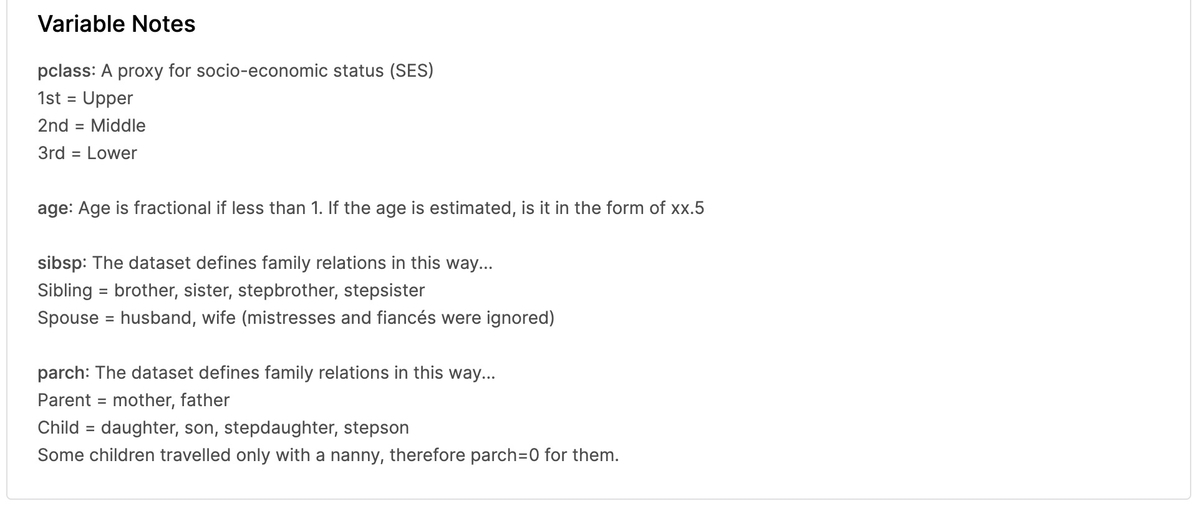
- pclass:社会経済的地位
- sibsp:家族関係 - Sibling:兄、妹、義兄、義姉妹 - Spouse:夫、妻(愛人と婚約者は無視された)
- parch:家族関係 - Parent:母、父 - Child:娘、息子、義理の娘、義理の息子 - 一部の子供は乳母と一緒に旅行したので、彼らはparch = 0でした。
のようです。私は英語が得意ではないので、Google翻訳の力を借りて進めました。
[2-2-4] 入力データの中身
以下が実際の入力データです。 ファイルは「train.csv」「test.csv」「gender_submission.csv」の3つです。 ブラウザ上で見ることも出来ますし、ダウンロードも出来ます。
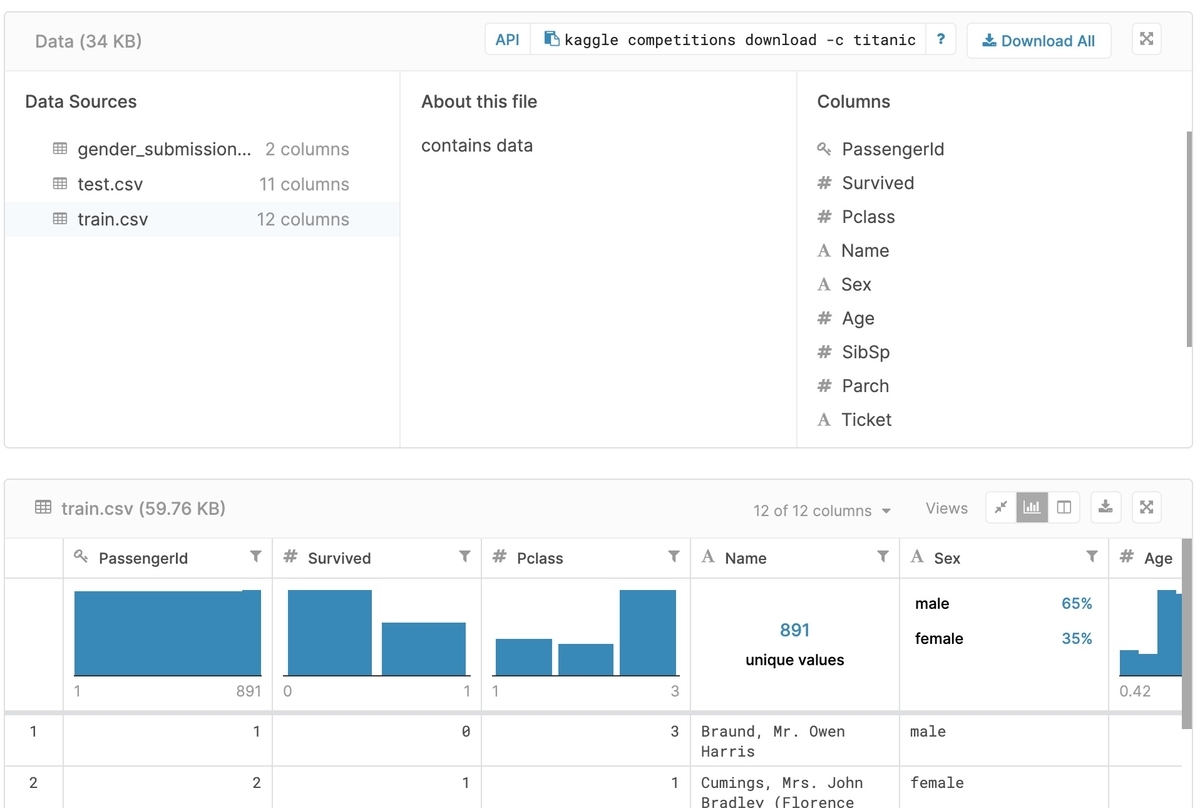
[Data Dictionary]で確認したのは10パラメータでしたが、12パラメータに増えています。 増えたのは"Passenger ID"と"Name"です。
家族関係のパラメータがあったので、"Name"は予測に使えそうです。 "Passenger ID"はユニークな番号というだけで予測に使うことはなさそうです。
[2-3] 予測結果を提出してみる
サンプルとして用意されていた「gender_submission.csv」をそのまま提出してみます。
[2-3-1] サンプルのダウンロード
「gender_submission.csv」を選択するとダウンロードボタンが表示されるのでクリックします。
[2-3-2] 予測結果をアップロード
[Submit Predictions]をクリックすると、提出用の画面が開きます。
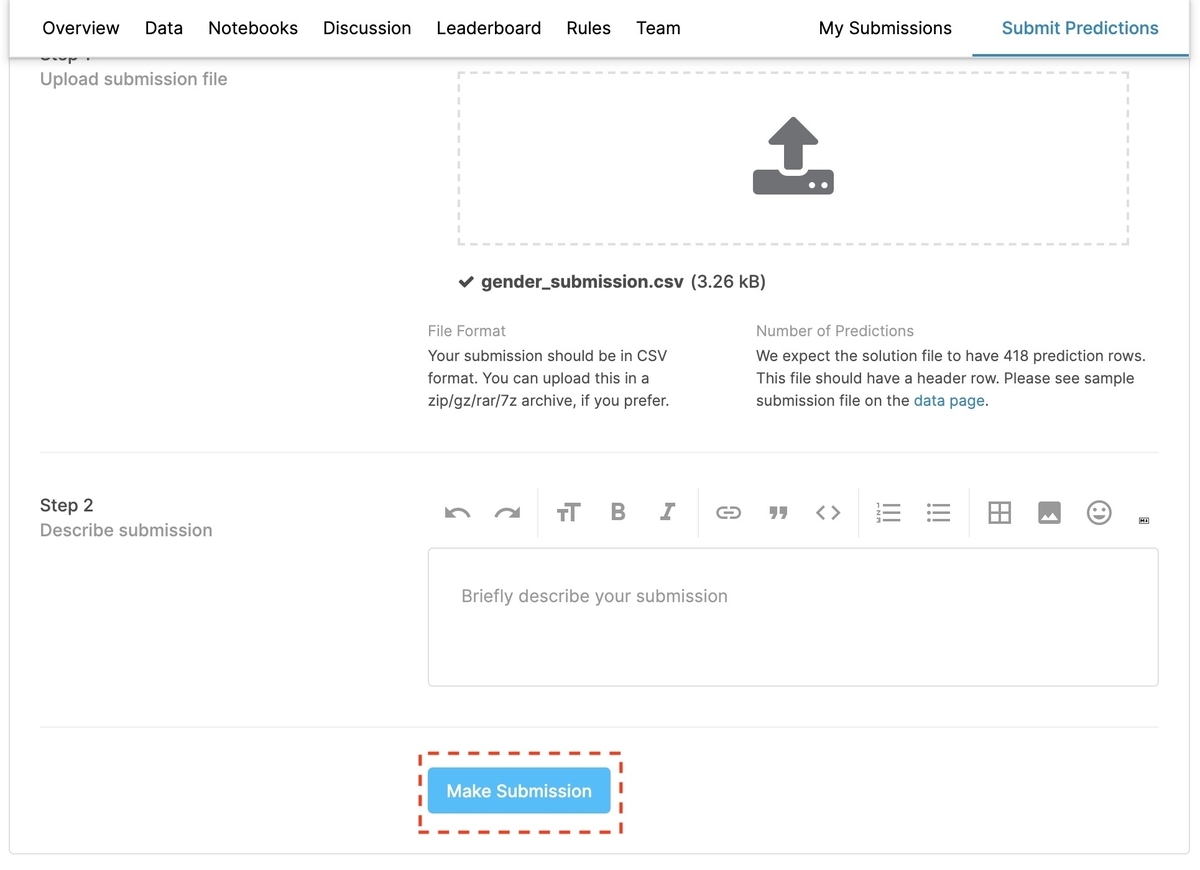
Step1 中央のボタンをクリックすると、ファイル選択ダイアログが表示されるので、先ほどダウンロードしたサンプルをそのままアップロードします。
[2-3-3] 予測結果を提出
画面下部の[Make Submission]を押せば、予測結果の提出が完了します。

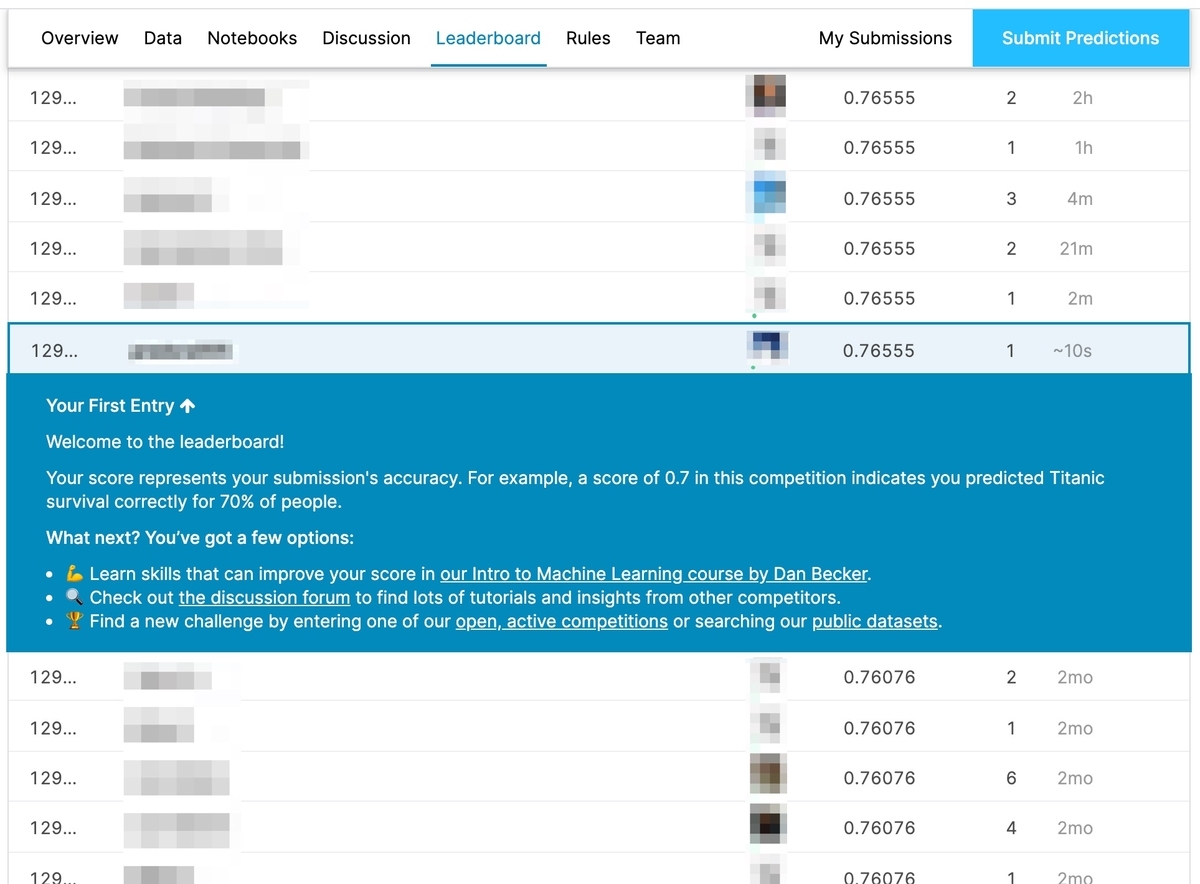
[2-4] 順位を確認する
先ほどの画面の[Jump to your position on the leaderboard]をクリックします。 すると、Leaderboardが表示され、自分の順位が確認できます。 私の結果は、16000チーム中12900位くらいでした。
終わりに
今回はコンペ参加から、予測結果(サンプルそのまま)を提出するところまでを御紹介しました。次回はチュートリアルを参考に、予測精度の向上に取り組みます。
参考にさせていただいたサイト
【機械学習】Kaggleの始め方(アカウント作成)
データ分析コンペ「Kaggle」の始め方を紹介します。
※ 2020/02/27にQrunchで書いた記事を移行しました。
Kaggleとは
データ分析の腕をきそうコンペティションの1つです。 コンペの中でもかなり有名です。Kaggleは2017年にGoogleに買収され子会社にもなっています。
Kaggleの良いところは色々ありますが、代表的なのは以下の3点ではないかと思います。
- 基本的なデータ分析環境が用意されており初心者も参加しやすい。
- コミュニティが充実していて情報交換が行える。上位者の分析方法が公開されることも多い。
- 実社会で扱われるデータセットを使用できる。
アカウント作成
[1] Kaggleのサイトにアクセス
Kaggleのサイトにアクセスし右上の[Register]をクリックします。
Googleアカウントを持っている方は[Register with Google]でOKです。 私はEmailアドレスで登録の[Register with your email]で登録しました。
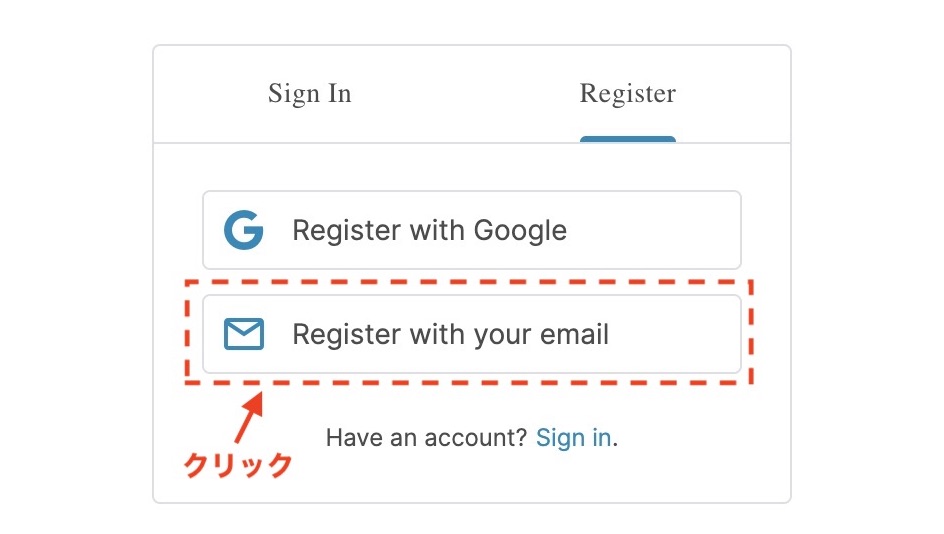
[2] ユーザー情報を入力
[2-1] 入力する項目は4つ
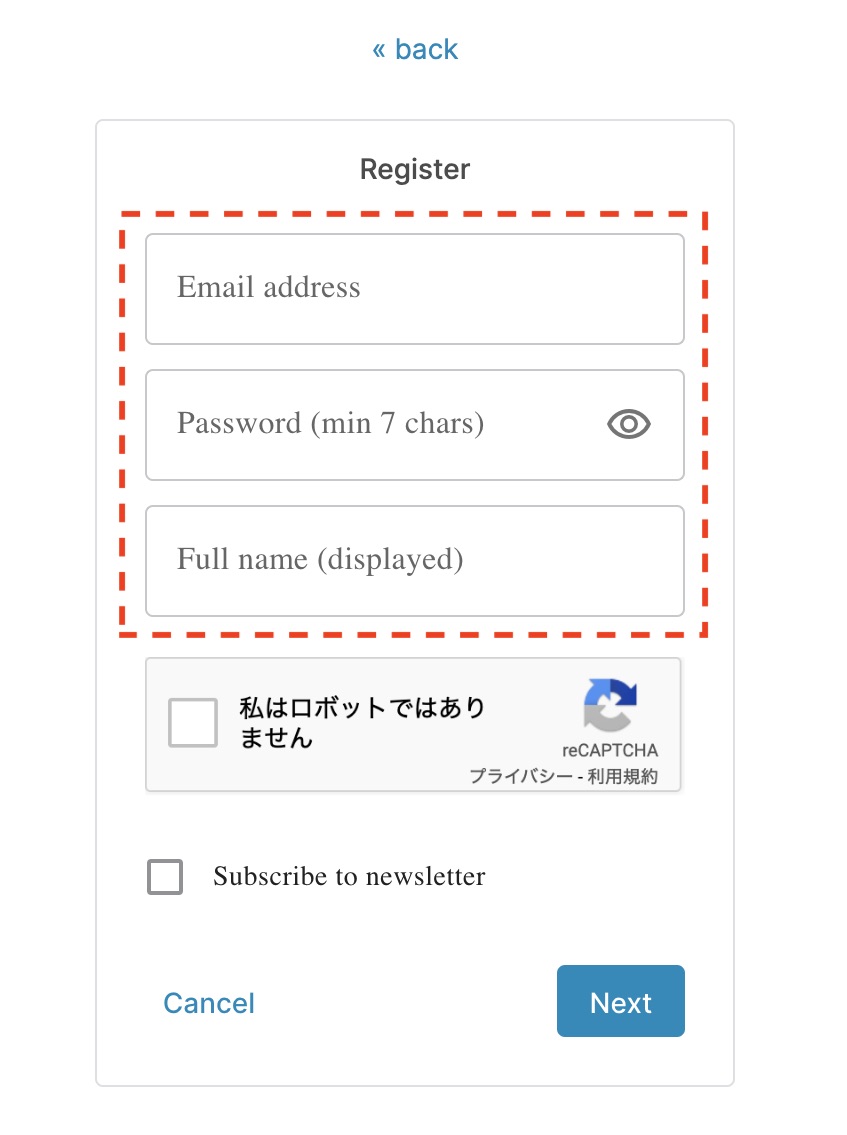
2020年2月時点で入力の必要な情報は、Email address, Password, Full name, Usernameの4点です。 Usernameは最初は非表示ですが、Full nameを入力すると編集できるようになります。

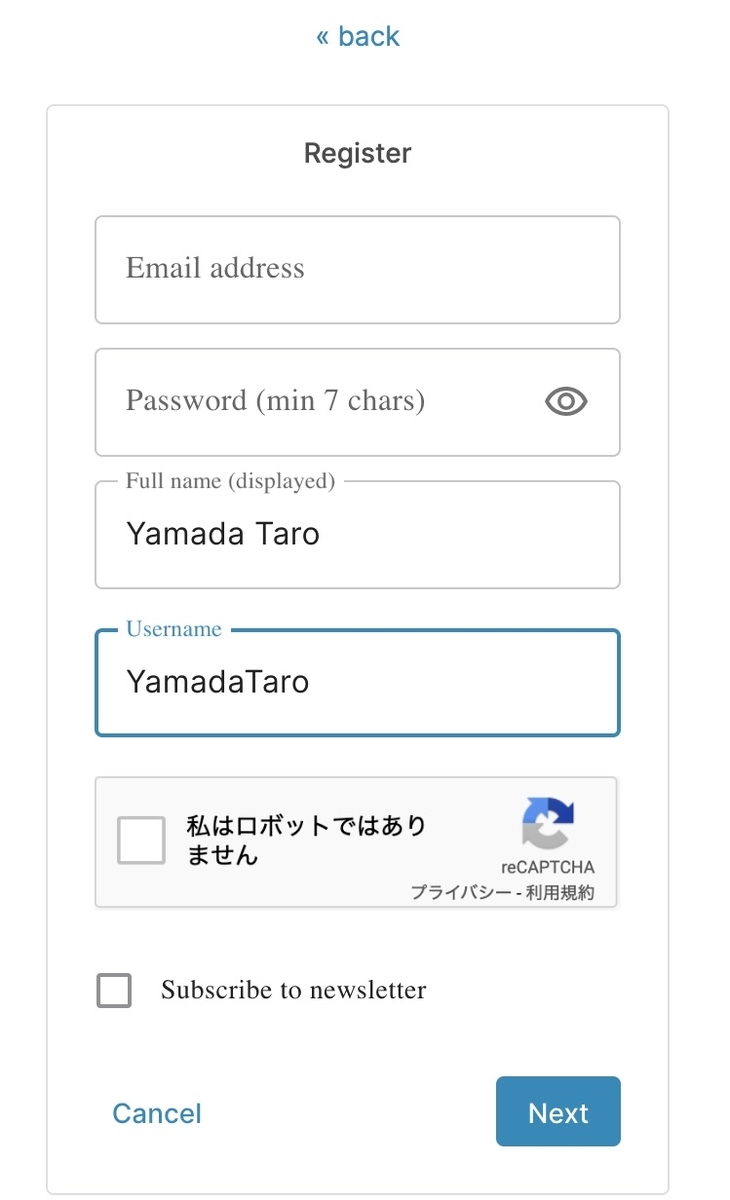
[2-2] Usernameに注意
Usernameは変更不可なので注意が必要です。
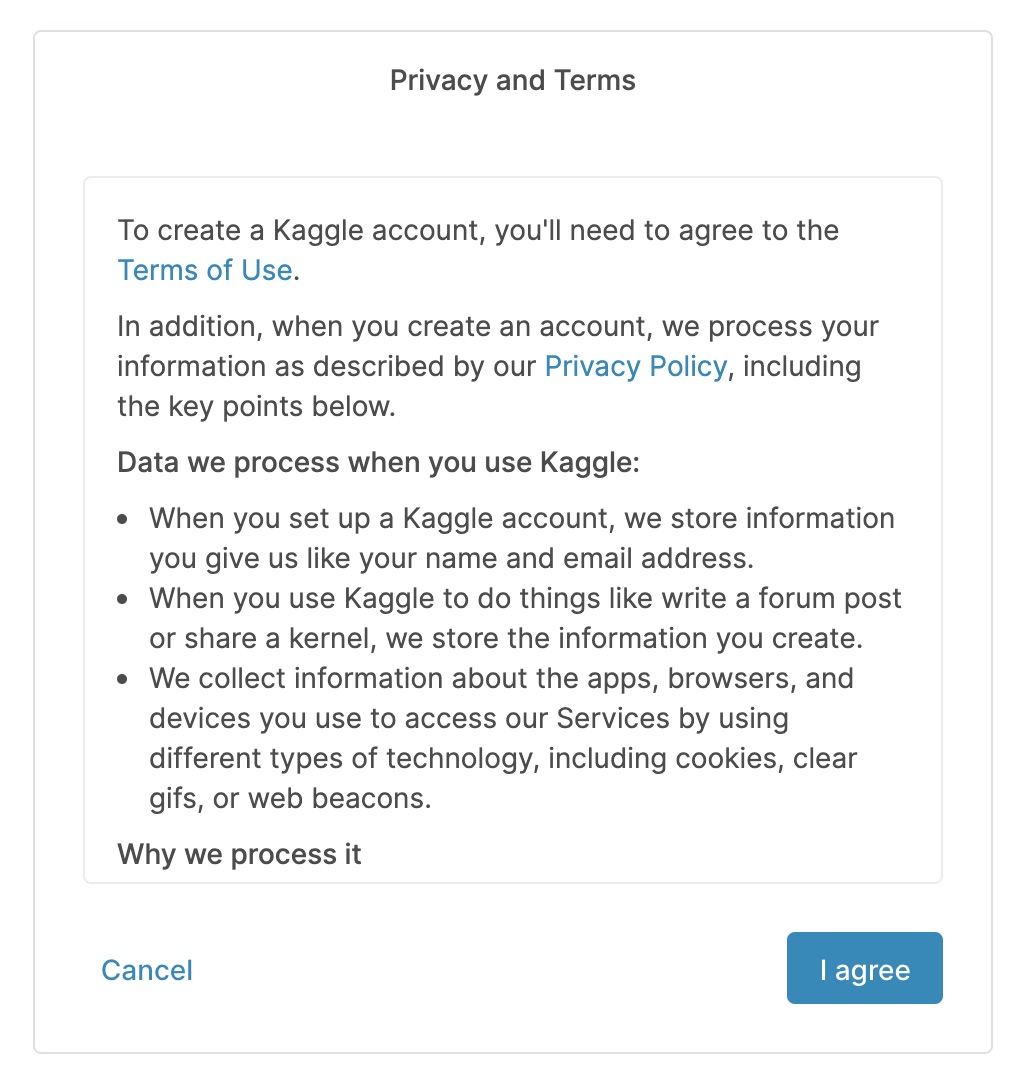
[2-3] 個人情報の取り扱いに同意
入力を終え[Next]を押すと、個人情報の取り扱いの同意を求められるので同意します。
[2-4] メールを確認する
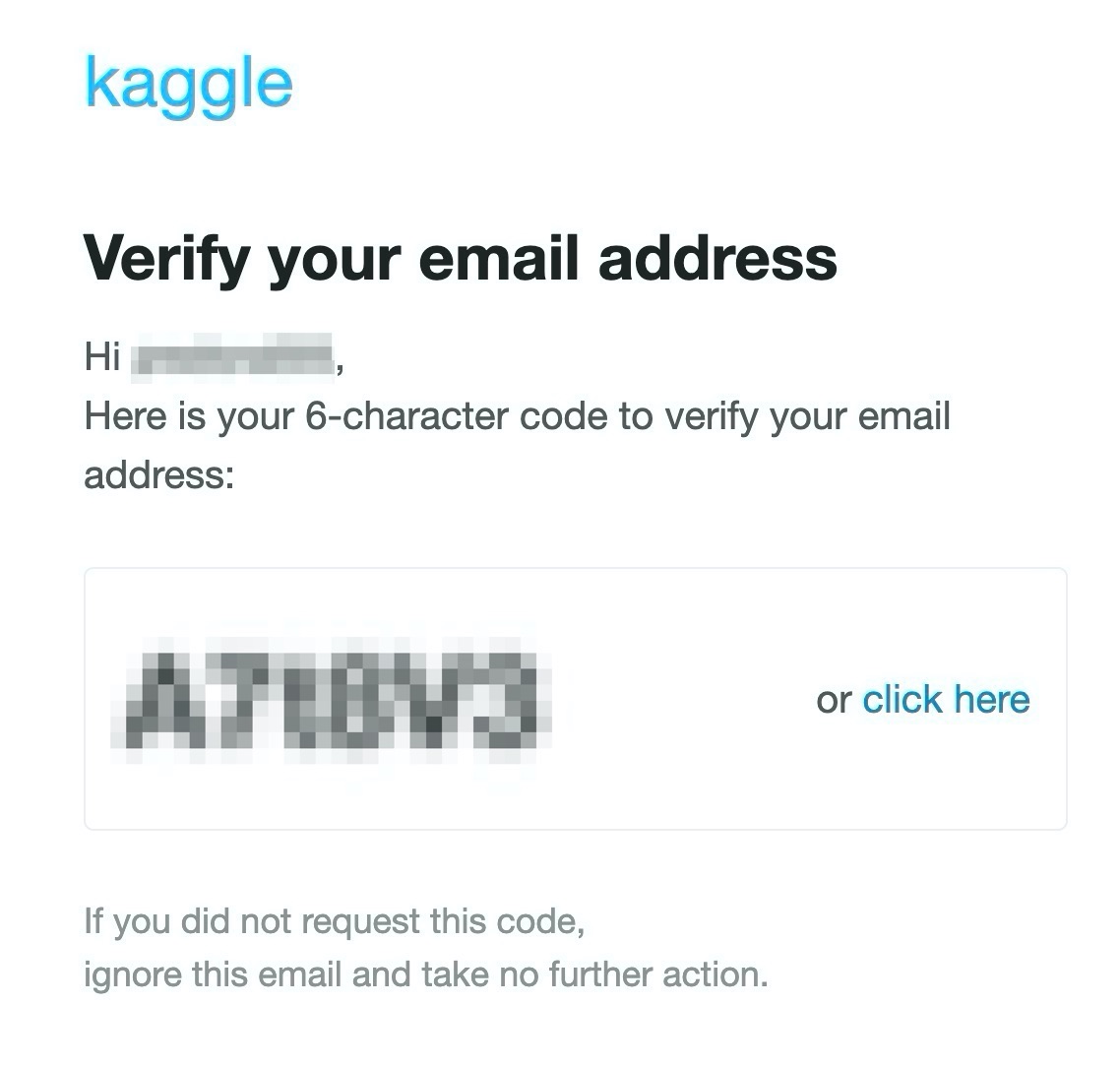
Kaggleからメールが届いているので、[click here]を押すか、6桁のコードを入力します。
[2-5] アカウント作成完了
以上で、アカウント作成は完了です。
[3] ユーザー情報の編集
以降は、必須ではありません。 アカウント作成直後はこのような状態です。

[3-1] アイコンの変更
[Edit Profile]をクリックしたのち、デフォルトのアイコン(アヒル?)をクリックします。
すると、画像のアップロード画面が表示されるので、アイコンにしたい画像をアップロードします。
[3-2] 他サービスのアカウント設定
GitHub, Twitter, LinkedIn, Websiteの4つを登録できます。 GitHubとTwitterはUser ID、LinkdInとWebsiteはURLを入力します。

終わりに
登録は簡単にできました。 次の記事では「Titanicコンペ」への参加方法を紹介しています。
【機械学習】pandasでCSV読み込み

※ 2020/02/16にQrunchで書いた記事を移行しました。
Pyhtonで機械学習を行うとき、入力データをCSVファイルから取得することがあります。
Pythonで機械学習と言えばnumpyが欠かせませんが、CSVファイルの読み込みはpandasで行うと大変便利です。数行のコードで大抵のことは出来てしまいます。
pandaで読み込んだデータをnumpy形式(ndarray)に変換して、機械学習用のライブラリに渡してあげればOKです。
公式のリファレンスを参考に、色々なCSVファイルを読み込んでみました。
- read_csvで読み込み
- タブ区切りのファイル読み込み
- タイトル行が無い場合
- タイトル行が複数の場合
- 任意の列名を付ける
- インデックス列を指定する
- インデックス列を複数指定する
- 指定した列のみを読み込む
- スペースを無視したい場合
- 指定した行を飛ばす
- na_values
- 日付をdatatime型として読み込む
- データ型を指定する
- より詳しいことを知りたい方は
read_csvで読み込み
A,B,C,D,E 0,1,2,3,4 5,6,7,8,9 10,11,12,13,14
上記のようなCSVファイルを読み込む場合、以下のように書くと、
# coding: utf-8 import pandas as pd df = pd.read_csv('foo.csv') print(df) # A B C D E # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14
デフォルトでは、先頭行をタイトル行(A,B,C,D,E)として読み込みます。 各行のインデックス(0,1,2)は自動で付与されます。
タブ区切りのファイル読み込み
A___B___C___D___E 0___1___2___3___4 5___6___7___8___9 10___11___12___13___14
タブ区切りのファイルを読み込む場合はsep='\t'を指定します。
df = pd.read_csv('foo.csv', sep='\t') print(df) # A B C D E # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14
カンマとタブ区切りに限らず、sepで区切り文字を指定できます。
タイトル行が無い場合
0,1,2,3,4 5,6,7,8,9 10,11,12,13,14
タイトル行の無いCSVファイルを読み込む場合はheader=Noneを指定します。
df = pd.read_csv('foo.csv', header=None) print(df) # 0 1 2 3 4 # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14
列の名前は自動で付与してくれます。
タイトル行が複数の場合
A,A,B,B,C a,b,a,b,a 0,1,2,3,4 5,6,7,8,9 10,11,12,13,14
タイトル行が複数ある場合はheader=[0,1]のように、リストで行番号を指定します。
df = pd.read_csv('foo.csv', header=[0,1]) print(df) # A B C # a b a b a # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14
任意の列名を付ける
0,1,2,3,4 5,6,7,8,9 10,11,12,13,14
タイトル行を自分で付ける場合はnamesに名称を指定します。
df = pd.read_csv('foo.csv', names=['a','b','c','d','e']) print(df) # a b c d e # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14
インデックス列を指定する
,A,B,C,D,E i,0,1,2,3,4 j,5,6,7,8,9 k,0,1,2,3,4
インデックス列を指定する場合はindex_colに整数を指定します。
df = pd.read_csv('foo.csv', index_col=0) print(df) # A B C D E # i 0 1 2 3 4 # j 5 6 7 8 9 # k 0 1 2 3 4
列名を指定することも出来ます。以下はA列を指定した例です。
df = pd.read_csv('foo.csv', index_col='A') print(df) # Unnamed: 0 B C D E # A # 0 i 1 2 3 4 # 5 j 6 7 8 9 # 0 k 1 2 3 4
インデックス列を複数指定する
,,A,B,C,D,E i,k,0,1,2,3,4 i,l,5,6,7,8,9 j,m,0,1,2,3,4
インデックス列を複数指定する場合はindex_col=[0,1]のように、リストで列番号を指定します。
df = pd.read_csv('foo.csv', index_col=[0,1]) print(df) # A B C D E # i k 0 1 2 3 4 # l 5 6 7 8 9 # j m 0 1 2 3 4
列名を複数指定する場合も同様に、リストで指定します。
df = pd.read_csv('foo.csv', index_col=['A','B']) print(df) # Unnamed: 0 Unnamed: 1 C D E # A B # 0 1 i k 2 3 4 # 5 6 i l 7 8 9 # 0 1 j m 2 3 4
名称が付いていない列はUnnamed: 〜が自動で付与されます。
指定した列のみを読み込む
,A,B,C,D,E i,0,1,2,3,4 j,5,6,7,8,9 k,0,1,2,3,4
指定した列のみを読み込む場合はusecols[0,1]のようにリスト形式で指定します。
df = pd.read_csv('foo.csv', usecols=[1,2]) print(df) # A B # 0 0 1 # 1 5 6 # 2 0 1
列名を指定することも可能です。
df = pd.read_csv('foo.csv', usecols=['A','E']) print(df) # A E # 0 0 4 # 1 5 9 # 2 0 4
また、ラムダ式で条件を設定し、条件に合致する列のみを読み込むことも出来ます。
df = pd.read_csv('foo.csv', usecols=lambda s: s < 'C') print(df) # A B # 0 0 1 # 1 5 6 # 2 0 1
スペースを無視したい場合
no, name, age 1, Taro, 15 2, Jiro, 10 3, Saburo, 5
上記のように、区切り文字の後ろに半角スペースが含まれる場合、半角スペースも一緒に読み込まれてしまいます。数値の場合は問題ないのですが、列名や文字列データに余分なスペースが含まれてしまいます。
df = pd.read_csv('foo.csv') print(df) # no name age # 0 1 Taro 15 # 1 2 Jiro 10 # 2 3 Saburo 5 print(df.columns) # Index(['no', ' name', ' age'], dtype='object')
半角スペースを飛ばしたい場合はskipinitialspace=Trueを指定します。
df = pd.read_csv('foo.csv', skipinitialspace=True) print(df) # no name age # 0 1 Taro 15 # 1 2 Jiro 10 # 2 3 Saburo 5 print(df.columns) # Index(['no', 'name', 'age'], dtype='object')
指定した行を飛ばす
foo.csv A,B,C,D,E 0,1,2,3,4 5,6,7,8,9 10,11,12,13,14
上記のように1,2行目は読込不要の場合はskiprows=[0,1]のように、リストで読込不要な行の番号を指定します。
df = pd.read_csv('foo.csv', skiprows=[0,1]) print(df) # A B C D E # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14
na_values
A,B,C,D,E 0,1,2,3,NG 5,6,,,9 -,-,12,13,14
空白は、欠損=NaN(numpy.nan)として読み込まれます。
df = pd.read_csv('foo.csv') print(df) # A B C D E # 0 0 1 2.0 3.0 NG # 1 5 6 NaN NaN 9 # 2 - - 12.0 13.0 14
空白以外にも欠損=NaNに指定したいデータがある場合はna_valuesで指定します。
df = pd.read_csv('foo.csv', na_values=['-','NG']) print(df) # A B C D E # 0 0.0 1.0 2.0 3.0 NaN # 1 5.0 6.0 NaN NaN 9.0 # 2 NaN NaN 12.0 13.0 14.0
日付をdatatime型として読み込む
date,Temp.,Humidity 2017/1/1,-1.1,10 2017/1/2,-2.2,20 2017/1/3,-3.3,30
日付データはデフォルトでは、object型として読み込まれます。
df = pd.read_csv('foo.csv') print(df) # date Temp. Humidity # 0 2017/1/1 -1.1 10 # 1 2017/1/2 -2.2 20 # 2 2017/1/3 -3.3 30 print(df.dtypes) # date object # Temp. float64 # Humidity int64 # dtype: object
日付として読み込みたい列をparse_datesで指定します。
列番号で指定しても列名で指定しても動作します。
下記例ではparse_dates=['date']をparse_dates=[0]に変えても同じように動作します。
df = pd.read_csv('foo.csv', parse_dates=['date']) print(df) # date Temp. Humidity # 0 2017-01-01 -1.1 10 # 1 2017-01-02 -2.2 20 # 2 2017-01-03 -3.3 30 print(df.dtypes) # date datetime64[ns] # Temp. float64 # Humidity int64 # dtype: object
データ型を指定する
no,name,age,height 1,Taro,50,170 2,Sachiko,40,160 3,Masami,30,180
データ型を指定しない場合、自動でデータ型を判定してくれますが、それでは不都合な場合もあります。上記例では"height"は実数型(float)で扱ってほしいのですが整数型(int)と判定されます。
df = pd.read_csv('foo.csv') print(df) # no name age height # 0 1 Taro 50 170 # 1 2 Sachiko 40 160 # 2 3 Masami 30 180 print(df.dtypes) # no int64 # name object # age int64 # height int64 # dtype: object
データ型を指定したい場合にはdtypeで型を指定します。
np.int64やnp.float64は"Int64"のように文字列で指定することも可能です。
import numpy as np df = pd.read_csv('foo.csv', dtype={'no': np.int64, 'name': object, 'age': np.int64, 'height': np.float64} ) print(df) # no name age height # 0 1 Taro 50 170.0 # 1 2 Sachiko 40 160.0 # 2 3 Masami 30 180.0 print(df.dtypes) # no int64 # name object # age int64 # height float64 # dtype: object
より詳しいことを知りたい方は
pandas公式のUser GuideやCookbookにより詳しく使い方が載っています。 IO tools (text, CSV, HDF5, …) — pandas 1.0.1 documentation< Cookbook — pandas 1.0.1 documentation
【AWS】Amazon Linux 2でJupyter Notebookを使えるようにするまで

Amazon Linux 2でJupyter Notebookを使えるようにするまで*1
※ 2020/02/26にQrunchで書いた記事を移行しました。
Jupyter Notebookは機械学習を実行する環境として有名です。 機械学習には触れてきましたが、Jupyter Notebookには触れてこなかったので使ってみようと思いました。 使用する言語はPython3です。
- なぜAmazon Linuxなのか
- [1] EC2インスタンスを作成する
- [2] 各種パッケージをインストール
- [3] Jupyter Notebookのインストールと設定
- [4] 動作確認
- [5] Jupyter Notebookを自動起動する
- 終わりに
なぜAmazon Linuxなのか
私がAWSを使い慣れているから、ただそれだけです。 Google ColaboratoryやGCP, 御自分のPCでJupyter Notebookを使われても問題ないと思います。むしろ、そちらの方が便利かもしれません。
[1] EC2インスタンスを作成する
OSがAmazon Linux2のEC2インスタンスを作成します。 NAT構成などは考えず、シンプルな1台構成の場合について書きます。
[1-1] セキュリティグループの設定
インバウンド
ブラウザからJupyter Notebookにアクセスするために、ポート8888を許可します。 ポート番号は8888以外でも可能です。このあと行うJupyter Notebookの設定と一致していれば問題ありません。
| タイプ | プロトコル | ポート範囲 | ソース |
|---|---|---|---|
| カスタム TCP ルール | TCP | 8888 | 0.0.0.0/0 |
| SSH | TCP | 22 | 0.0.0.0/0 |
アウトバウンド
| タイプ | プロトコル | ポート範囲 | ソース |
|---|---|---|---|
| HTTP | TCP | 80 | 0.0.0.0/0 |
| HTTPS | TCP | 443 | 0.0.0.0/0 |
[2] 各種パッケージをインストール
[2-1] yumのupdate
お決まりの手順ですが、まずはyumのupdateを行います。
$ sudo yum -y update
[2-2] Python3のインストール
Python3をインストールします。
$ sudo yum -y install python3 python3-devel
[3] Jupyter Notebookのインストールと設定
[3-1] Jupyter Notebook用のユーザー作成
Jupyter Notebook実行用のユーザーを作成します。
$ sudo useradd jupyter $ sudo passwd jupyter
[3-2] Jupyter Notebookのインストール
[3-1]で作成したユーザーにスイッチし、jupyterをインストールします。 (1)Anacondaをインストールする方法と、(2)Jupyter Notebook単体でインストールする方法の2種類ありますが、(2)Jupyter Notebook単体でインストールする方法を採用しました。
$ su - jupyter
$ pip3 install jupyter --user
Anacondaであればデータサイエンスに必要な各種ライブラリがまとめてインストールされますが、容量を食いそうなので、Jupyter Notebook単体でインストールしておきます。
[3-3] Jupyter Notebookの設定1
jupyter_notebook_config.pyというファイルに設定情報を書いていきます。
$ mkdir .jupyter
$ vim .jupyter/jupyter_notebook_config.py
jupyter_notebook_config.pyの中身は次の通りです。
c.NotebookApp.notebook_dir = '/home/jupyter/' c.NotebookApp.ip = '*' c.NotebookApp.open_browser = False # c.NotebookApp.port = 8888 # デフォルトは8888
jupyter notebook --generate-configを叩くと、~/.jupyter/jupyter_notebook_config.pyを雛形として作ってくれますが、雛形は使用せず最低限の情報だけを書きました。
[3-4] Jupyter Notebookの設定2
このままだとセキュリティ的によろしくないので、パスワード認証を追加します。
python3 -c 'from notebook.auth import passwd;print(passwd())' Enter password: Verify password: sha1:*****************************************************
表示されたsha1:***をコピーし、jupyter_notebook_config.pyのc.NotebookApp.passwordにペーストします。
c.NotebookApp.password = 'sha1:*****************************************************`
[4] 動作確認
[4-1] Jupyter Notebookの起動
$ jupyter notebook [I 14:36:03.057 NotebookApp] Writing notebook server cookie secret to /home/ec2-user/.local/share/jupyter/runtime/notebook_cookie_secret [W 14:36:03.245 NotebookApp] WARNING: The notebook server is listening on all IP addresses and not using encryption. This is not recommended. [I 14:36:03.248 NotebookApp] Serving notebooks from local directory: /home/ec2-user/.jupyter [I 14:36:03.248 NotebookApp] The Jupyter Notebook is running at: [I 14:36:03.248 NotebookApp] http://ip-10-3-0-10.ap-northeast-1.compute.internal:8888/ [I 14:36:03.248 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[4-2] ブラウザから接続
ブラウザでhttp://[EC2インスタンスのグローバルIP]:8888にアクセスします。
JupyterNotebookが起動してればログイン画面が表示されます。
先ほど設定したパスワードを入力すると無事にログインできました。

[5] Jupyter Notebookを自動起動する
CentOS7にJupyter Notebookを導入とサービス化したJupyter notebookからローカルに構築したtensorflowを使えるようにしたを参考にさせていただきました。
[5-1] jupyterのパスを確認する
このあと作成するユニットファイルに、jupyterのフルパスを設定します。
$ which jupyter
~/.local/bin/jupyter
[5-2] ユニットファイルを作成する
ここからはec2-userで操作を行います。jupyterユーザーはsudoersではないので (jupyterユーザーをsudoersに追加する方法でも問題ありません)。
$ exit logout
jupyter用のユニットファイルを作成します。
$ sudo vim /etc/systemd/system/notebook.service
ユニットファイルの内容は以下の通りです。
[Unit] Description = Jupyter Notebook [Service] Type=simple PIDFile=/var/run/jupyter-notebook.pid ExecStart=/home/jupyter/.local/bin/jupyter notebook WorkingDirectory=/home/jupyter/ User=jupyter Group=jupyter Restart=always [Install] WantedBy = multi-user.target
[5-3] EC2インスタンス立上時に起動する
$ sudo systemctl enable notebook
Created symlink from /etc/systemd/system/multi-user.target.wants/notebook.service to /etc/systemd/system/notebook.service.
[5-4] 本当に起動しているのか確認する
$ systemctl status notebook ● notebook.service - Jupyter Notebook Loaded: loaded (/etc/systemd/system/notebook.service; enabled; vendor preset: disabled) Active: active (running) since 火 2020-02-25 16:28:19 UTC; 30s ago
終わりに
手順がそれなりに多かったため少々面倒でした。 頻繁にEC2インスタンスの削除・作成を行う場合は、コード化した方がよいでしょう。 パスワード入力のところ以外はコード化可能だと思います(パスワード入力も不可能ではありませんがやりたくはない)。
また、今回はSSL/TLSは使いませんでしたが、セキュリティ的には使った方がよいでしょう。
Running a notebook server — Jupyter Notebook 7.0.0.dev0 documentation