【機械学習】Kaggleの始め方(Titanicコンペに参加する)
Kaggleの入門用コンペ「Titanic」の参加方法を紹介します。
※ 2020/02/29にQrunchで書いた記事を移行しました。
Titanicコンペは入門用コンペ
アカウント作成後にKaggleからメールが送られてきており、Titanicコンペへの参加を薦められます。 Titanicコンペは、タイタニック号の乗客のうち誰が生き延びたかを予測するコンペです。 期限のない「入門用コンペ」です。

[1] コンペに参加する
[1-1] Titanicコンペのページを開く
メールの[Check out the Titanic Machine Learning Competition]をクリックし、Titanicコンペのページを開きます。
[Join Competition]をクリックすると、ルールを読むように勧められます。

[1-2] ルール
ルールを日本語訳したものを表にしました。 チームを組むのはOK、チーム外で非公開に協力することはNG、提出物は1日に10個まで、というKaggleの中ではオーソドックスなルールのようです。 入門用コンペなので期限は無しとなっています。
| 見出し | 内容 |
|---|---|
| 参加者ごとに1つのアカウント | 複数のアカウントからKaggleにサインアップできないため、複数のアカウントから送信することはできません。 |
| チーム外のプライベート共有はありません | チーム外でコードやデータを個人的に共有することは許可されていません。フォーラムのすべての参加者が利用できるようになっている場合、コードを共有しても構いません。 |
| チーム合併 | チームの合併は許可されており、チームリーダーが実行できます。統合するには、統合チームの合計提出件数が、統合日時点で許可されている最大数以下でなければなりません。許可される最大数は、1日あたりの提出数に競争が行われた日数を掛けたものです。 |
| チームの制限 | チームの最大サイズはありません。 |
| 提出制限 | 1日に最大10個のエントリを送信できます。審査のために最大5つの最終提出物を選択できます。 |
| 競技タイムライン | 開始日:2012年9月28日午後9時13分UTC 合併期限:なし 応募締め切り:なし 終了日:なし これは、機械学習の開始を支援することを目的とした楽しいコンテストです。Titanicデータセットはインターネットで公開されていますが、回答を検索すると全体の目的に反します。真剣に、それをしないでください。 |
[1-3] 参加完了
ルールを確認し[I Understand And Accept]を押せば参加完了です。 [Join Competition]が[Submit Predictions]に替わっています。
[2] チュートリアルを参考に進める
公式の動画でも、Alexis Cook’s Titanic Tutorialを見るように勧めているので、まずはTutorialを参考に進めてみることにします。

[2-1] 概要を確認する
[Overview]タブで概要を確認します。 タイタニック号でどの乗客が生き延びたかを予測することが目的だと分かりました。
競争は単純です。機械学習を使用して、どの乗客がタイタニック号の難破船を生き延びたかを予測するモデルを作成します。
タイタニック号の沈没は、歴史上最も悪名高い難破船の1つです。 1912年4月15日、処女航海中に、広く考えられている「沈められない」RMSタイタニック号は、氷山と衝突した後、沈没しました。残念ながら、乗船する全員に十分な救命艇がなかったため、2224人の乗客と乗組員のうち1502人が死亡しました。 生き残るためには運の要素がいくつかありましたが、一部のグループは他のグループよりも生き残る可能性が高いようです。 この課題では、「どのような人々が生き残る可能性が高かった」という質問に答える予測モデルを構築するよう求めます。乗客データ(名前、年齢、性別、社会経済クラスなど)を使用します。
[2-2] データを確認する
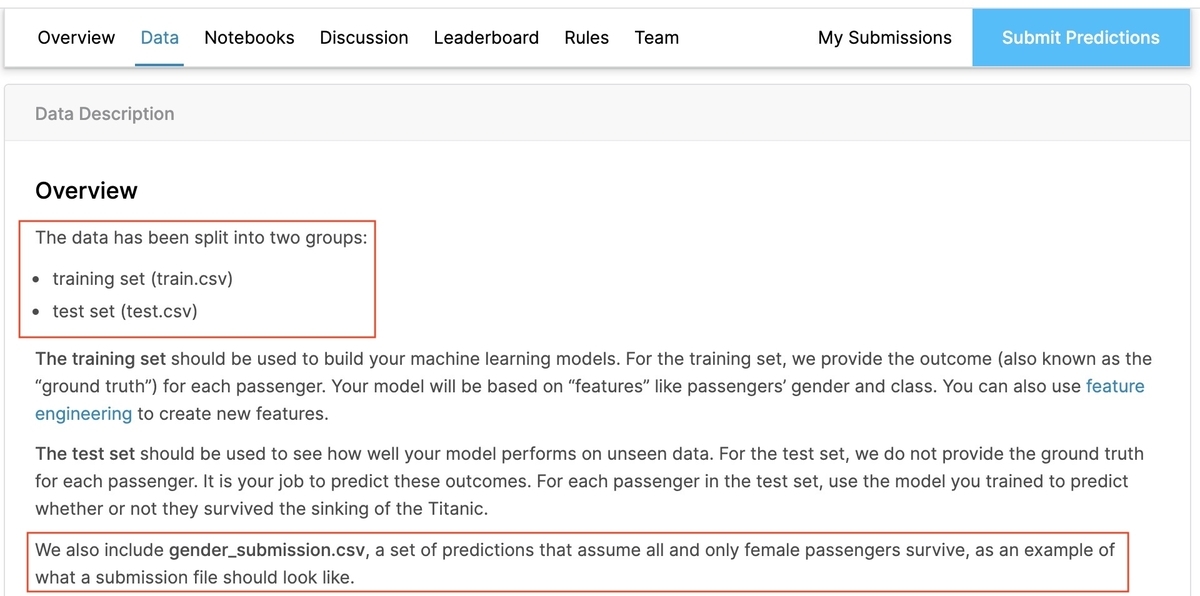
[Data]タブで概要を確認します。
[2-2-1] 入力データ
学習用データの「train.csv」、テスト用データの「test.csv」の2つが入力データであることが分かります。
[2-2-2] 提出ファイルのサンプル
Kaggleでは提出ファイルのサンプルも用意されており、Titanicコンペでは「gender_submission.csv 」が該当します。 自分の予測結果を提出する際は、サンプルと同じフォーマットで提出します。
[2-2-3] 入力パラメータ
10パラメータについて説明が書かれています。
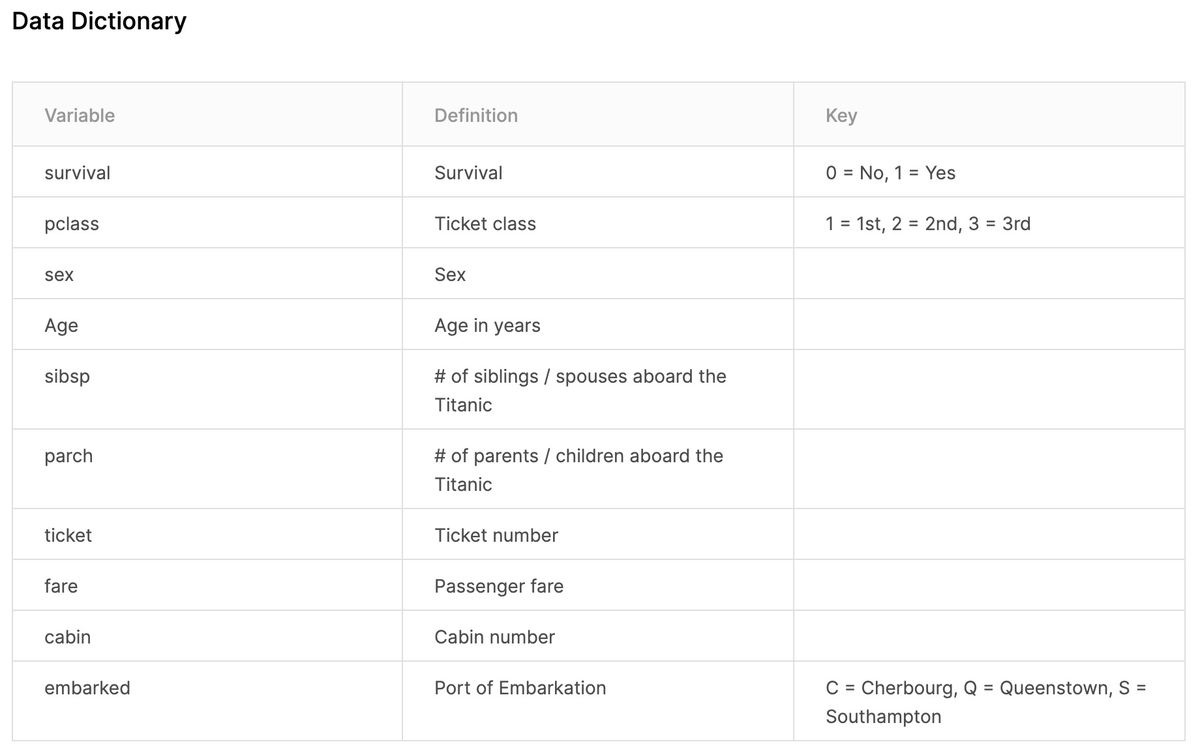
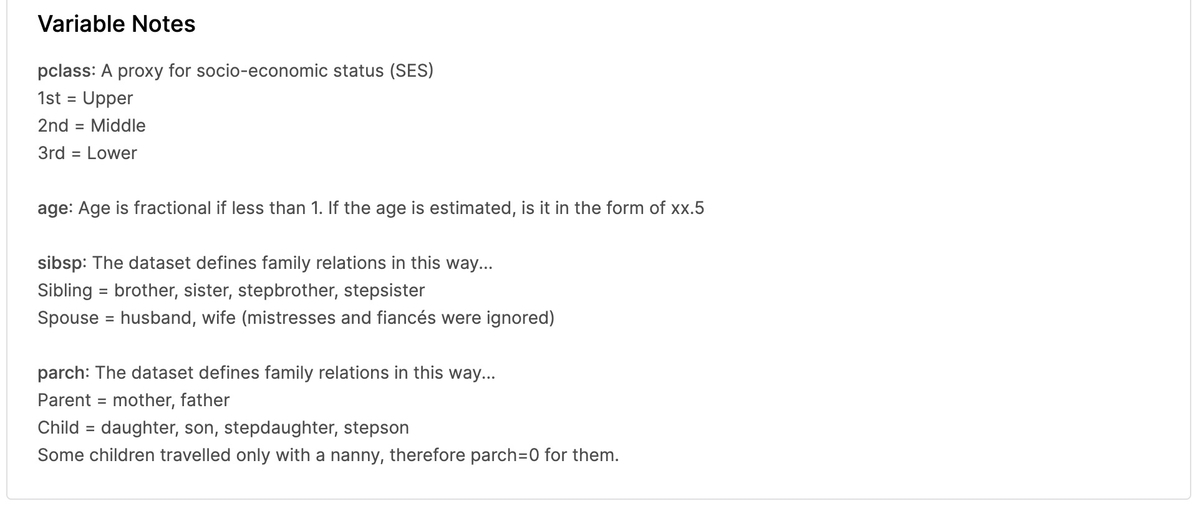
説明の必要なパラメータについては「Variable Notes」に詳細が書かれています。
- pclass:社会経済的地位
- sibsp:家族関係 - Sibling:兄、妹、義兄、義姉妹 - Spouse:夫、妻(愛人と婚約者は無視された)
- parch:家族関係 - Parent:母、父 - Child:娘、息子、義理の娘、義理の息子 - 一部の子供は乳母と一緒に旅行したので、彼らはparch = 0でした。
のようです。私は英語が得意ではないので、Google翻訳の力を借りて進めました。
[2-2-4] 入力データの中身
以下が実際の入力データです。 ファイルは「train.csv」「test.csv」「gender_submission.csv」の3つです。 ブラウザ上で見ることも出来ますし、ダウンロードも出来ます。
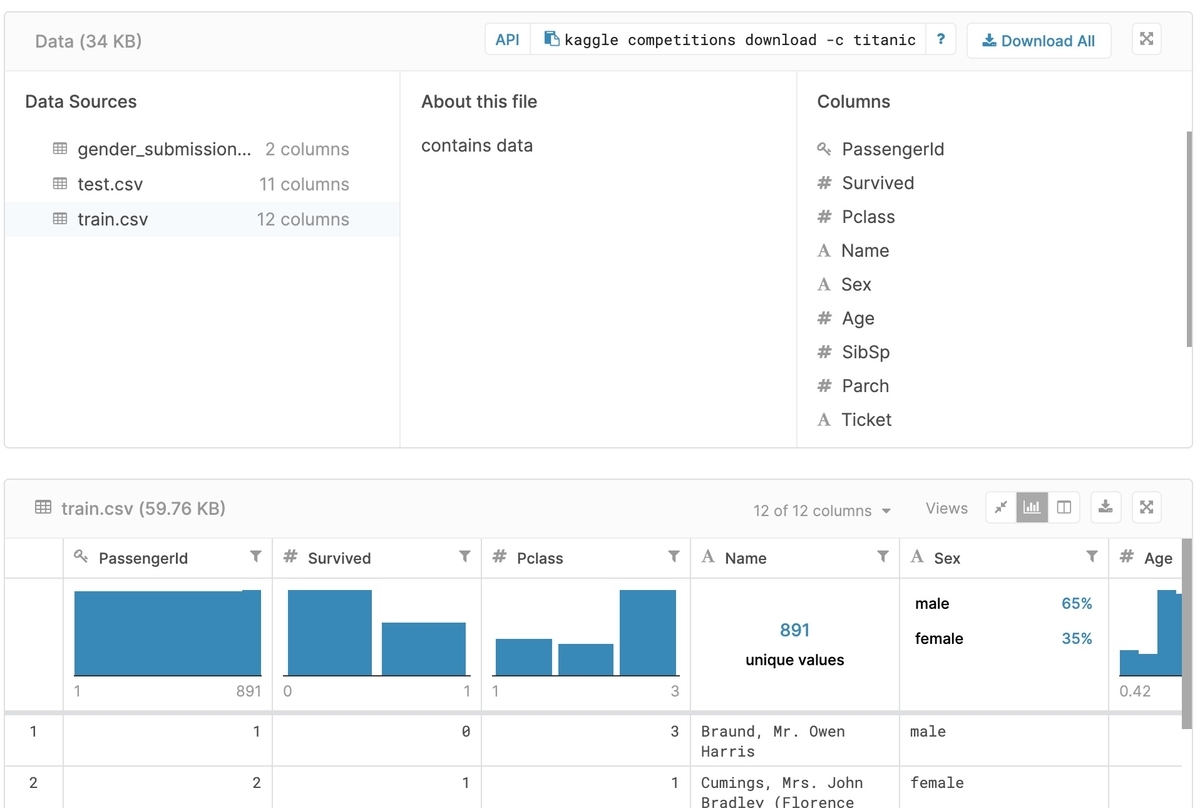
[Data Dictionary]で確認したのは10パラメータでしたが、12パラメータに増えています。 増えたのは"Passenger ID"と"Name"です。
家族関係のパラメータがあったので、"Name"は予測に使えそうです。 "Passenger ID"はユニークな番号というだけで予測に使うことはなさそうです。
[2-3] 予測結果を提出してみる
サンプルとして用意されていた「gender_submission.csv」をそのまま提出してみます。
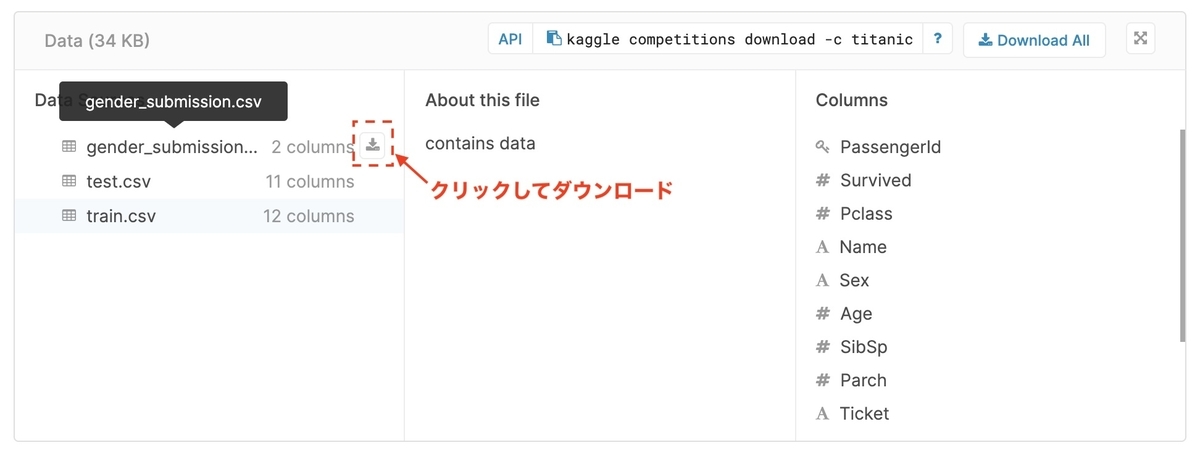
[2-3-1] サンプルのダウンロード
「gender_submission.csv」を選択するとダウンロードボタンが表示されるのでクリックします。
[2-3-2] 予測結果をアップロード
[Submit Predictions]をクリックすると、提出用の画面が開きます。
Step1 中央のボタンをクリックすると、ファイル選択ダイアログが表示されるので、先ほどダウンロードしたサンプルをそのままアップロードします。
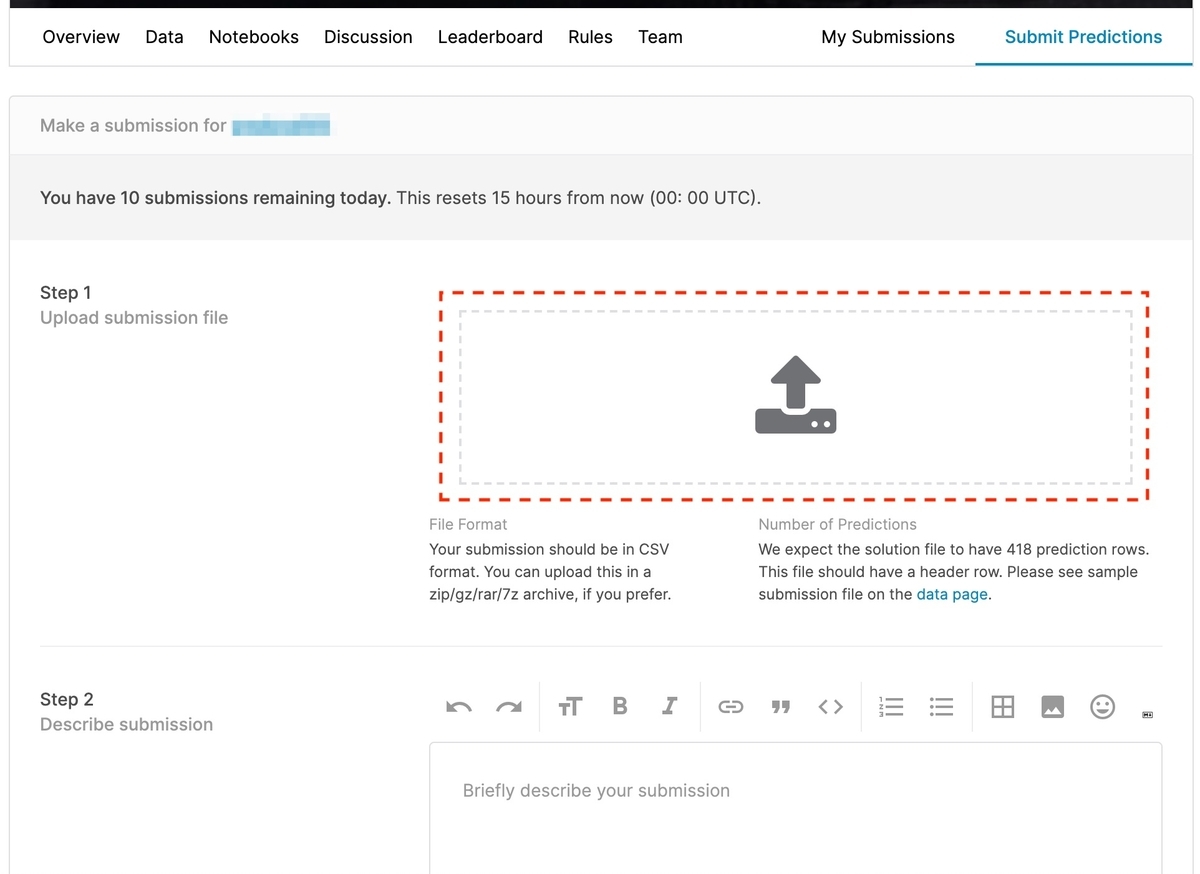
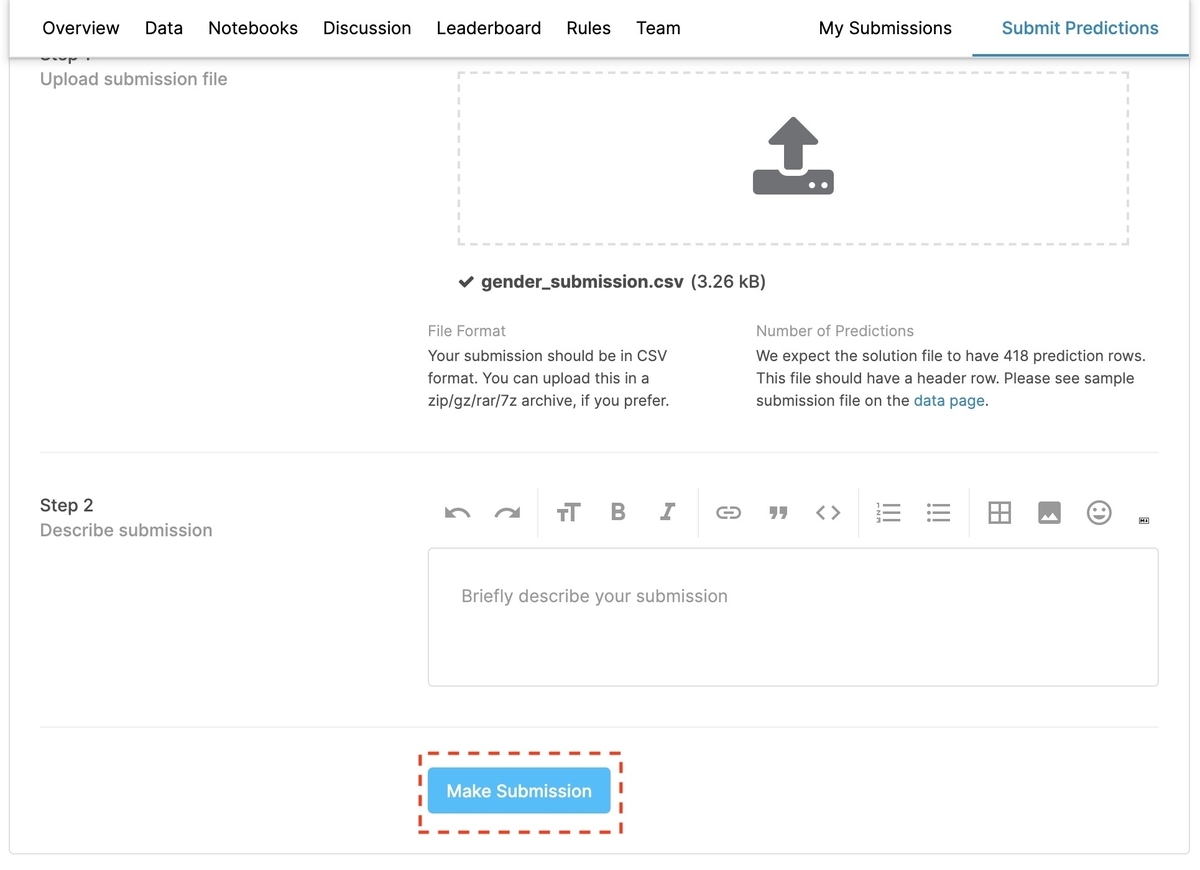
[2-3-3] 予測結果を提出
画面下部の[Make Submission]を押せば、予測結果の提出が完了します。

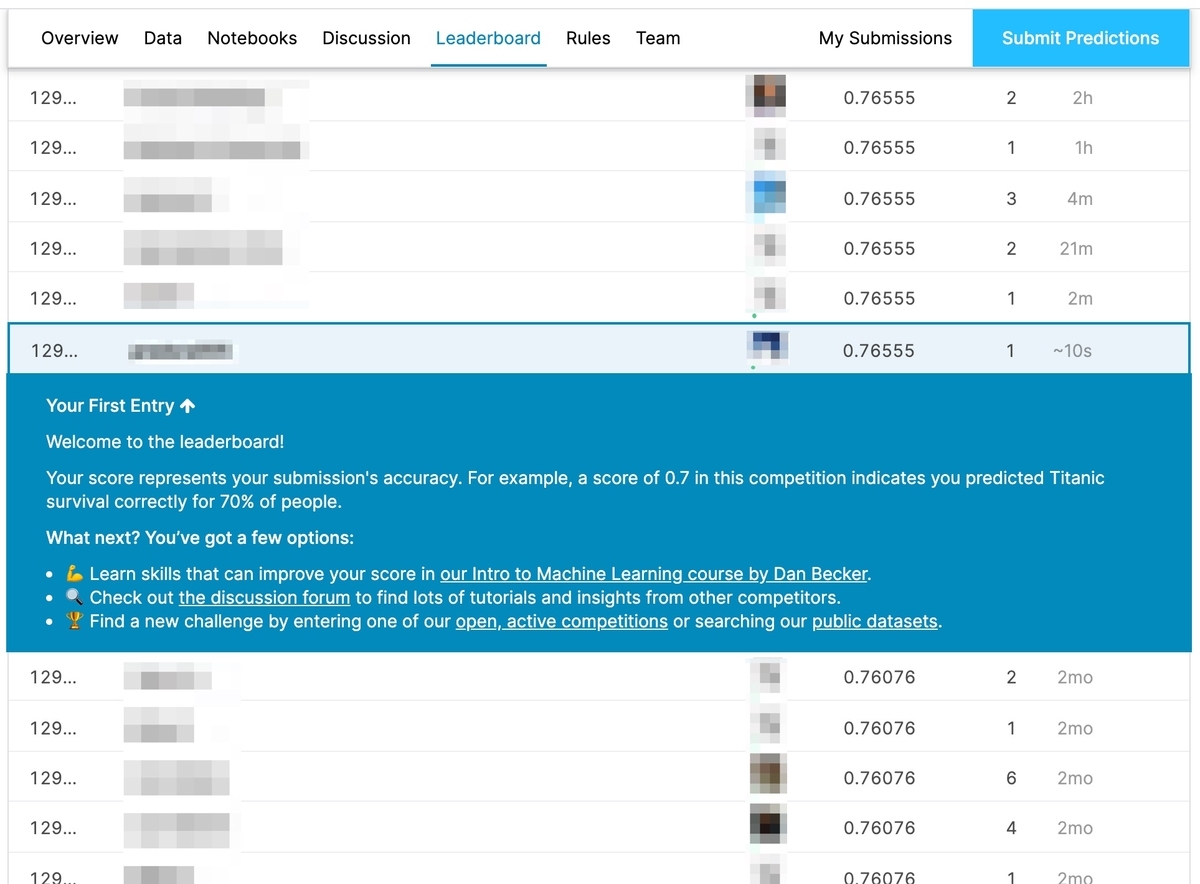
[2-4] 順位を確認する
先ほどの画面の[Jump to your position on the leaderboard]をクリックします。 すると、Leaderboardが表示され、自分の順位が確認できます。 私の結果は、16000チーム中12900位くらいでした。
終わりに
今回はコンペ参加から、予測結果(サンプルそのまま)を提出するところまでを御紹介しました。次回はチュートリアルを参考に、予測精度の向上に取り組みます。