Pythonで気象庁の過去気象データをスクレイピング

※ 2020/02/23にQrunchで書いた記事を移行しました。
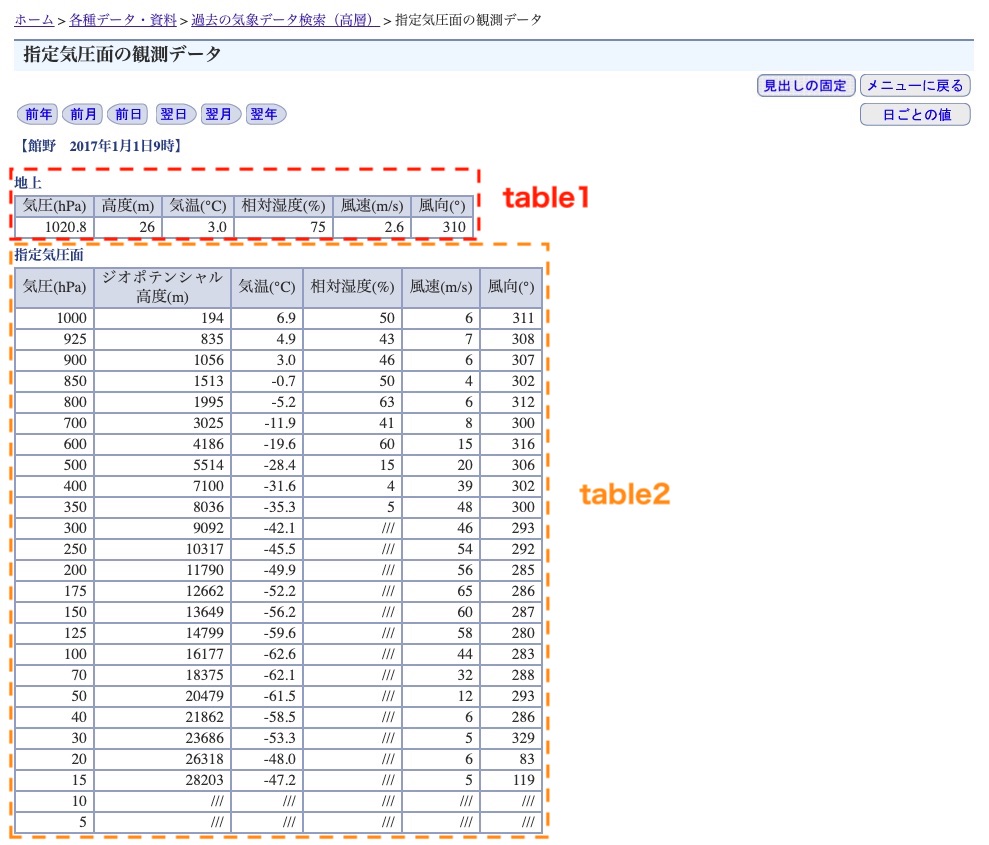
気象庁が公開している過去の気象データを取得するためにスクレイピングを使用しました。 今回、取得したのは高層の気象データです。過去の気象データ検索からアクセスできます。
下図の2つの表(table1, table2)から、気象観測データをスクレイピングします。
- [1] RequestsとBeautifulSoupをインストール
- [2] RequestsでHTML取得
- [3] BeautifulSoupでHTMLを解析
- [4] HTMLから抽出したデータをDataFrameに格納
- [5] DataFrameをCSVに出力
- [6] table2の抽出
- 終わりに
- 参考文献
[1] RequestsとBeautifulSoupをインストール
まずは、pipでRequestsとBeautifulSoupをインストールします。
pip3 install requests pip3 install bs4
[2] RequestsでHTML取得
requests.getを用いて、2017年1月1日の舘野の観測データを取得します。
URLを変更すれば、別の日付・時刻・地点のデータも取得可能です。
import requests # 指定URLのHTMLデータを取得 url = "https://www.data.jma.go.jp/obd/stats/etrn/upper/view/hourly_usp.php?year=2017&month=01&day=01&hour=9&atm=&point=47646&view=" html = requests.get(url) print(html.text) # <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> # <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja"> # ...
[3] BeautifulSoupでHTMLを解析
[3-1] 解析対象を確認する
まずは、解析対象のHTMLがどのような構造になっているのか、ブラウザで確認します。 ブラウザの開発用ツールで確認できます。Chromeであればデベロッパーツールです。 確認すると、tableタグを用いた基本的な表であることが分かりました。

[3-2] BeautifulSoupでHTMLを解析
BeautifulSoupを用いて、取得したHTMLを解析します。
from bs4 import BeautifulSoup # BeautifulSoupでHTMLを解析 soup = BeautifulSoup(html.content, "html.parser")
パーサーはPythonに標準でインストールされているHTMLパーサーを使用していますが、その他のパーサー(lxml parser等)もインストールすれば使用可能です。 詳細はBeautiful Soup Documentationを参照してください。
[3-3] table1の列タイトルを取得
HTML全体からtable1を検索します。
子要素を辿っていくこともできますが、面倒なのでfindで検索します。
検索ではタグ名の他にid, classといった属性を指定することも可能です。
# id='tablefix1'の<table>を抽出 table1 = soup.find('table', id='tablefix1') # table1内の全thを抽出 th_all = table1.find_all('th') print(th_all) # [<th scope="col">気圧(hPa)</th>, <th scope="col">高度(m)</th>, <th scope="col">気温(℃)</th>, <th scope="col">相対湿度(%)</th>, <th scope="col">風速(m/s)</th>, <th scope="col">風向(°)</th>] # 列タイトルをリストに格納する table1_column = [] for th in th_all: table1_column.append(th.string)
抽出した表の列タイトル(th)は、リストに格納しておきます。
[3-4] table1の行データを取得
列タイトルのときと同様に、各行(tr要素)内のtd要素から観測データを抽出します。 抽出したデータはndarrayに格納します。
# table1内の全trを抽出。 tr_all = table1.find_all('tr') # 先頭のtrは抽出済みなので飛ばす tr_all = tr_all[1:] # 行と列の個数を算出し、ndarrayを作成 number_of_cols = len(table1_column) number_of_rows = len(tr_all) table1_data = np.zeros((number_of_rows, number_of_cols)) # 各行のデータをndarrayに格納する for r, tr in enumerate(tr_all): td_all = tr.find_all('td') table1_data[r,:] = [td.string for td in td_all] print(tr) # [<td style="white-space:nowrap">1020.8</td>, <td class="data_0_0"> 26</td>, <td class="data_0_0">3.0</td>, <td class="data_0_0">75</td>, <td class="data_0_0">2.6</td>, <td class="data_0_0">310</td>]
[4] HTMLから抽出したデータをDataFrameに格納
抽出した列タイトルとデータを、pandasのDataFrameに格納します。
df = pd.DataFrame(data=table1_data, columns=table1_column) print(df) # 気圧(hPa) 高度(m) 気温(℃) 相対湿度(%) 風速(m/s) 風向(°) # 0 1020.8 26.0 3.0 75.0 2.6 310.0
[5] DataFrameをCSVに出力
DataFrameをCSVファイルに出力します。
# CSVファイルに出力する df.to_csv("./table1.csv")
[6] table2の抽出
table2についても、table1と同様に抽出します。 table1と違い数値に変換できないデータがあるので、各行のデータを格納する処理に若干の違いがあります。
# id='tablefix2'の<table>を抽出 table2 = soup.find('table', id='tablefix2') # table2内の全thを抽出 th_all2 = table2.find_all('th') # 列タイトルをリストに格納する table2_column = [] for th in th_all2: table2_column.append(th.string) # <table>内の全trを抽出。 tr_all2 = table2.find_all('tr') # 先頭のtrは抽出済みなので飛ばす tr_all2 = tr_all2[1:] # 行と列の個数を算出し、ndarrayを作成 number_of_cols2 = len(table2_column) number_of_rows2 = len(tr_all2) table2_data = np.zeros((number_of_rows2, number_of_cols2), dtype=np.float32) # 各行のデータをndarrayに格納する for r, tr in enumerate(tr_all2): td_all = tr.find_all('td') for c, td in enumerate(td_all): try: table2_data[r,c] = td.string except ValueError: table2_data[r,c] = np.nan # 抽出したデータのDataFrameを生成する df2 = pd.DataFrame(data=table2_data, columns=table2_column) print(df2) # 気圧(hPa) NaN 気温(℃) 相対湿度(%) 風速(m/s) 風向(°) # 0 1000.0 194.0 6.900000 50.0 6.0 311.0 # 1 925.0 835.0 4.900000 43.0 7.0 308.0 # ... # 10 300.0 9092.0 -42.099998 NaN 46.0 293.0 # ... # CSVファイルに出力する df2.to_csv("./table2.csv")
終わりに
思っていたよりも簡単にできました。 上記で試したのは、1日付・1地点の観測データのスクレイピングです。同じことを繰り返せば数年分・複数地点の観測データをスクレイピングすることも可能です。
一度使い方を覚えてしまえば、効率敵にデータ収集が行えるので覚える価値は十分にありました。 ただし、スクレイピングを禁止しているサイトもあるので、各サイトの規約を確認してから行うように気を付けてください。
参考文献
【最新】GoogleColaboratoryでもできる!気象庁の過去気象データをスクレイピングしてみた。 Pythonで文字列が数字か英字か英数字か判定・確認