日本株の株価をpythonでスクレイピングを使って取得しmatplotlibで可視化する(複数銘柄)
前回の続きです。前回は単一銘柄の株価をスクレイピングで取得しmatplotlibで可視化しました。今回は複数銘柄の株価を取得し比較していきます。

[1] 複数銘柄の株価取得
get_stock_price, astype_stock_price, add_moving_average_stock_priceは前回のソースコードを関数化したものです。各銘柄に対してスクレイピングを行い、取得した結果をDataFrameの末尾に結合していきます。
import time import pandas as pd codes = { 'JR東日本': 9020, 'JR西日本': 9021 } start_year, end_year = 2019, 2020 df = None for name in codes.keys(): # 指定した証券コードの決算情報を取得する。 code = codes[name] df_tmp = get_stock_price(code, start_year, end_year) # 株価情報のデータタイプを修正する df_tmp = astype_stock_price(df) # 株価情報に移動平均を追加する df = add_moving_average_stock_price(df) # 銘柄名を追加し、MultiIndexにする。 df_tmp['銘柄'] = name df_tmp = df_tmp.set_index('銘柄', append=True) # 2回目以降は既存のDataFrameの末尾にデータを追加 if df is None: df = df_tmp else: df = df_tmp.append(df) # 1秒ディレイ time.sleep(1) # indexを入れ替える df = df.swaplevel('銘柄', '日付').sort_index()
結果、次のデータが得られました。
| 始値 | 高値 | 安値 | 終値 | 出来高 | 終値調整 | 5日移動平均 | 25日移動平均 | 75日移動平均 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 銘柄 | 日付 | |||||||||
| JR東日本 | 2019-01-04 | 9675.0 | 9820.0 | 9627.0 | 9731.0 | 1337200.0 | 9731.0 | NaN | NaN | NaN |
| 2019-01-07 | 9918.0 | 10065.0 | 9915.0 | 10030.0 | 887500.0 | 10030.0 | NaN | NaN | NaN | |
| ... | ... | ... | ... | ... | ... | |||||
| JR西日本 | 2020-12-03 | 5085.0 | 5249.0 | 5077.0 | 5233.0 | 1869000.0 | 5233.0 | 4986.8 | 4907.92 | 5172.11 |
| 2020-12-04 | 5299.0 | 5414.0 | 5257.0 | 5317.0 | 1745900.0 | 5317.0 | 5038.2 | 4932.32 | 5173.95 |
[2] 可視化
[2-1] 2020年以降のデータを抽出
DataFrameをMultiIndexしたことにより、日付による抽出方法が少し変わっています。pd.IndexSliceを用いて抽出します。
# 2020/01/01以降のデータを抽出 df = df.loc[pd.IndexSlice[:, '2020-01-01':], :] # (前回) df = df['2020-01-01':]
下記記事を参考にさせてもらいました。
pandasのMultiIndexから任意の行・列を選択、抽出 | note.nkmk.me
[2-2] 株価の可視化
まずは、終値をそのまま折れ線グラフで可視化してみます。抽出したデータを折れ線グラフで可視化します。
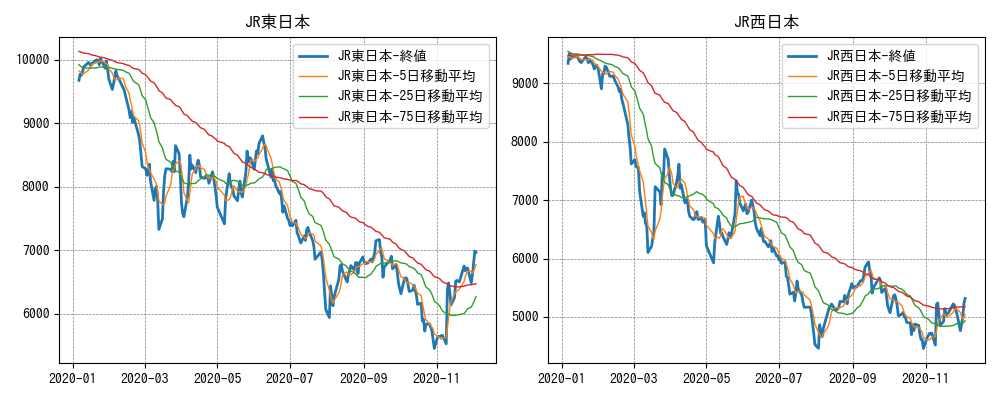
# Figureを取得 fig = plt.figure(figsize=(10, 4)) # 銘柄名のリスト取得 brand_names = list(df.index.unique('銘柄')) # 銘柄別に折れ線グラフで表示する for i, brand_name in enumerate(brand_names): # Axesを取得 ax = fig.add_subplot(1, 2, i+1) # 表示するデータを抽出 df_brand = df.loc[brand_name,] x = df_brand.index # 日付 y = df_brand['終値'] # 折れ線グラフ表示 label = '{0:s}-終値'.format(brand_name) ax.plot(x, y, label=label, linewidth=2.0) # 移動平均の折れ線グラフを追加 average_columns = ['5日移動平均', '25日移動平均', '75日移動平均'] for column in average_columns: x = df_brand.index # 日付 y = df_brand[column] # 移動平均 label = '{0:s}-{1:s}'.format(brand_name, column) ax.plot(x, y, label=label, linewidth=1.0) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # グラフのタイトルを追加 ax.set_title(brand_name) # 不要な余白を削る plt.tight_layout() # グラフを表示 fig.show()
[2-3] 値上がり率の可視化
株価は発行済株数によって変わるので単純比較はできません。そこで、ある日付を基準とした値上がり率で比較してみます。
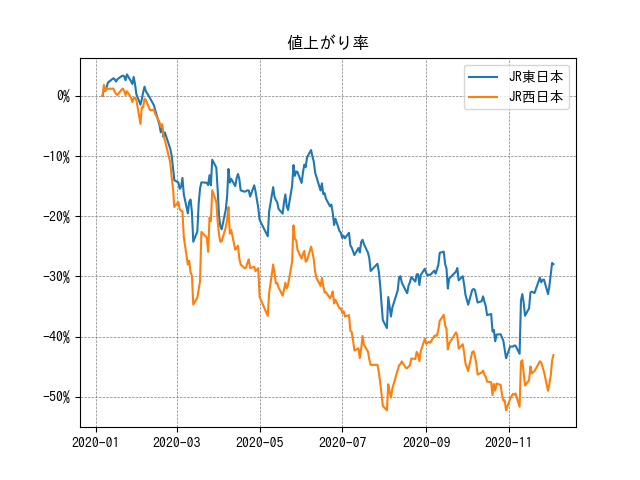
2020/01/06を基準とした比率で言うと、JR西日本の方が株価が大きく下落しています。
# 基準日を設定 ref_date = datetime.date(2020, 1, 6) ref_date_str = ref_date.strftime('%04Y-%02m-%02d') # FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(1,1,1) # 銘柄別に値上がり率を計算 for brand_name in brand_names: # 指定銘柄のデータを取得 df_brand = df.loc[brand_name,] # 値上がり率を計算 base_price = df_brand.loc[ref_date_str,'終値'] # 基準日の終値 rate = df_brand['終値'] / base_price - 1 # 値上がり率 # 表示するデータを抽出 x = df_brand.index # 日付 y = rate # 折れ線グラフを表示 ax.plot(x, y, label=brand_name) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # Y軸の単位をパーセント表示に設定 ax.yaxis.set_major_formatter(mpl.ticker.PercentFormatter(1)) # グラフのタイトルを追加 ax.set_title('値上がり率') # グラフを表示 fig.show()
期間をもう少し長く取ると、JR西日本は2019年〜2020年にわたって株価が大きく上昇していました。そのため、2020年の下落幅も大きかったことがわかります。

[2-4] 株式分割に注意
株式分割等で株価が急激に変わった場合は補正が必要です。例えば、株価¥10,000だった銘柄が株式分割で1株を10株に分割すると、株価は¥1,000になります。
株価は10分の1になりますが、1株あたりの価値は変わりません。この場合、株式分割後の株価を10倍にする補正が必要でしょう。
[2-5] 補足: DataFrameに値上がり率を追加
ちなみに、元のDataFrameに値上がり率を追加するためには以下のようにします。
# 値上がり率の列を用意 df['値上がり率'] = np.nan for brand_name in brand_names: ...(中略)... # 値上がり率をDataFrameに追加 # (rateはSeries. そのまま代入するとindexが合わないためNG) df.loc[(brand_name, ), '値上がり率'] = rate.values
終わりに
株価をスクレイピングで取得し、複数銘柄間の比較を行ました。上記では'JR東日本'と'JR西日本'の2銘柄のみ扱いましたが、銘柄数を増やすことは用意です。いちど仕組みを作ってしまえば応用することは難しくありません。

そもそもスクレイピングを始めた目的は、株式投資のために企業分析を行うことでした。より詳しい分析を行うためには各企業の決算情報なども見ないと足りないなと感じました。
ただ、今回行ったことは分析の取っ掛かりとしては悪くありませんでした。その業界全体の傾向を見る場合や、その業界のなかで他と値動きが異なる企業を探す場合に活用できそうです。
[補足]
[補足1] get_stock_pricesのソースコード
def get_stock_price(code, start_year, end_year): whole_df = None headers = None # 指定した年数分の株価を取得する years = range(start_year, end_year+1) for year in years: # 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html_headers ={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} html = requests.get(url, headers=html_headers) # BeautifulSoupのHTMLパーサーを生成 bs = BeautifulSoup(html.content, "html.parser") # <table>要素を取得 table = bs.find('table') # <table>要素内のヘッダ情報を取得する。 if headers is None: headers = [] thead_th = table.find('thead').find_all('th') for th in thead_th: headers.append(th.text) # <tr>要素のデータを取得する。 rows = [] tr_all = table.find_all('tr') for i, tr in enumerate(tr_all): # 最初の行は<thead>要素なので飛ばす if i==0: continue # <tr>要素内の<td>要素を取得する。 row = [] td_all = tr.find_all('td') for td in td_all: row.append(td.text) # 1行のデータをリストに追加 rows.append(row) # DataFrameを生成する df = pd.DataFrame(rows, columns=headers) # DataFrameを結合する if whole_df is None: whole_df = df else: whole_df = pd.concat([whole_df, df]) # 1秒ディレイ time.sleep(1) return whole_df
[補足2] astype_stock_priceのソースコード
def astype_stock_price(df): # 列とデータ型の組み合わせを設定 dtypes = {} for column in df.columns: if column == '日付': dtypes[column] = 'datetime64' else: dtypes[column] ='float64' # データ型を変換 new_df = df.astype(dtypes) # インデックスを日付に変更 new_df = new_df.set_index('日付') return new_df
[補足3] add_moving_average_stock_priceのソースコード
def add_moving_average_stock_price(df): df['5日移動平均'] = df['終値'].rolling(window=5).mean() df['25日移動平均'] = df['終値'].rolling(window=25).mean() df['75日移動平均'] = df['終値'].rolling(window=75).mean() return df
出典
- アイキャッチはGerd AltmannによるPixabayからの画像