Pythonでセルが結合されたテーブルをスクレイピングする方法
<pandasのDataFrameをconcatすると型が変わってしまう場合の対処法>*1
※ 2020/03/26にQrunchで書いた記事を移行しました。
BeautifulSoupを使うと、Pythonでスクレイピングを簡単に行うことができます。しかし、セルが結合されたテーブルのスクレイピングは少々面倒です。
以下の画像は、過去の気象データなのですが、テーブルの見出しでセル結合が多用されています。このようにセルが結合されたテーブルのスクレイピング方法についてまとめました。
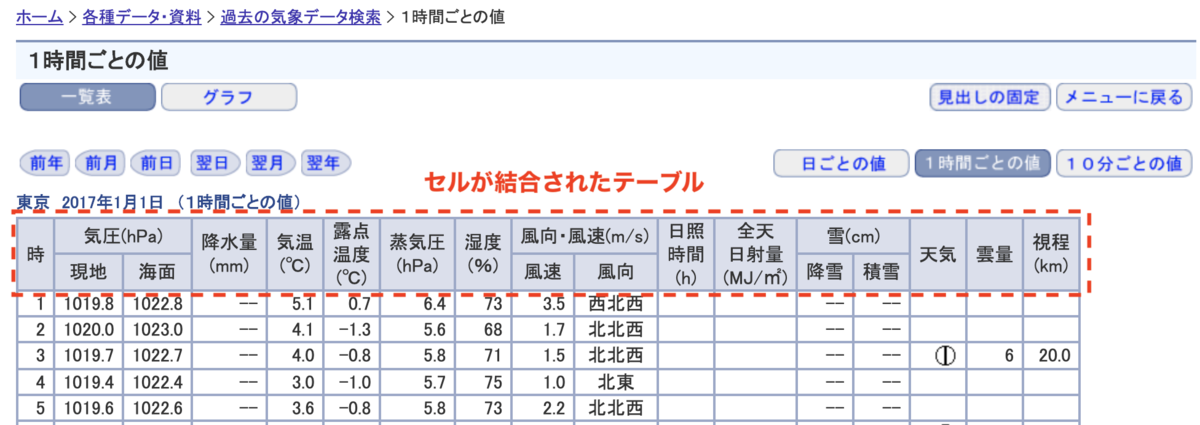
[1] やりたいこと
上記のようにセルが結合されたテーブルを以下のような構造に変換します。
| - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 時 | 気圧(hPa) | 気圧(hPa) | 降水量(mm) | 気温(℃) | 露点温度(℃) | 蒸気圧(hPa) | 湿度(%) | 風向・風速(m/s) | 風向・風速(m/s) | 日照時間(h) | 全天日射量(MJ/㎡) | 雪(cm) | 雪(cm) | 天気 | 雲量 | 視程(km) |
| 時 | 現地 | 海面 | 降水量(mm) | 気温(℃) | 露点温度(℃) | 蒸気圧(hPa) | 湿度(%) | 風速 | 風向 | 日照時間(h) | 全天日射量(MJ/㎡) | 降雪 | 積雪 | 天気 | 雲量 | 視程(km) |
[2] HTMLの中身
htmlの中身は次のようになっています。セルが結合されている箇所は、
「rowspan」と「colspan」を値に応じて、スクレイピング方法を工夫していきます。
<tr class="mtx"> <th rowspan="2" scope="col">時</th> <th colspan="2" scope="colgroup">気圧(hPa)</th> <th rowspan="2" scope="col">降水量<br />(mm)</th> <th rowspan="2" scope="col">気温<br />(℃)</th> <th rowspan="2" scope="col">露点<br />温度<br />(℃)</th> <th rowspan="2" scope="col">蒸気圧<br />(hPa)</th> <th rowspan="2" scope="col">湿度<br />(%)</th> <th colspan="2" scope="colgroup">風向・風速(m/s)</th> <th rowspan="2" scope="col">日照<br />時間<br />(h)</th> <th rowspan="2" scope="col">全天<br />日射量<br />(MJ/㎡)</th> <th colspan="2" scope="colgroup">雪(cm)</th> <th rowspan="2" scope="col">天気</th> <th rowspan="2" scope="col">雲量</th> <th rowspan="2" scope="col">視程<br />(km)</th> </tr> <tr class="mtx"> <th scope="col">現地</th> <th scope="col">海面</th> <th scope="col">風速</th> <th scope="col">風向</th> <th scope="col">降雪</th> <th scope="col">積雪</th> </tr>
[3] スクレイピング方法
下記ブログの内容を参考にさせていただきました。
BeautifulSoup を使ったコード片のメモ - 銀月の符号
[3-1] テーブルの列数を数える
テーブルの列数を数えます。列数は行によって'まちまち'ですが、全行の列数のうち最大値を採用します。
# テーブル見出しの列数をカウントする header_col_num = 0 for tr in tr_all: # <th>を持つ行(<tr>)があれば列数をカウントする th_all = tr.find_all('th') if th_all: col_num = 0 for th in th_all: col_num += int(th.get('colspan', 1)) # 列数の最大値を更新する header_col_num = max(header_col_num, col_num)
[3-2] リストを準備する
各セルの中身を格納するためのリストを準備します。加えて、リストを2つ用意します。
# テーブル見出し用のリストを用意する table_column = [] # num_reapeat[列数]: rowspanが2以上のとき行方向に繰り返しセットする回数 # col_th[列数]: rowspanが2以上のとき行方向に繰り返しセットする<th>要素 num_repeat = [ 0 for col in range(header_col_num) ] col_th = [ None for col in range(header_col_num) ]
例えば、"時"はrowspan=2で、行方向に2回連続して"時"をセットします。
num_repeat[0]に「1列目は縦方向に2回連続すること」を記憶し、
col_th[0]に「1列目に設定するデータ(
| - | - | - |
|---|---|---|
| 時 | 気圧(hPa) | 気圧(hPa) |
| 時 | 現地 | 海面 |
[3-3] リストに格納する
リストに格納するソースコードは次の通りです。
# テーブル見出しをリストに格納する for tr in tr_all: # <th>要素を持つ行に対して処理を行う th_all = tr.find_all('th') if th_all: # 全<th>要素をpop()で取出し続ける cols = [] col = 0 while col < header_col_num: # 前の行でrowspanがある場合は、前回記憶した<th>要素を取り出す if num_repeat[col] > 0: th = col_th[col] num_repeat[col] -= 1 else: th = th_all.pop(0) rowspan = int(th.get('rowspan', 1)) if rowspan > 1: # rowspanが2以上のとき、 # 次の行以降の繰り返し回数と、<th>要素を記録する num_repeat[col] = rowspan - 1 col_th[col] = th # colspan回数分、<th>の中身をリストに追加する colspan = int(th.get('colspan', 1)) for c in range(colspan): cols.append(th.get_text(strip=True)) col += 1 # 当該行の列要素をリストに追加する table_column.append(cols)
列数が上限に最大値に達するまで、その行の要素をpop()で取り出します。"気圧(hPa)"のようにcolspanが2以上の場合は、colspan回数分連続してリストに格納します。
[3-4] DataFrameに格納しCSVを出力する
df = pd.DataFrame(data=table_data, columns=table_column)
df.write_to_csv('test.csv')
終わりに
少々面倒ですが、一度分かってしまえば使い回しがきくので、部品化しておくのがよいでしょう。
ロジックは参考にさせていただいた記事そのままです。参考にさせていただき、ありがとうございました。
*1:Coffee BeanによるPixabayからの画像