【機械学習】AutoGluonの使い方・クイックスタートの解説(物体検出)
AutoGluonの「物体検出」のクイックスタートについて紹介・解説します。YOLOv3モデルを使って画像からバイクを検出するという内容です。
Object Detection - Quick Start — AutoGluon Documentation 0.2.0 documentation
表形式データや画像認識については別記事で紹介しています。
https://predora005.hatenablog.com/entry/2021/06/20/190000predora005.hatenablog.com
[1] データセットのダウンロード
データセットは、 VOCデータセットの中から、学習用に120枚、検証用に50枚、テスト用に50枚が抽出されたものになっています。
$ curl -OL 'https://autogluon.s3.amazonaws.com/datasets/tiny_motorbike.zip' $ unzip tiny_motorbike.zip
[2] 学習の実行
データセットを読み込んだのち、学習を実行します。
import autogluon.core as ag from autogluon.vision import ObjectDetector url = './tiny_motorbike/' dataset_train = ObjectDetector.Dataset.from_voc(url, splits='trainval')
num_traialsで学習回数を2回に指定しています。クイックスタートの説明によれば、time_limitでコントールするのが望ましいようです。
time_limit = 60*30 # at most 0.5 hour detector = ObjectDetector() hyperparameters = {'epochs': 5, 'batch_size': 8} hyperparamter_tune_kwargs={'num_trials': 2} detector.fit(dataset_train, time_limit=time_limit, hyperparameters=hyperparameters, hyperparamter_tune_kwargs=hyperparamter_tune_kwargs)
終了するまでに、r5.largeインスタンスでは10分、m5.xlargeインスタンスでは 5分ほどかかりました。
[3] 評価・予測の実行
evaluateでテストデータを用いた評価を行います。
dataset_test = ObjectDetector.Dataset.from_voc(url, splits='test') test_map = detector.evaluate(dataset_test) print(test_map) # (['motorbike', 'chair', 'bus', 'car', 'dog', # 'bicycle', 'cow', 'person', 'boat', 'pottedplant', 'mAP'], # [0.5806065427876039, nan, 0.47272727272727283, 0.007751937984496126, # 0.0, nan, nan, nan, nan, nan, 0.26527143837484324])
mAP (Mean Average Precision)を表示すると、約26%でした。
print("mAP on test dataset: {}".format(test_map[1][-1])) # mAP on test dataset: 0.26527143837484324
以下では、テストデータから1枚画像を取り出し、予測を実行しています。
image_path = dataset_test.iloc[0]['image'] result = detector.predict(image_path) print(result) # predict_class predict_score \ # 0 person 0.972545 # 1 motorbike 0.656974 # 2 bicycle 0.413718 # .. ... ... # 85 person 0.035410 # 86 person 0.034698 # 87 bicycle 0.034663 # # predict_rois # 0 {'xmin': 0.3991624116897583, 'ymin': 0.2802912... # 1 {'xmin': 0.3347971439361572, 'ymin': 0.4365810... # 2 {'xmin': 0.3935226500034332, 'ymin': 0.4864529... # .. ... # 85 {'xmin': 0.38480135798454285, 'ymin': 0.438172... # 86 {'xmin': 0.8661710619926453, 'ymin': 0.4210591... # 87 {'xmin': 0.46432197093963623, 'ymin': 0.484336... # # [88 rows x 3 columns]
検出したオブジェクトのクラス(predict_class)、スコア(predict_score)、バウンディングボックスの位置(predict_rois)が返されます。スコアの良いもののみ可視化すると以下の通りです(ソースコードは補足3に記載しています)。

また、複数枚の画像をまとめて予測することも可能です。
bulk_result = detector.predict(dataset_test) print(bulk_result) # predict_class predict_score \ # 0 person 0.972545 # 1 motorbike 0.656974 # 2 bicycle 0.413718 # ... ... ... # 4594 person 0.034718 # 4595 person 0.034599 # 4596 person 0.034501 # # predict_rois \ # 0 {'xmin': 0.3991624116897583, 'ymin': 0.2802912... # 1 {'xmin': 0.3347971439361572, 'ymin': 0.4365810... # 2 {'xmin': 0.3935226500034332, 'ymin': 0.4864529... # ... ... # 4594 {'xmin': 0.37993040680885315, 'ymin': 0.462566... # 4595 {'xmin': 0.9430548548698425, 'ymin': 0.1451357... # 4596 {'xmin': 0.4937310814857483, 'ymin': 0.2520754... # # image # 0 /home/jupyter/tiny_motorbike/JPEGImages/000038... # 1 /home/jupyter/tiny_motorbike/JPEGImages/000038... # 2 /home/jupyter/tiny_motorbike/JPEGImages/000038... # ... ... # 4594 /home/jupyter/tiny_motorbike/JPEGImages/002488... # 4595 /home/jupyter/tiny_motorbike/JPEGImages/002488... # 4596 /home/jupyter/tiny_motorbike/JPEGImages/002488... # # [4597 rows x 4 columns]
[4] 分類器のセーブ・ロード
分類器のセーブ・ロードも可能です。savefileで指定したファイル名の通りに保存されます。
savefile = 'detector.ag'
detector.save(savefile)
new_detector = ObjectDetector.load(savefile)
終わりに
学習時間は比較的短めでしたが、それなりの精度は出ているようです。何よりもソースコード数行で物体検出が行えるというのが驚きでした。手軽に物体検出できるのはありがたいです。
出典
- アイキャッチはGerd AltmannによるPixabayからの画像
補足
[補足1] ImportError: libGL.so.1
AutoGluon使用時に以下のエラーが発生することがある。根本はOpenCVがインポートできないことが原因。
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
環境によって解決策が異なるようですが、Amazon Linux2では以下のコマンドで解決しました。
$ sudo yum install -y mesa-libGL.x86_64
[補足2] AutoGluonでデータセットの取得と解凍まで行う
データセットの取得と解凍をプログラムで行うことも可能です。
import autogluon.core as ag from autogluon.vision import ObjectDetection as task import os root = './' filename_zip = ag.download('https://autogluon.s3.amazonaws.com/datasets/tiny_motorbike.zip', path=root) filename = ag.unzip(filename_zip, root=root)
data_root = os.path.join(root, filename)
dataset_train = task.Dataset(data_root, classes=('motorbike',))
[補足3] 画像にバインディングボックスとスコアを表示
データセットから画像のパスを取り出し予測させます。次に、予測結果から良いスコアのもののみを取り出しています。ここでは0.7以上を対象としています。
image0_path = dataset_test.iloc[0]['image'] result = detector.predict(image0_path).query('predict_score >= 0.7')
可視化する際に画像をndarrayで渡す必要があります。Pillowで画像を読み込みnp.arrayでndarrayに変換します。
import numpy as np from PIL import Image im0 = Image.open(image0_path) width, height = im0.size image0 = np.array(im0)
バウンディングボックスは、Nx4のndarrayで渡します。ディクショナリから取り出した座標を画面座標に変換します。
bboxes=[] for rois in result['predict_rois']: x1, y1 = int(rois['xmin']* width), int(rois['ymin']* height) x2, y2 = int(rois['xmax']* width), int(rois['ymax']* height) bboxes.append([x1, y1, x2, y2]) bboxes = np.array(bboxes)
準備したパラメータを渡せば以下のような画像が作れます。
from gluoncv.utils import viz scores = result['predict_score'].values labels , class_names = result['predict_class'].factorize() ax = viz.plot_bbox(image0, bboxes=bboxes, scores=scores, labels = labels, class_names=class_names) plt.show()
08. Finetune a pretrained detection model — gluoncv 0.11.0 documentation
【機械学習】AutoGluonの使い方・クイックスタートの解説(画像認識)
AutoGluonの「画像認識」のクイックスタートについて紹介・解説します。
各画像に描かれた衣類のカテゴリーを分類するという内容です。カテゴリはBabyPants, BabyShirt, womencasualshoes, womenchiffontopの4種類です。
Image Prediction - Quick Start — AutoGluon Documentation 0.2.0 documentation
表形式データについては別記事で紹介しています。
[1] データセットのダウンロード
$ curl -OL 'https://autogluon.s3.amazonaws.com/datasets/shopee-iet.zip' $ unzip shopee-iet.zip
[2] 学習データの確認
学習用データは800枚の画像です。
import autogluon.core as ag from autogluon.vision import ImagePredictor train_dataset, _, test_dataset = ImagePredictor.Dataset.from_folders('./data') print(train_dataset) # image label # 0 /home/jupyter/data/train/BabyPants/BabyPants_1... 0 # 1 /home/jupyter/data/train/BabyPants/BabyPants_1... 0 # 2 /home/jupyter/data/train/BabyPants/BabyPants_1... 0 # 3 /home/jupyter/data/train/BabyPants/BabyPants_1... 0 # 4 /home/jupyter/data/train/BabyPants/BabyPants_1... 0 # .. ... ... # 795 /home/jupyter/data/train/womenchiffontop/women... 3 # 796 /home/jupyter/data/train/womenchiffontop/women... 3 # 797 /home/jupyter/data/train/womenchiffontop/women... 3 # 798 /home/jupyter/data/train/womenchiffontop/women... 3 # 799 /home/jupyter/data/train/womenchiffontop/women... 3 # # [800 rows x 2 columns]
[3] 学習の実行
学習を実行すると、ハイパーパラメータと最適なモデルの選定が自動でおこなれます。 ソース中のコメントにもある通り、学習用データのうち1割が検証用データとして使われます。また、ここでは学習回数(epochs)を2回に制限していますが、制限しない方が良いです。
predictor = ImagePredictor() # since the original dataset does not provide validation split, the `fit` function splits it randomly with 90/10 ratio predictor.fit(train_dataset, hyperparameters={'epochs': 2}) # you can trust the default config, we reduce the # epoch to save some build time
学習と検証の予測精度は以下のコードで確認できます。
fit_result = predictor.fit_summary() print('Top-1 train acc: %.3f, val acc: %.3f' %(fit_result['train_acc'], fit_result['valid_acc'])) # Top-1 train acc: 0.623, val acc: 0.806
[4] 評価の実行
テストデータで評価を行います。
test_acc, _ = predictor.evaluate(test_dataset) print('Top-1 test acc: %.3f' % test_acc) # Top-1 test acc: 0.713
[5] 新たな画像のカテゴリを予測
以下は1枚の画像を入力し、どのカテゴリかを確認しています。
image_path = test_dataset.iloc[0]['image'] result = predictor.predict(image_path) print(result) # 0 0 # Name: label, dtype: int64
predict_probaで、各カテゴリの予測結果を確認できます。
proba = predictor.predict_proba(image_path) print(proba) # 0 1 2 3 # 0 0.498938 0.486701 0.012103 0.002259
複数の画像を入力とし、予測を行うことも可能です。
bulk_result = predictor.predict(test_dataset) print(bulk_result) # 0 0 # 1 0 # 2 2 # 3 2 # 4 1 # .. # 75 3 # 76 3 # 77 3 # 78 3 # 79 2 # Name: label, Length: 80, dtype: int64
[6] 分類器のセーブ・ロード
以下のように分類器のセーブ・ロードが可能です。
filename = 'predictor.ag' predictor.save(filename) predictor_loaded = ImagePredictor.load(filename) # use predictor_loaded as usual result = predictor_loaded.predict(image_path) print(result) # 0 0 # Name: label, dtype: int64
終わりに
精度がどの程度なのかは分かりませんが、ソースコードはかなり簡単に書くことが出来ました。
出典
- アイキャッチはGerd AltmannによるPixabayからの画像
【機械学習】AutoGluonの使い方・クイックスタートの解説(表形式データ)
「AutoGluon」の使い方を、公式のクイックスタートを解説する形で紹介します。
AutoGluonは、AutoML(Auto Machine Learning)を実現するライブラリです。特徴量の設計など機械学習で大変な部分を自動化してくれます。
AutoGluonは数あるAutoMLライブラリの一種で、テキスト、画像、表データに対応しています。
本記事では、AutoGluonのインストール方法、表形式データのクイックスタートを紹介します。
[1] インストール方法
以下は、LinuxかつGPU無しのインストール手順です。GPU有りや別OSの手順も公式に載っています。
python3 -m pip install -U pip --user python3 -m pip install -U setuptools wheel --user python3 -m pip install -U "mxnet<2.0.0" --user python3 -m pip install autogluon --user
AutoGluon: AutoML for Text, Image, and Tabular Data — AutoGluon Documentation 0.2.0 documentation
[2] クイックスタート
公式では下記4種類のクイックスタートが載っています。
- 表形式データ
- 画像分類
- 物体検出
- テキスト分類
本記事では、表形式データの内容を紹介します。
[2-1] 概要
ある人の収入が5万ドルを超えるかどうかを予測する分類モデルを作成するという内容です。
Predicting Columns in a Table - Quick Start — AutoGluon Documentation 0.2.0 documentation
[2-2] 学習データの確認
from autogluon.tabular import TabularDataset, TabularPredictor train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv') subsample_size = 500 # subsample subset of data for faster demo, try setting this to much larger values train_data = train_data.sample(n=subsample_size, random_state=0) train_data.head()

500人中、年収5万ドル以下の人が365人、残りの135人が5万ドル以上になります。
label = 'class' print("Summary of class variable: \n", train_data[label].describe()) # Summary of class variable: # count 500 # unique 2 # top <=50K # freq 365 # Name: class, dtype: object
[2-3] 学習の実行
TabularPredictor.fit()で学習を実行します。
save_path = 'agModels-predictClass' # specifies folder to store trained models predictor = TabularPredictor(label=label, path=save_path).fit(train_data) # Summary of class variable: # count 500 # unique 2 # top <=50K # freq 365 # Name: class, dtype: object
[2-4] 予測と評価
predictでテストデータを用いた予測を行い、evaluate_predictionsで評価を行います。
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv') y_test = test_data[label] # values to predict test_data_nolab = test_data.drop(columns=[label]) # delete label column to prove we're not cheating test_data_nolab.head()

predictor = TabularPredictor.load(save_path) # unnecessary, just demonstrates how to load previously-trained predictor from file y_pred = predictor.predict(test_data_nolab) print("Predictions: \n", y_pred) # Predictions: # 0 <=50K # 1 <=50K # 2 >50K # 3 <=50K # 4 <=50K # ... # 9764 <=50K # 9765 <=50K # 9766 <=50K # 9767 <=50K # 9768 <=50K # Name: class, Length: 9769, dtype: object
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True) # Evaluation: accuracy on test data: 0.8397993653393387 # Evaluations on test data: # { # "accuracy": 0.8397993653393387, # "balanced_accuracy": 0.7437076677780596, # "mcc": 0.5295565206264157, # "f1": 0.6242496998799519, # "precision": 0.7038440714672441, # "recall": 0.5608283002588438 # }
また、leaderboardで訓練を行った各モデルの性能を確認することができます。
predictor.leaderboard(test_data, silent=True)

[2-5] 学習(fit)の中で行われていること
クイックスタートの説明を要約すると次の通りです。
- 二値分類問題であることは自動で認識する。
- どの特徴量が連続値か離散値を自動的に判別する。
- 欠損データや特徴量の再スケーリングなども自動的に処理する。
- 検証用データを使って、複数のモデルを訓練する。
- ハイパーパラメータの選定も自動で行われる。
- 検証用データを指定しない場合は、学習用データからランダムに検証用データを抽出する。
[2-6] 予測精度の最大化
fit()のパラメータを変えることで予測精度の向上を図ることが可能です。
time_limit = 60 # for quick demonstration only, you should set this to longest time you are willing to wait (in seconds) metric = 'roc_auc' # specify your evaluation metric here predictor = TabularPredictor(label, eval_metric=metric).fit(train_data, time_limit=time_limit, presets='best_quality') predictor.leaderboard(test_data, silent=True)
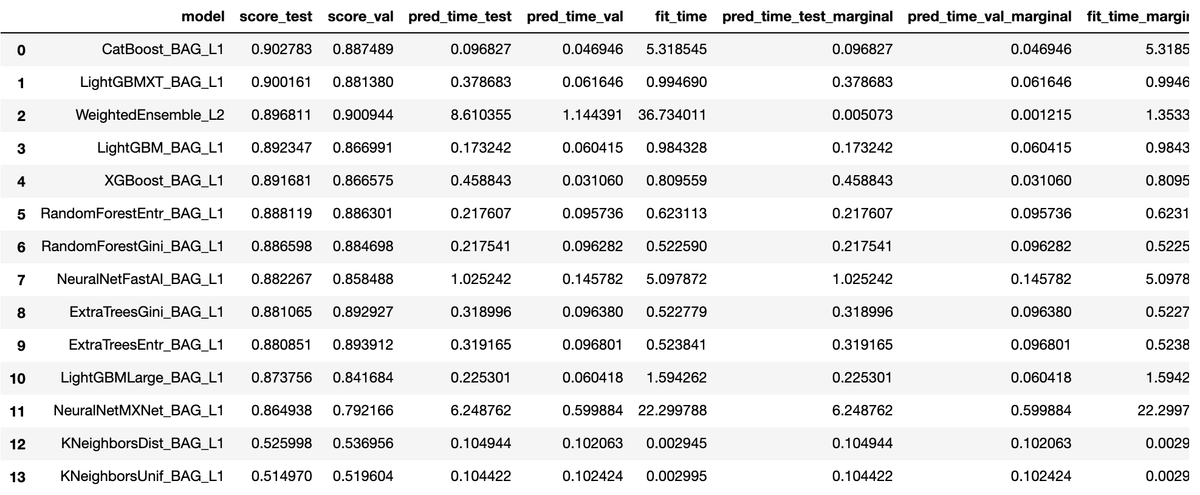
上記例では、次のことを行っています。
time_limitで学習時間を60秒まで可能にする。metricは評価指標が事前に分かっている場合に指定する。指定できるのはroc_auc,log_loss,mean_absolute_errorなど。presetsで精度や速度などの優先順位を指定する。best_qualityは精度優先、デフォルトは'medium_quality_faster_train。
[2-7] 回帰の例
ラベルを年齢('age')にすることで、回帰を行うことも可能です。
age_column = 'age' print("Summary of age variable: \n", train_data[age_column].describe()) # Summary of age variable: # count 500.00000 # mean 39.65200 # std 13.52393 # min 17.00000 # 25% 29.00000 # 50% 38.00000 # 75% 49.00000 # max 85.00000 # Name: age, dtype: float64 predictor_age = TabularPredictor(label=age_column, path="agModels-predictAge").fit(train_data, time_limit=60) performance = predictor_age.evaluate(test_data) predictor_age.leaderboard(test_data, silent=True)
終わりに
あまり細かいことを意識することなく使用することが出来ました。面倒な前処理を自動でやってくれるのは大きいメリットです。
機械学習の精度を向上させるためには、特徴量の作成や選択、モデルのチューニングなど様々なテクニックが必要です。AutoGluonのみでは通用しない場面も出てくるでしょうが、手間が圧倒的に少ないため、AutoGluonを初手で使ってみる価値はあるでしょう。
参考文献
- AutoMLとは?自動化された機械学習の可能性と代表的なツール
- https://pages.awscloud.com/rs/112-TZM-766/images/1.AWS_AutoML_AutoGluon.pdf
出典
- アイキャッチはGerd AltmannによるPixabayからの画像
補足
[補足1]
Jupyter Notebookで以下の警告が出ることがあります。
DeprecationWarning:
should_run_asyncwill not calltransform_cellautomatically in the future. Please pass the result totransformed_cellargument and any exception that happen during thetransform inpreprocessing_exc_tuplein IPython 7.17 and above.
非推奨の警告なので動作には影響ないようです。表示しないようにするには、下記URLにある解決策が現状有力なようでした。私の環境でも下記内容で解決しました。
$ python3 -m pip install --upgrade ipykernel $ python3 -m pip install install ipython==7.10.0 --user
ipythonをダウングレードすれば解決します。それがイヤな場合はソースで警告の無視を設定して解決できます。
import warnings warnings.filterwarnings("ignore", category=DeprecationWarning)
【読書】「20歳の自分に受けさせたい文章講義」の感想
頭のなかの「ぐるぐる」を、伝わる言葉に〝翻訳〟したものが文章なのである。
出典:古賀史健. 20歳の自分に受けさせたい文章講義 (Japanese Edition) (Kindle の位置No.215-216). Kindle 版.
自分の気持ちをうまく文章にできない、話せるのに書けない。よくありがちなことですよね、私も社会人になってしばらく経つまではそうでした。
話し言葉をそのまま文章にすればよいと言われたりもしています。しかし実際にやってみると、前後の文章がつながらなくて支離滅裂になったりします。 なぜかと言えば、そもそも「話すこと」と「書くこと」はまったく別の行為だからです。
うまく文章にできないのは、どういう状態なのか。頭の中を様々な思いが駆け巡っていて、その時点では言葉ではない、言葉以前の茫漠たる感覚。この頭を駆け巡る想いや感覚を「20歳の自分に受けさせたい文章講義」の著者である古賀さんは「頭の中のぐるぐる」と呼んでいます。
以上は「20歳の自分に受けさせたい文章講義」の冒頭部分の内容です。
https://www.amazon.co.jp/20%E6%AD%B3%E3%81%AE%E8%87%AA%E5%88%86%E3%81%AB%E5%8F%97%E3%81%91%E3%81%95%E3%81%9B%E3%81%9F%E3%81%84%E6%96%87%E7%AB%A0%E8%AC%9B%E7%BE%A9-%E6%98%9F%E6%B5%B7%E7%A4%BE-SHINSHO-%E5%8F%A4%E8%B3%80%E5%8F%B2%E5%81%A5-ebook/dp/B08FR69RWM/ref=tmm_kin_swatch_0?_encoding=UTF8&qid=&sr=www.amazon.co.jp
私は職業がSEということもあり、文章を書く機会がそれなりにあります。文章の達人でなくてもよいのですが、まったく書けないようだと仕事になりません。最低限相手に伝わる程度に書ける必要はあります。状況を報告をするにしても、ドキュメントを作りにしても、伝わらなければアウトです。
「20歳の自分に受けさせたい文章講義」の中で、仕事に活かせると思った点や、改めて重要だと感じた点を紹介します。
聞いた話を誰かに話すのが翻訳の第一歩
誰かに話すことによって、「3つの再」が得られます。
- 再構築:言葉にするプロセスで話の内容を再構築する
- 再発見:語り手の真意を「こういうことだったのか!」と再発見する
- 再認識:自分がどこに反応し、なにを面白いと思ったのか再認識する
「1. 再構築」は、私も仕事で、相手の理解度を確認するために使ったりもします。自分が相手に説明した内容を、相手の口から説明しなおしてもらいます。うまく説明できない場合はたいてい理解できていません。
「2. 再発見」は、聞いた時には分からなかったことに気づくことです。例えば、先日旅行に行ったことを自慢しているように見えて、実は今度一緒に旅行に行きたい思っているとか。あるいは、報告結果が正しいように見えて実は論理の破綻があったとか。
「3. 再認識」は、自分がどこにピントを合わせていたかです。同じ話でも聞き手によって、受け取り方が異なります。4人で焼肉を行った話であっても、ある人はどこの焼肉屋かにピントを合わせていて、ある人は一緒に行ったのが誰かにピントを合わせていたりします。
論理破綻に気づくためのキーワードは接続詞
以下は、本書に載っていた例文です。
企業のリストラが進み、日本の終身雇用制度は崩壊した。能力主義の浸透は、若手にとっては大きなチャンスでもある。若い世代の前途は明るい。学生たちは自信を持って就職活動に励んでほしい。
古賀史健. 20歳の自分に受けさせたい文章講義 (Japanese Edition) (Kindle の位置No.628-629). Kindle 版.
一見それっぽいことを書いているように見えるものの、それぞれの文の意味がつながっておらず、支離滅裂な文章です。
この文章に接続詞を加えると意味が通るか・・・というと通りません。接続詞を加えても成り立たないということは、そもそも論理が破綻しています。
論理の破綻に気づくには「そこに接続詞が入るかチェックせよ」というわけです。
文章の視覚的リズム
文章には文体と呼ばれるものがあり、その正体は「リズム」です。そして、リズムには視覚的リズムと聴覚的リズムの2種類があります。読者は文章を眼で読んでいるので、視覚的リズムが今ひとつだと読みづらいと判断されます。
古賀さんは次の3点が、視覚的リズムを決める3つの要素だと述べています。
- 句読点の打ち方
- 改行のタイミング
- 漢字とひらがなのバランス
これは何となくイメージが付きやすいです。すでに気をつけている方も多い点だと思います。
自分の文章を音読する際のポイント
聴覚的リズムの良し悪しは、音読してチェックするのが効果的です。音読することは、自分の文章を客観的に見る手助けになります。次のポイントに注意し音読することで、読むだけでは気づかなかった点に気づけます。
- 読点「、」の位置を確認する
- 言葉の重複を確認する
断定はハイリスク・ハイリターン
断定した方がリズムと勢いがある
「5年後は音声メディアが世界を席巻するのではないかと考えられます」と「5年後は音声メディアが世界を席巻しています」だと、後者の方が聞いてて気持ちがいいですよね。
でも、どちらが正しいのかと言われれば前者です。未来のことを断定はできません。実際に文章を書いてみると分かりますが、断定を使うのは怖いです。断定は強烈な反発を食らうリスクがあります。しかし、断定を避けると説得力が低くなります。
どうすれば、断定を使えるのか。それは論理です。 断定する箇所の前後を、しっかりした論理で固めるしかありません。
断定を使った文章に論理の破綻があれば、読者からの攻撃を受けます。なので、断定を使う際はいつも以上に論理の正確性が求められます。少なくとも断定した箇所の前後2〜3行には細心の注意を払いましょう。
終わりに
紹介したのは第1講までの内容ですが、本書は第4講まであります。第1講までの内容が面白そうだと思った方は、第2講以降もオススメできる内容でした。
出典
【AWS】Lambdaをローカル環境でテストするのにSAMを使う
ローカル環境でLambdaをテストするには「AWS SAM」を使います。Lambdaのテスト方法は主には以下の2択です。
- 本物のLambda関数でテスト
- ローカル環境でSAMでテスト
本物のLambda関数をテストしたくない場合、ローカル環境でSAMの方を選択することになります。本記事ではローカル環境でSAMを使用し、Lambda関数をテストする方法を紹介します。
[1] AWS SAMのインストール
SAMのインストール方法とチュートリアルの実行例は下記記事で紹介しています。
https://predora005.hatenablog.com/entry/2021/06/01/190000predora005.hatenablog.com
[2] プロジェクトの作成
sam initでプロジェクトを作成します。ここでは、Python3.8のHello, Worldプロジェクトを例に説明していきます。詳細は別記事で紹介しています。
$ sam init ...(途中省略)... ----------------------- Generating application: ----------------------- Name: sam-app Runtime: python3.8 Dependency Manager: pip Application Template: hello-world Output Directory: .
sam initは対話形式ですが、以下のようにパラメータを指定することも可能です。
# パラメータを指定 $ sam init --name sam-app --runtime nodejs10.x --dependency-manager npm --app-template hello-world $ sam init --name sam-app --package-type image --base-image nodejs10.x-bas # GitHubに保存したテンプレートから作成 $ sam init --location gh:aws-samples/cookiecutter-aws-sam-python $ sam init --location git+ssh://git@github.com/aws-samples/cookiecutter-aws-sam-python.git $ sam init --location hg+ssh://hg@bitbucket.org/repo/template-name # zip化したテンプレートから作成 $ sam init --location /path/to/template.zip $ sam init --location https://example.com/path/to/template.zip # ローカルに保存されたテンプレートから作成 $ sam init --location /path/to/template/folder
[3] ビルド
sam buildでビルドします。
$ cd sam-app/ $ sam build Building codeuri: /home/ec2-user/sam-app/hello_world runtime: python3.8 metadata: {} functions: ['HelloWorldFunction'] Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guided
[4] テスト
[4-1] 関数を直接呼び出し
sam local invokeで関数をローカルで呼び出せます。
$ sam local invoke Invoking app.lambda_handler (python3.8) Image was not found. Building image........................ Skip pulling image and use local one: amazon/aws-sam-cli-emulation-image-python3.8:rapid-1.23.0. Mounting /home/ec2-user/sam-app/.aws-sam/build/HelloWorldFunction as /var/task:ro,delegated inside runtime container END RequestId: e3e79ef0-1db0-4713-a3bb-434dd4022e4f REPORT RequestId: e3e79ef0-1db0-4713-a3bb-434dd4022e4f Init Duration: 0.34 ms Duration: 307.81 mBilled Duration: 400 ms Memory Size: 128 MB Max Memory Used: 128 MB {"statusCode": 200, "body": "{\"message\": \"hello world\"}"}
-eオプションで、イベントファイルを読み込ませることも可能です。
$ sam local invoke "HelloWorldFunction" -e events/event.json
[4-2] API Gatewayをローカルで起動
sam local start-apiで、API Gatewayのローカルインスタンスを起動できます。
$ sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2021-05-01 14:38:53 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)
表示されたURL(エンドポイント)にアクセスすると、応答が返ってきます。
$ curl http://127.0.0.1:3000/hello {"message": "hello world"}
[4-3] Lambda関数のエンドポイントをローカルに作成
[4-3-1] 実行方法
sam local start-lambdaでLambda関数のエンドポイントを作成できます。単発でテストする分にはsam local invokeでも問題ありませんが、AWS SDKを用いてプログラムから起動する場合などで有効活用できます。
$ sam local start-lambda Starting the Local Lambda Service. You can now invoke your Lambda Functions defined in your template through the endpoint. 2021-05-01 14:39:41 * Running on http://127.0.0.1:3001/ (Press CTRL+C to quit)
aws lambda invokeを使い、エンドポイント経由で起動できます。
$ aws lambda invoke --function-name "HelloWorldFunction" --endpoint-url "http://127.0.0.1:3001" --payload file://events/event.json response.json { "StatusCode": 200 }
[4-3-2] コマンドのオプション
aws lambda invokeの主なオプションは次の通りです。
| オプション | 内容 |
|---|---|
| function-name | 関数名 |
| endpoint-url | エンドポイント |
| invocation-type | RequestResponse,Event, DryRunのいずれか。RequestResponseは同期的呼出、Eventは非同期呼出。 |
| payload | Lambda関数へ渡す入力 |
| log-type | TailでLogResultを出力、Noneで出力無し。ローカルでは Tailは使えないよう。 |
| no-verify-ssl | SSL 証明書認証をスキップ |
詳細は公式のリファレンスに記載があります。
invoke — AWS CLI 1.19.62 Command Reference
sam local start-lambdaのオプションについても公式に一覧が載っています。
sam local start-lambda - AWS Serverless Application Model
[4-4] サンプルイベントを使う
sam local generate-eventを使うと、サンプルイベントを作成してくれます。helpオプションでイベントの種類が確認できます。
$ sam local generate-event --help ...(途中省略)... Commands: alexa-skills-kit alexa-smart-home apigateway appsync batch cloudformation cloudfront cloudwatch codecommit codepipeline cognito config connect dynamodb kinesis lex rekognition s3 sagemaker ses sns sqs stepfunctions
以下はAPI Gateway(apigateway)の例です。まずはヘルプで使い方を確認します。
$ sam local generate-event apigateway -h Usage: sam local generate-event apigateway [OPTIONS] COMMAND [ARGS]... Options: -h, --help Show this message and exit. Commands: authorizer Generates an Amazon API Gateway Authorizer Event aws-proxy Generates an Amazon API Gateway AWS Proxy Event
イベントを出力し、出力したイベントをLambda関数に渡すことができます。
$ sam local generate-event apigateway aws-proxy > events/apigateway-event.json $ sam local invoke "HelloWorldFunction" -e events/apigateway-event.json
[4-5] より詳細を知りたい場合は
公式(下記)を参照してください。
[5] ユニットテスト(pytest)
AWS SAMの機能ではありませんが、Hello, Worldテンプレートにユニットテスト用のソースが格納されています。pytestで実行すると以下のようになります。
$ pytest tests/unit/ ======================================= test session starts ======================================= platform linux -- Python 3.8.5, pytest-6.2.3, py-1.10.0, pluggy-0.13.1 rootdir: /home/ec2-user/sam-app plugins: mock-3.6.0 collected 1 item tests/unit/test_handler.py . [100%] ======================================== 1 passed in 0.03s ========================================
pytestのインストールはpipで可能です。
$ pip3 install -U pytest pytest-mock --user
Installation and Getting Started — pytest documentation
終わりに
「SAM」は「Cloud Formation」と似た機能(公式は拡張機能と言っている)であり、学習コストがかかるのも「CloudFormation」と同じです。しかし、「CloudFormation」は現在フル活用している程に便利な機能なので、SAMも少しずつ使いこなせるようにしたいと思います。
参考文献
出典
補足
[補足1] ローカルエンドポイントに対してAWS SDKから呼出
AWS SDK for Python (Boto3) のインストールはpipコマンドで行います。
$ pip3 install boto3 --user
下記公式に掲載されているソースコードをそのまま実行すると、次の結果が得られます。
$ python3 lambda-endpoint.py Traceback (most recent call last): File "lambda-endpoint.py", line 30, in <module> assert response == "Hello World" AssertionError
responseは"Hello World"ではないので、この動作は正常です。assertで例外を出さないためには、数行の追加とassertの行を変更が必要です。
import json ...(途中省略)... payload = json.load(response['Payload']) body = json.loads(payload['body']) # (変更前) assert response == "Hello World" assert body['message'] == "hello world"
Integrating with automated tests - AWS Serverless Application Model
[補足2] デプロイ時に生成されるsamconfig.toml
version = 0.1 [default] [default.deploy] [default.deploy.parameters] stack_name = "sam-app" s3_bucket = "aws-sam-cli-managed-default-samclisourcebucket-xgx2dia4ru2p" s3_prefix = "sam-app" region = "ap-northeast-1" confirm_changeset = true capabilities = "CAPABILITY_IAM"
[補足3] パッケージ
作成したアプリをパッケージ化してS3バケットにアップロードします。
$ sam package --template-file template.yaml --s3-bucket {バケット名} \ --s3-prefix hello_world --output-template-file template_packaged.yaml
--s3-prefixはzipを直接バケット直下に置いてもいい場合は指定不要です。上の例ではhello_worldフォルダ下にzipが格納されます。
--output-template-fileには変更後のテンプレート出力先をセットします。テンプレート内のCodeUriがzipが格納されたS3のURLに変更されています。
このパッケージを使って、デプロイが可能になります。
$ sam deploy --template-file /home/ec2-user/sam-app/package_template.yaml --stack-name <YOUR STACK NAME>
【AWS】ウェブアプリケーションの構築(Amplify+Cognito+Lambda)
AWS公式のハンズオン「サーバーレスのウェブアプリケーションを構築」に習って、簡単なウェブアプリの構築を行いました。
このハンズオンを通して、以下の要素に触れることができます。
AWSのハンズオンやチュートリアルはモノによって分かりやすさに差があります。このハンズオンは分かりやすい方だったのでオススメです。
- [1] Gitリポジトリの作成(CodeCommit)
- [2] ウェブサイトをデプロイする(Amplify)
- [3] ユーザー管理(Cognito)
- [4] DynamoDBテーブルを作成
- [5] Lambda関数の作成
- [6] REST APIの作成(API Gateway)
- [7] リソースの削除
- 終わりに
- 出典
[1] Gitリポジトリの作成(CodeCommit)
ウェブアプリケーションのソース(index.html等)は「CodeCommit」で管理します。
[1-1] リポジトリの作成
まずはリポジトリを作成します。
「wildrydes-site」というリポジトリを作成します。
リポジトリが作成できたら、URLをコピーしてクローンします。
[1-2] IAMでGit認証情報を生成
Git認証情報を作成していない場合は、クローンする前に作成しておきます。IAMで使用するユーザを選択し、下にスクロールすると[認証情報を生成]があります。
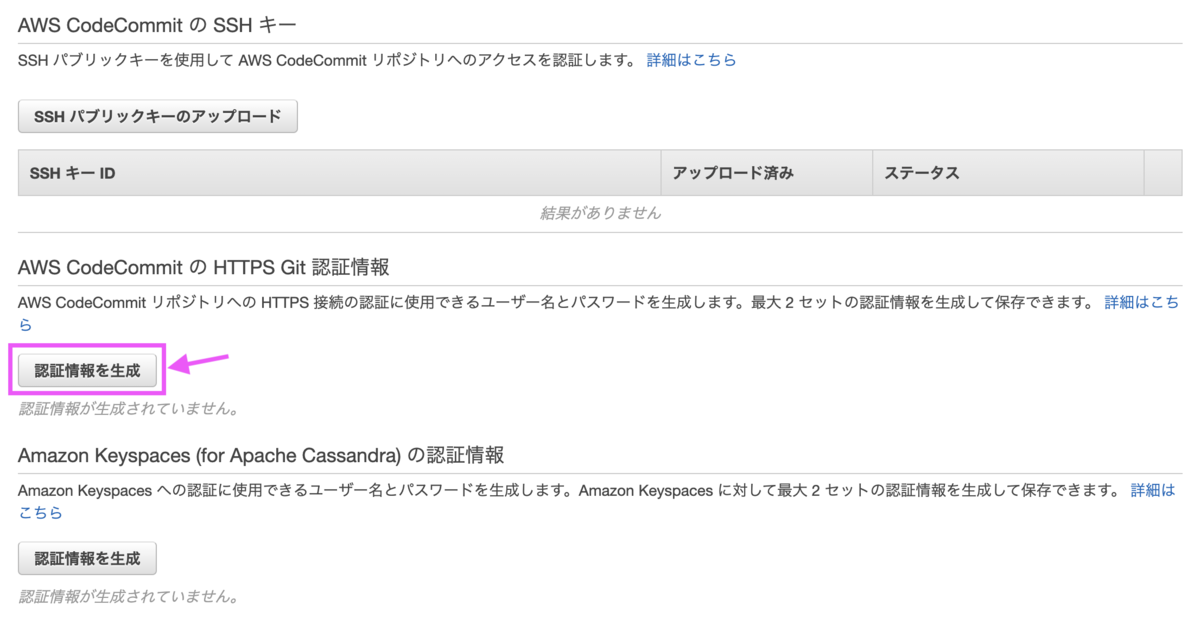
ボタンを押すと、ユーザー名とパスワードが表示されます。これらをCodeCommitでの認証に使用します。
[1-3] AWSが用意してくれたサイトをコピーする
git cloneで先程作成したリポジトリをローカル環境に複製します。{ユーザー名}と{パスワード}はIAMで取得した認証情報を入力します。
git clone https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/wildrydes-site Cloning into 'wildrydes-site'... Username for 'https://git-codecommit.ap-northeast-1.amazonaws.com': {ユーザー名} Password for 'https://{ユーザー名}@git-codecommit.ap-northeast-1.amazonaws.com': {パスワード} warning: You appear to have cloned an empty repository.
AWS CLIからAWS側で用意されたサイトをコピーします。AWS CLIを初めて使用する場合はaws configureで初期設定を事前に行います。
$ cd wildrydes-site/ $ aws s3 cp s3://wildrydes-us-east-1/WebApplication/1_StaticWebHosting/website ./ --recursive
git addで変更を追加して、コミット・プッシュを行います。
$ git add . $ git commit -m "Initial commit" $ git push Username for 'https://git-codecommit.ap-northeast-1.amazonaws.com': {ユーザー名} Password for 'https://{ユーザー名}@git-codecommit.ap-northeast-1.amazonaws.com': {パスワード} Enumerating objects: 95, done. Counting objects: 100% (95/95), done. Delta compression using up to 2 threads Compressing objects: 100% (94/94), done. Writing objects: 100% (95/95), 9.44 MiB | 16.08 MiB/s, done. Total 95 (delta 2), reused 0 (delta 0) To https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/wildrydes-site * [new branch] master -> master
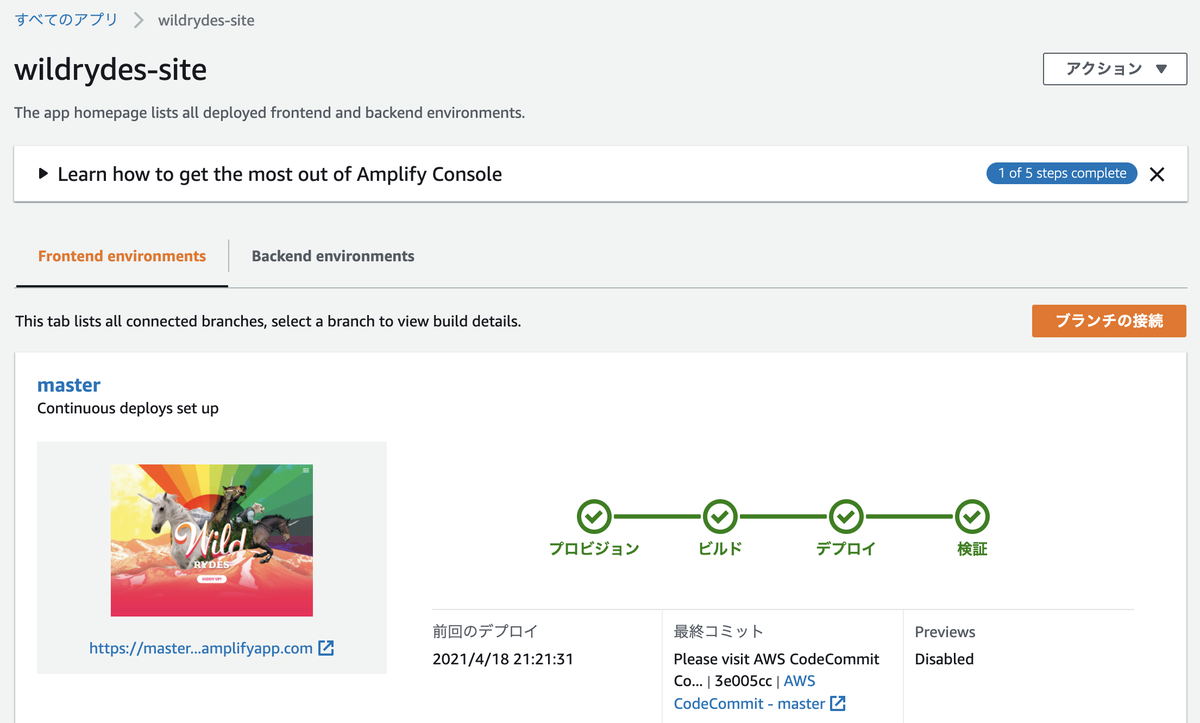
[2] ウェブサイトをデプロイする(Amplify)
ウェブサイトの構築・デプロイは「Amplify」で行います。
[2-1] デプロイ
Amplifyの画面からウェブアプリケーションを作成していきます。
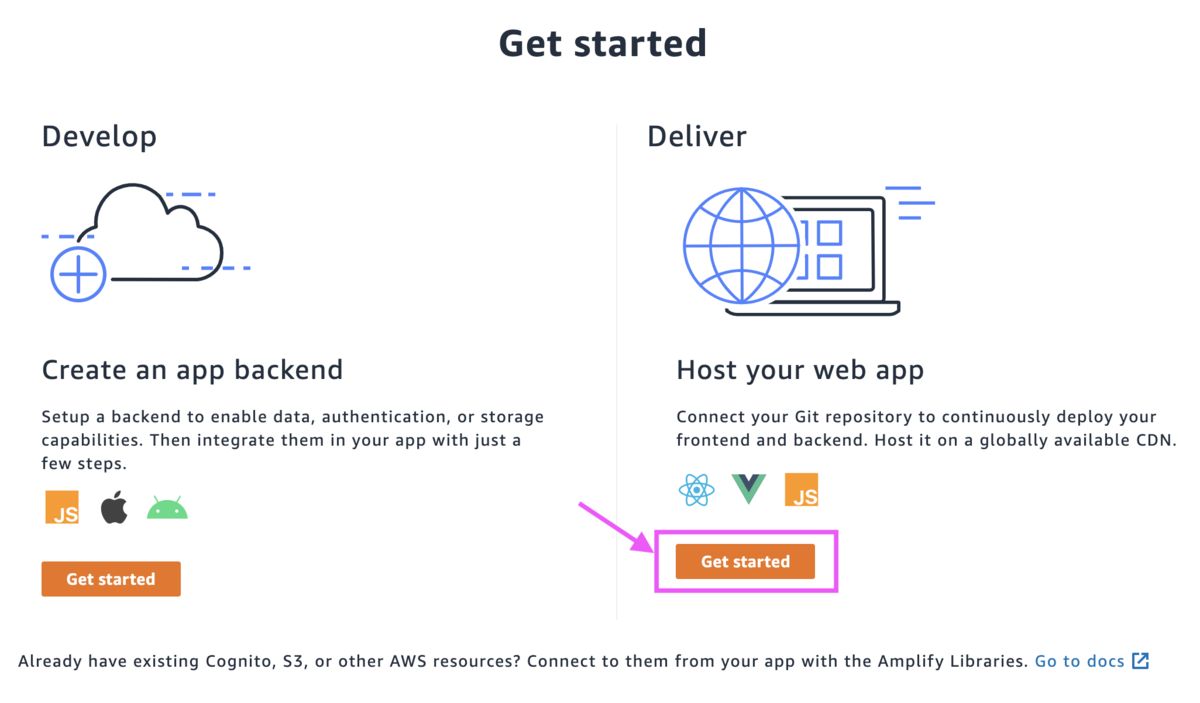
[AWS CodeCommit]を選択します。
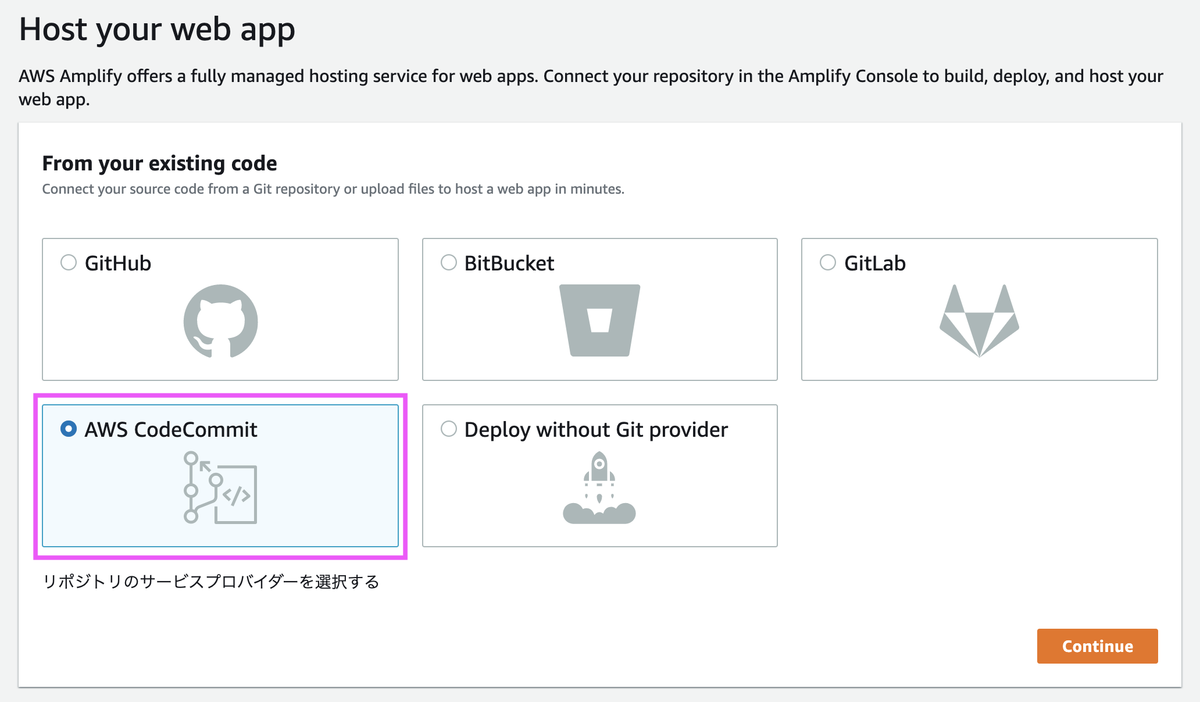
先程作成したリポジトリを選択します。
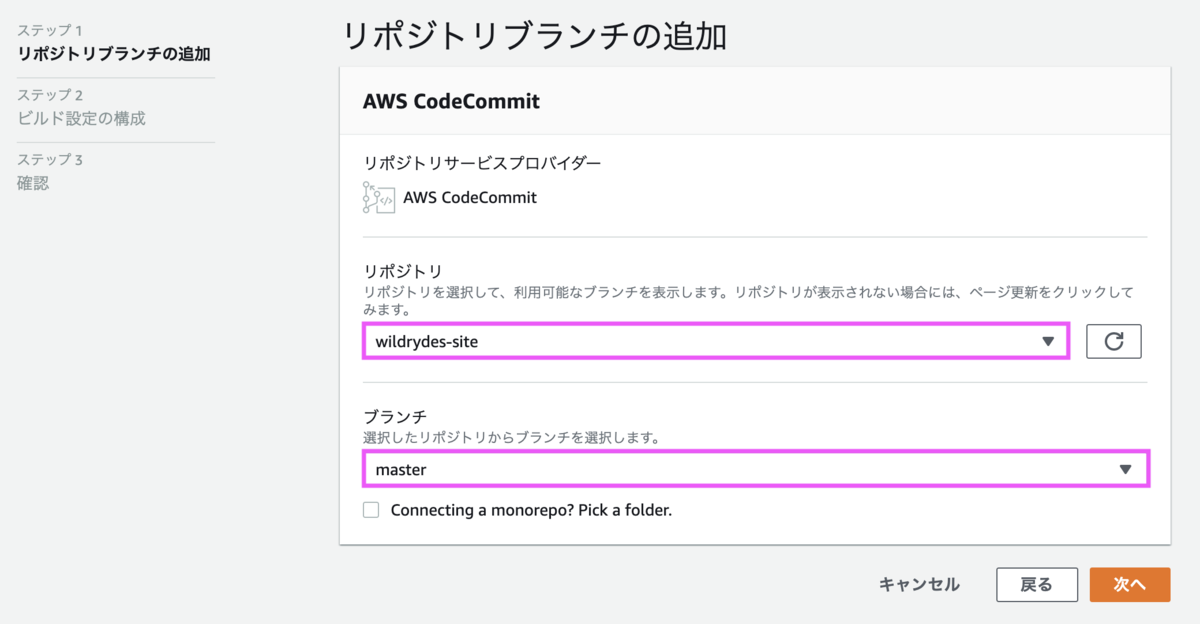
アプリの名前は任意で問題ありません。ここではチュートリアル通りの名称としています。
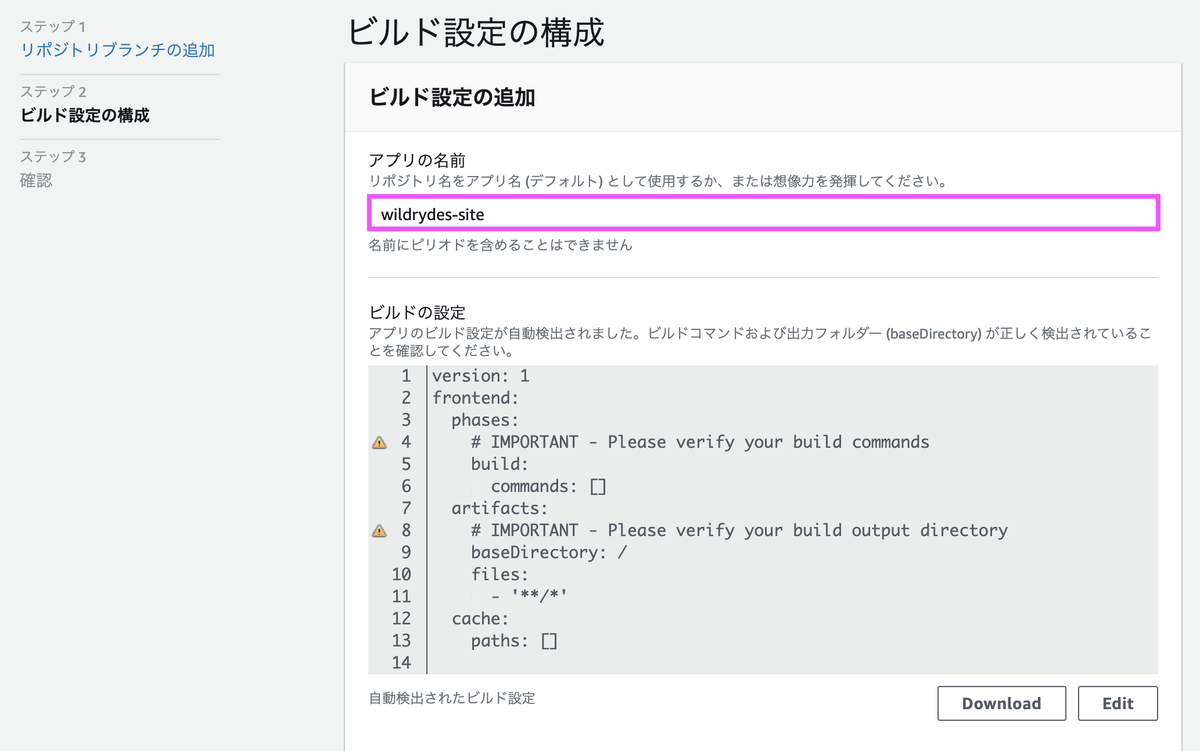
作成してから検証が終わるまで数分かかります。

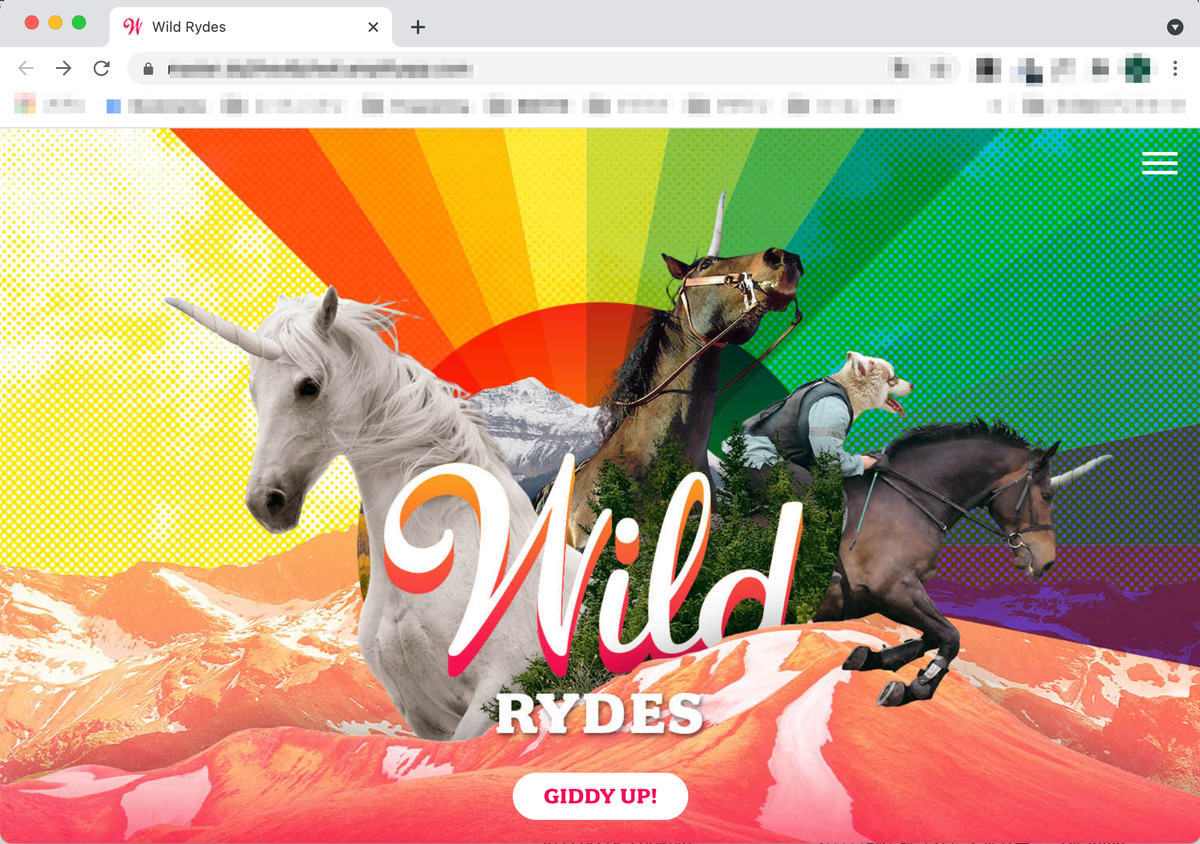
検証が終わったのちURLをクリックすると、ウェブサイトが表示されます。
[2-2] サイトの変更
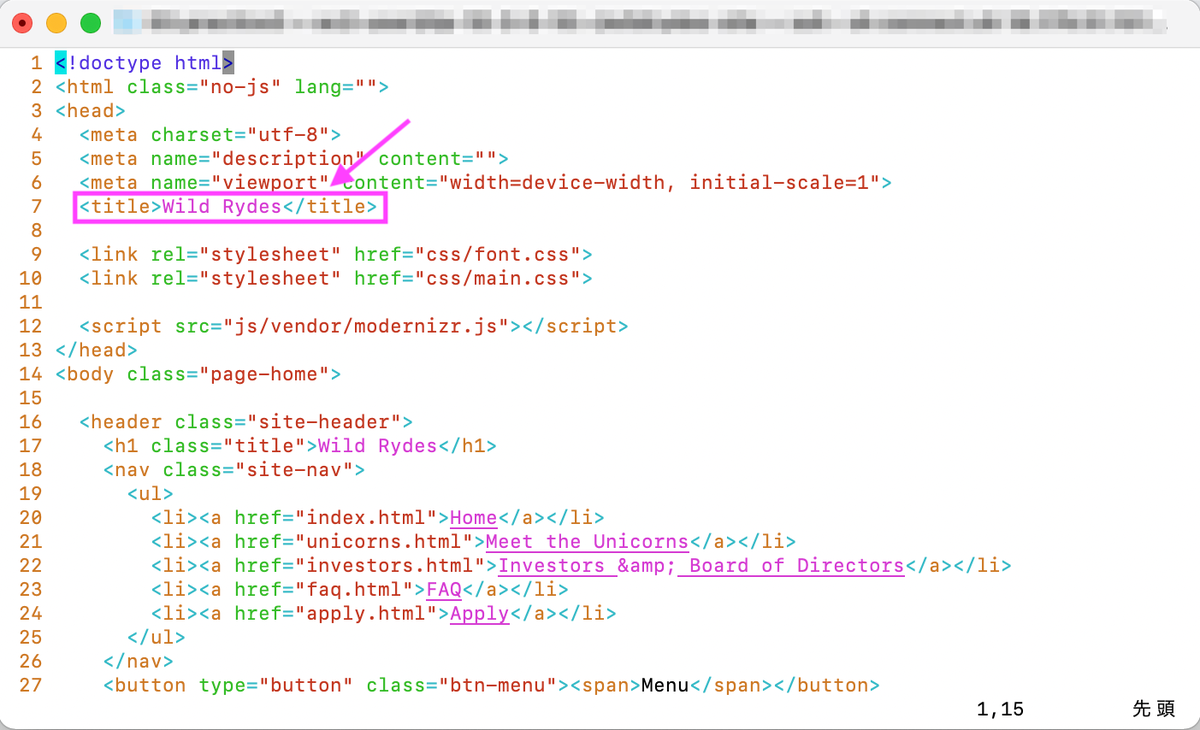
index.htmlを変更・コミットして、Webサイトに反映されるか確認します。index.htmlを開いてtitleを変更します。
変更後、git add, git commit, git pushします。
$ git add index.html $ git commit -m "updated title" $ git push
git pushするとAmplifyでデプロイと検証が自動で行われます。
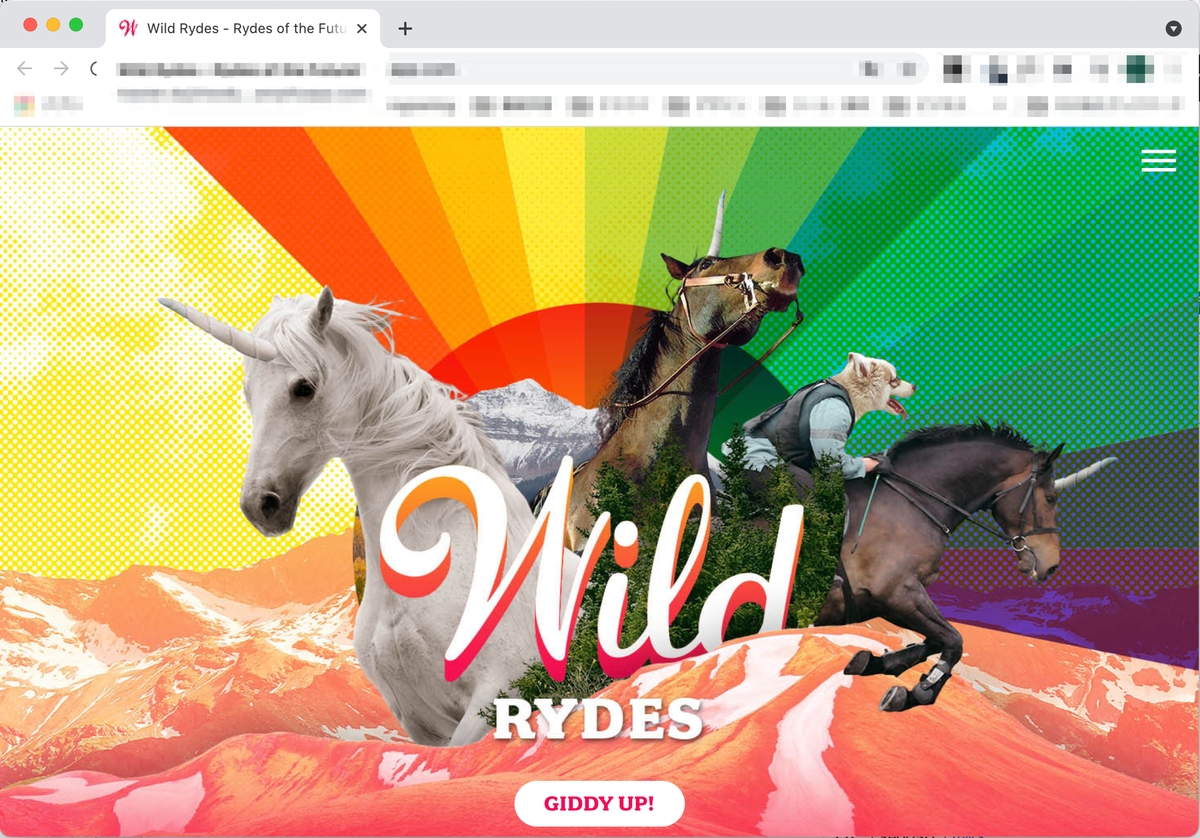
検証まで終わった後、Webサイトを表示するとtitle変更が反映されています。
[3] ユーザー管理(Cognito)
ユーザー認証は「Cognito」で行います。
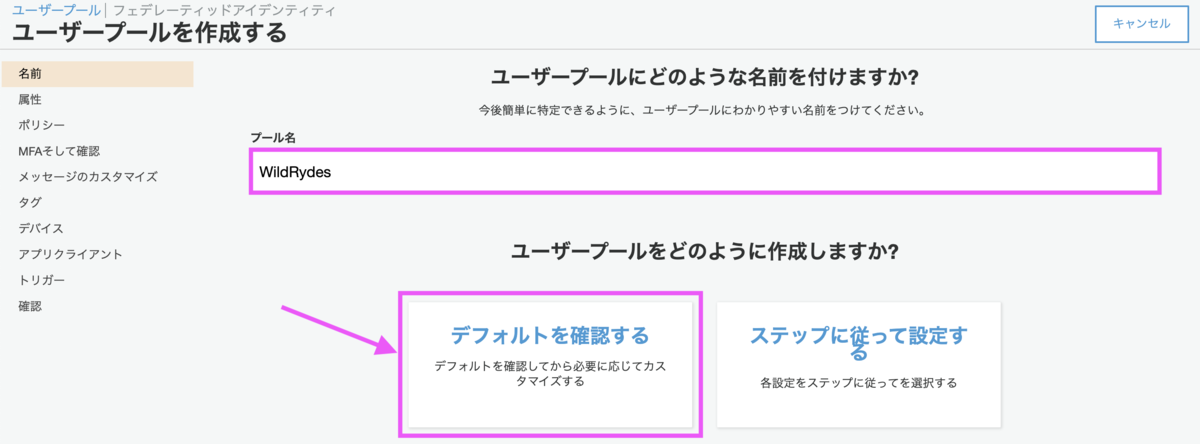
[3-1] ユーザープールを作成


[デフォルトを確認する]の方を選択します。プール名は任意の名称で構いません。
デフォルト設定のままで作成を完了します。
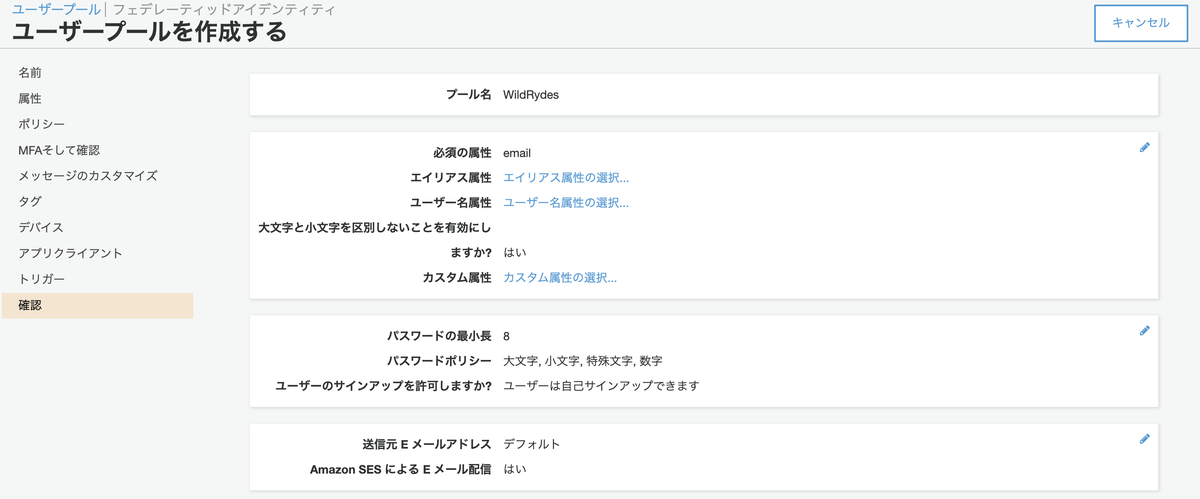
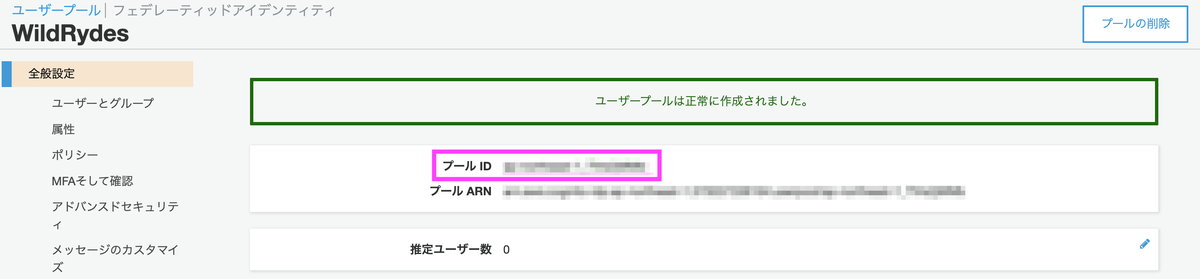
以上でユーザープールの作成は完了です。プールIDはこの後使用します。
[3-2] ユーザープールにアプリクライアントを追加

アプリクライアント名は任意で問題ありません。[クライアントシークレットを生成]のチェックは外します。
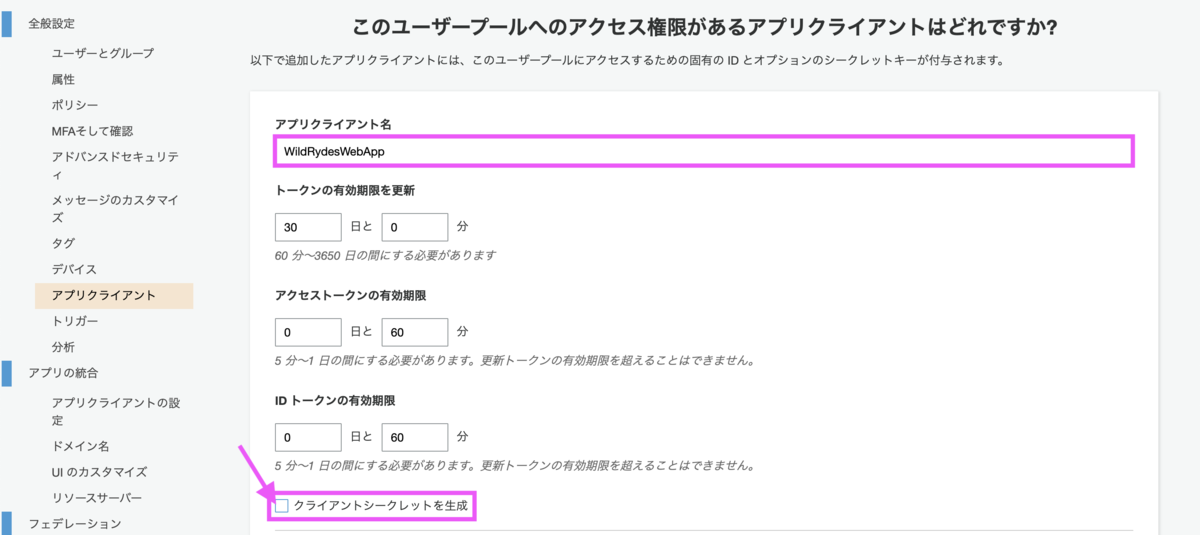
今回作成するブラウザベースのアプリでは、クライアントシークレットがサポートされていないためです。ハンズオンに以下の記載がありました。
クライアントシークレットは、現在ブラウザベースのアプリケーションでの使用はサポートされていません。
表示されたアプリクライアントIDはこの後使用します。

[3-3] ウェブサイトの設定を更新
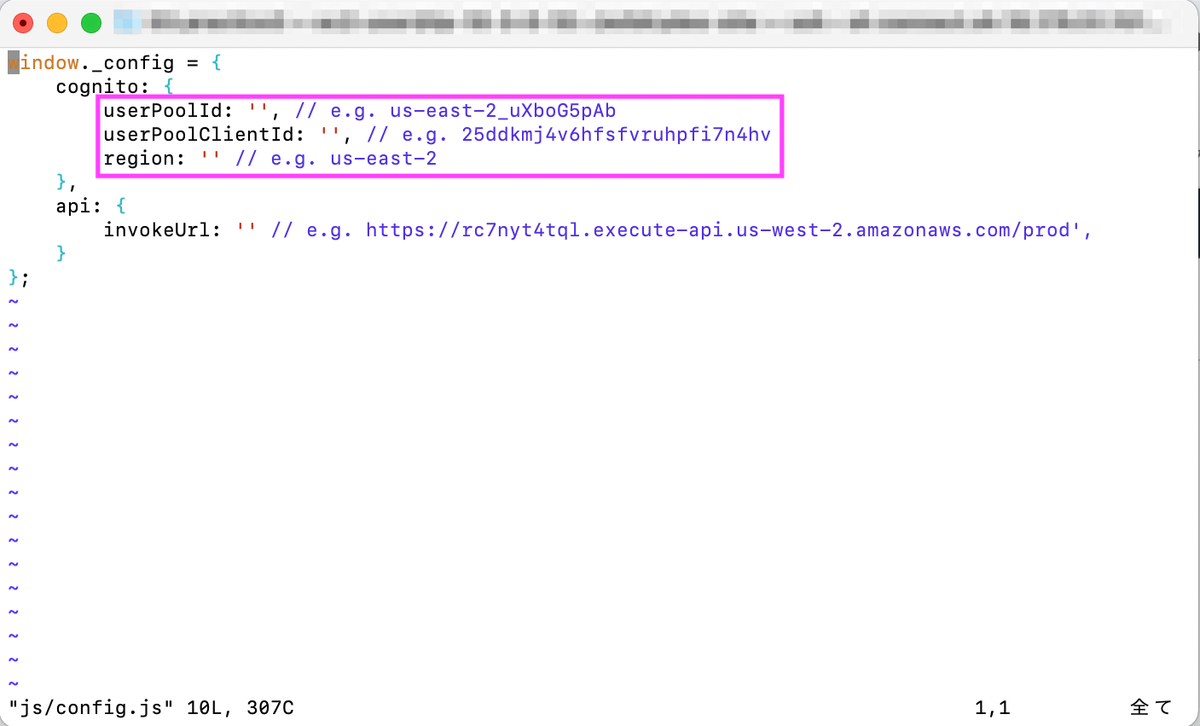
js/config.jsを開き、先述の手順で取得したプールID、アプリクライアントIDを入力します。
- userPoolId : プールID
- userPoolClientId: アプリクライアントID
- region: リージョン
編集が終わったら変更をリポジトリに送信します。
$ git add js/config.js $ git commit -m "update cognito config" $ git push
[3-4] テスト
Amplifyでデプロイ・検証が終わったら、再度ウェブサイトにアクセスします。[GIDDY UP!]を選択すると登録画面に移動します。
メールアドレスとパスワードを入力します。メールアドレスは、実在のアドレス・ダミーアドレスどちらの入力も可能です。

実在のアドレスの場合は送信されたメールに記載の認証コードを入力します。ダミーアドレスの場合はCognitoコンソールから確認できるそうです。私は実在のアドレスを使用しました。
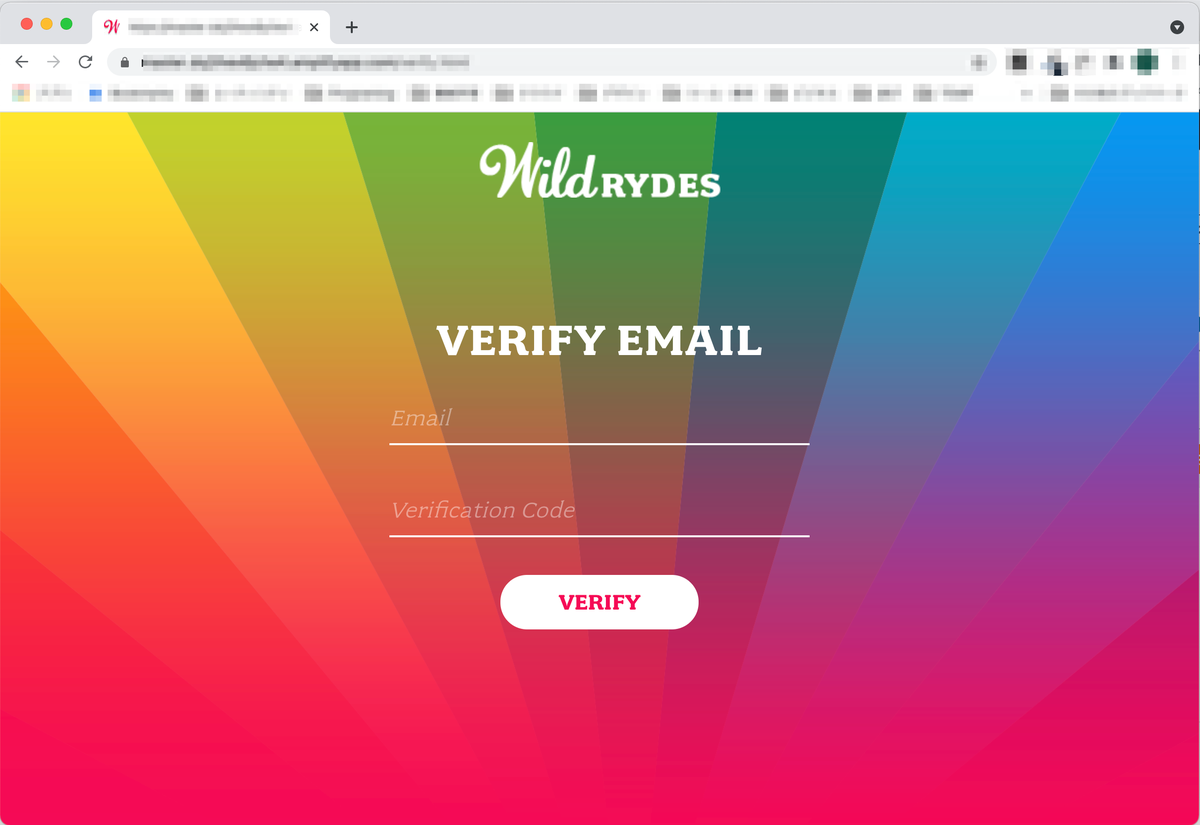
認証に成功するとダイアログが表示されます。
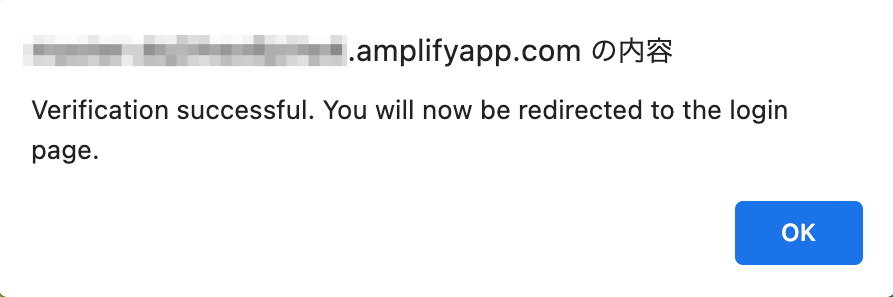
認証画面で再度メールアドレス・パスワードを入力します。

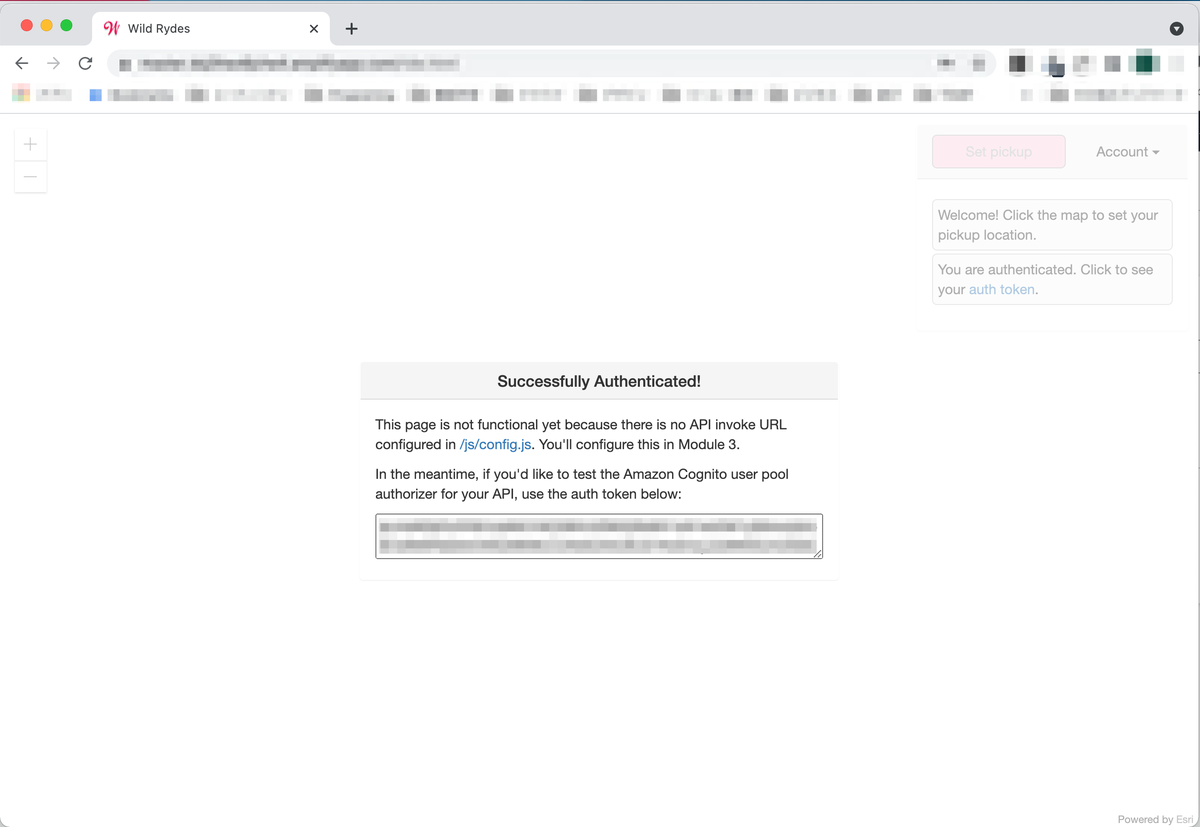
認証には成功しますが、APIが無いというメッセージが表示されます。APIはこの後設定します。
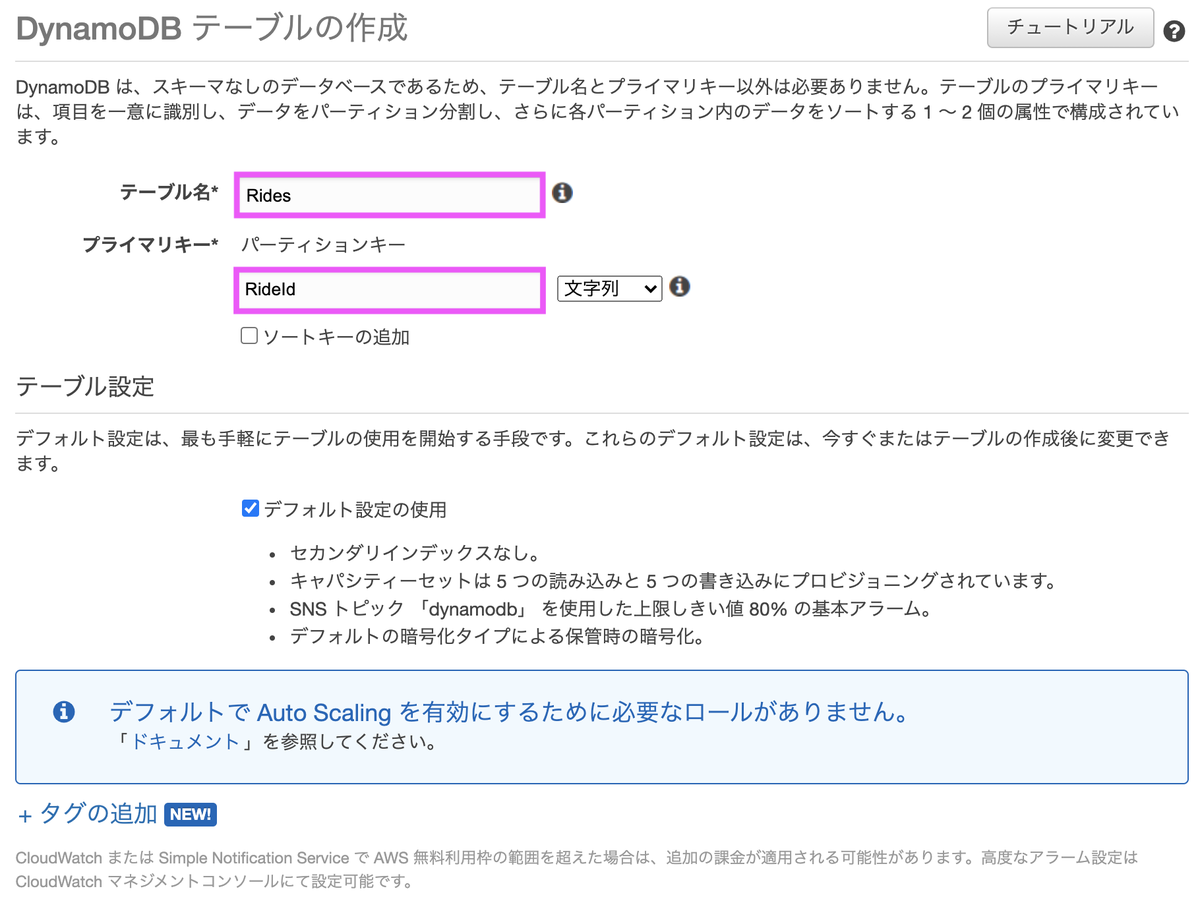
[4] DynamoDBテーブルを作成
「RideId」をプライマリキーに持つテーブルを作成します。
[5] Lambda関数の作成
[5-1] IAMロールの作成
Lambda関数作成の前に、DynamoDBにアクセスする権限を持つロールを作成します。
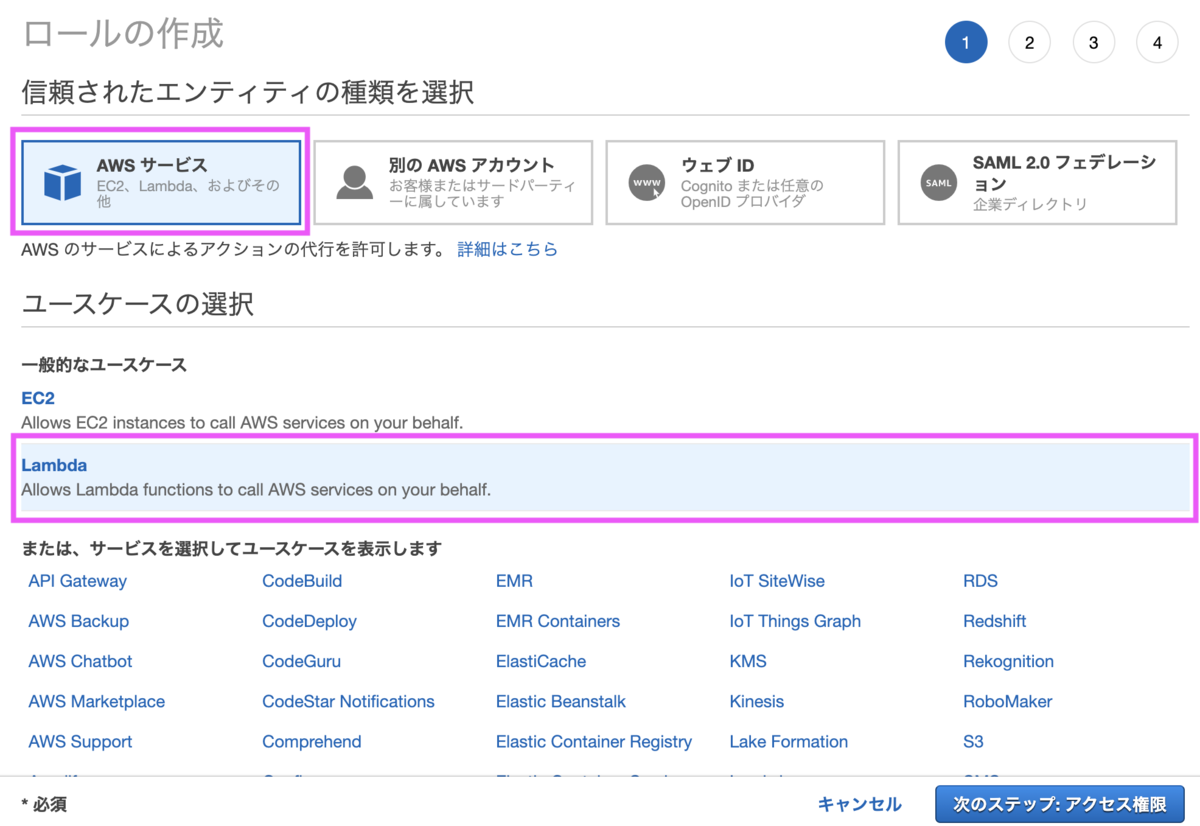
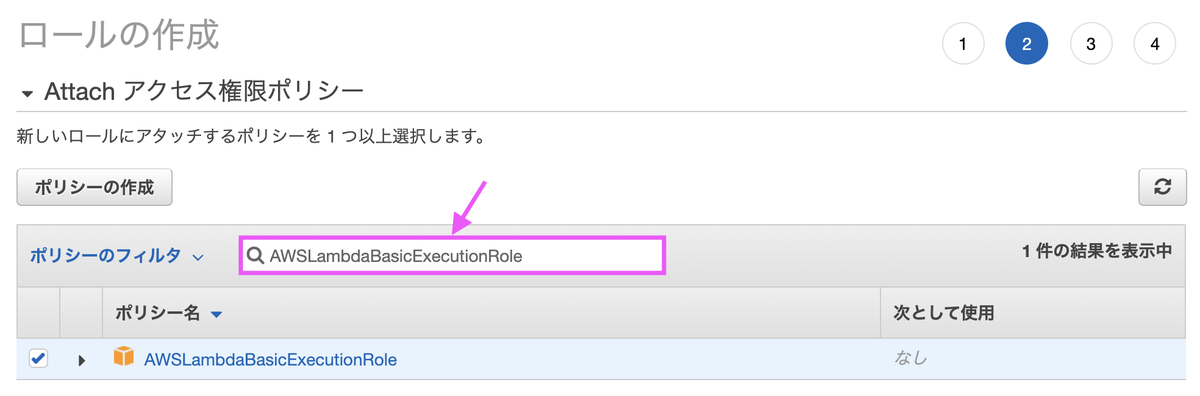
検索ボックスに「AWSLambdaBasicExecutionRole」を入力し、チェックボックスをONにします。
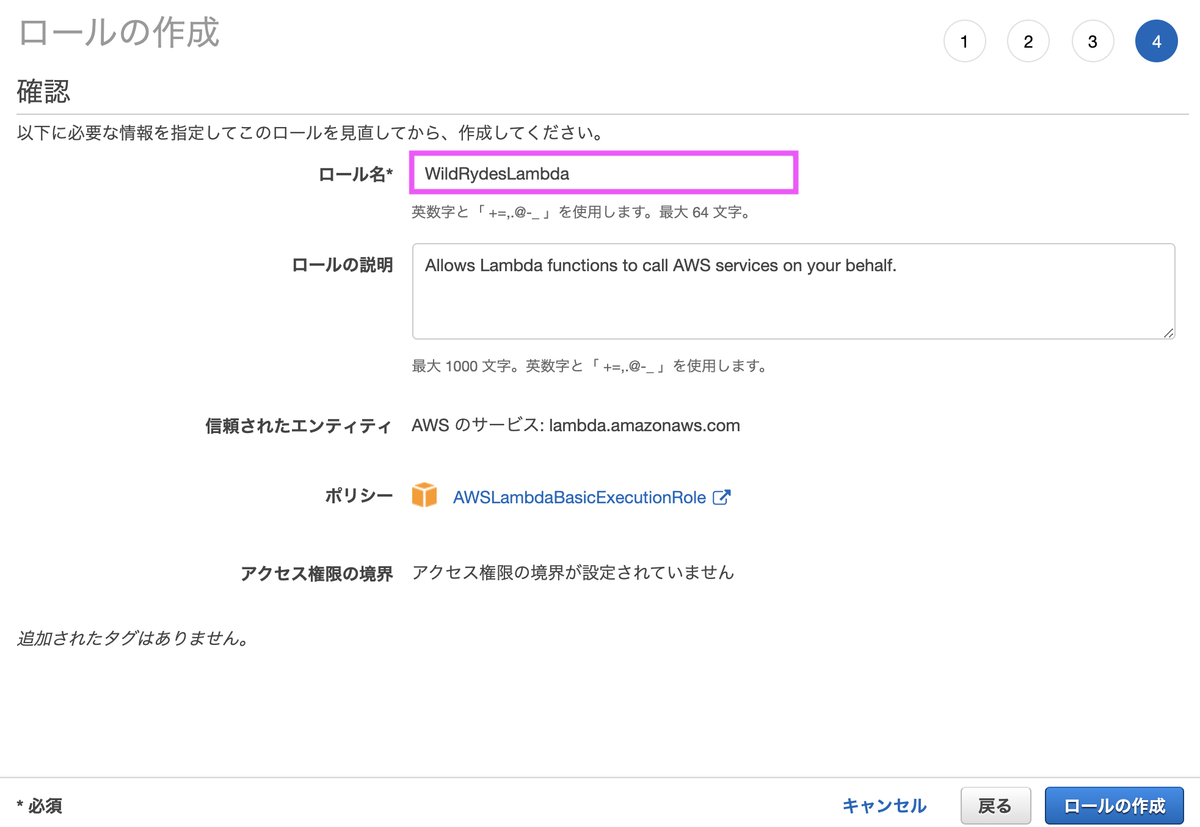
ロール名は任意の名称で問題ありません。
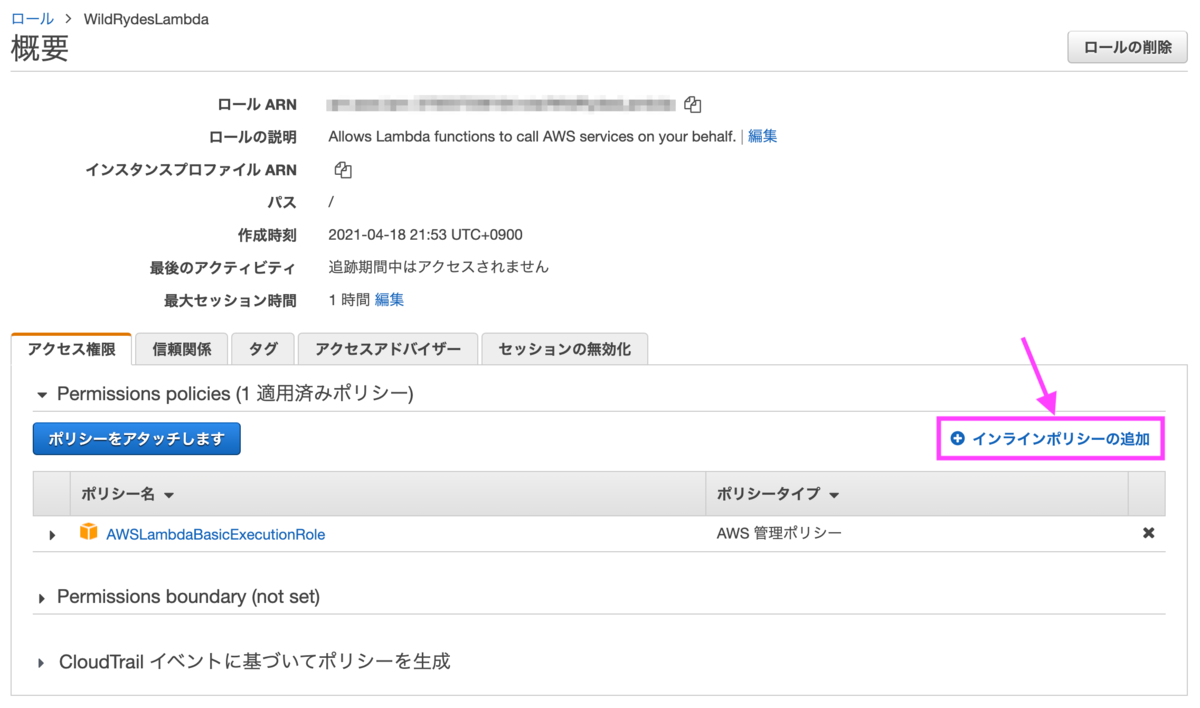
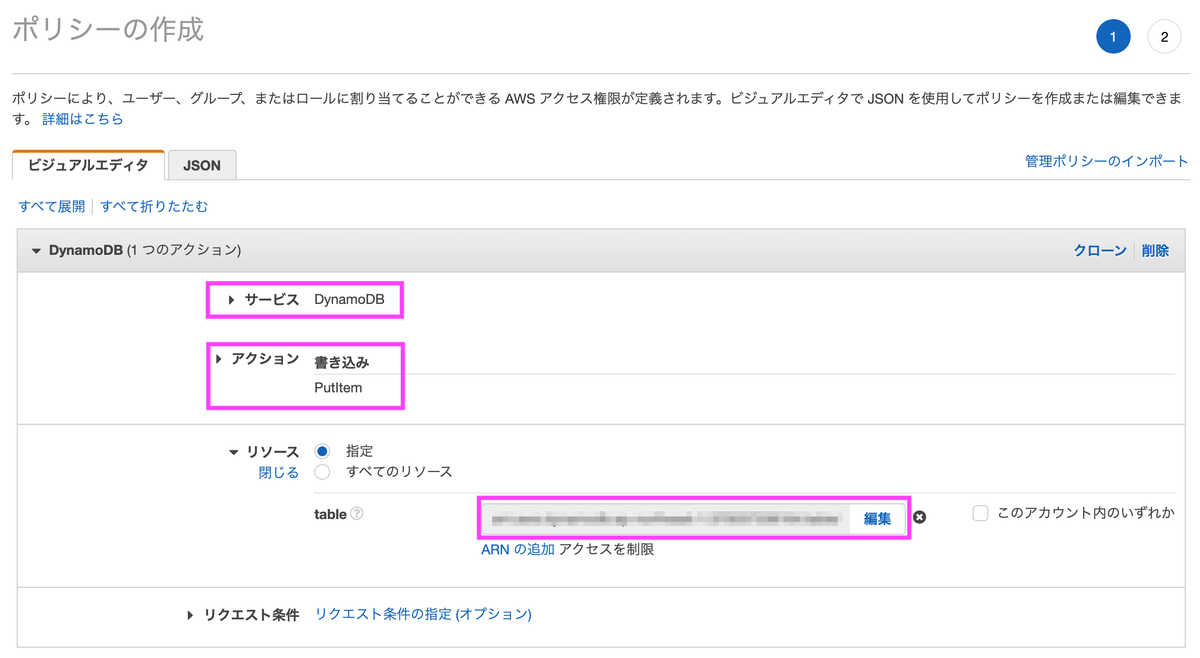
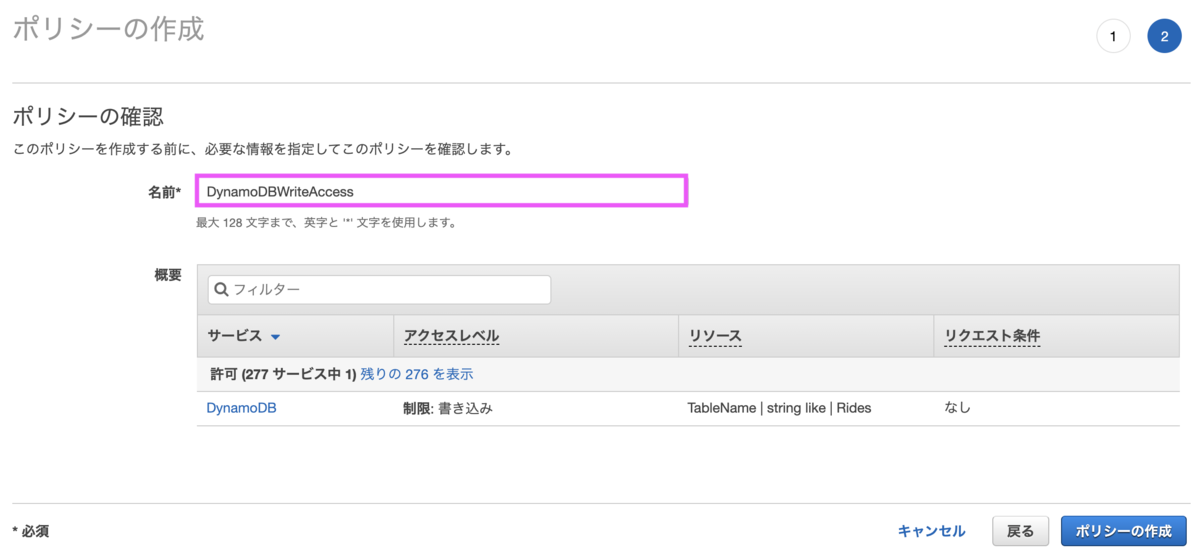
[5-2] インラインポリシーの追加
ロールにインラインポリシーを追加し、先程作成したDynamoDBへのアクセス権限を追加します。
サービス「DynamoDB」、アクション「PutItem」、リソースは先程作成したDynamoDBテーブルを指定します。
名前は任意で問題ありません。
[5-3] Lambda関数の作成
ランタイムは「Node.js」を選択します。
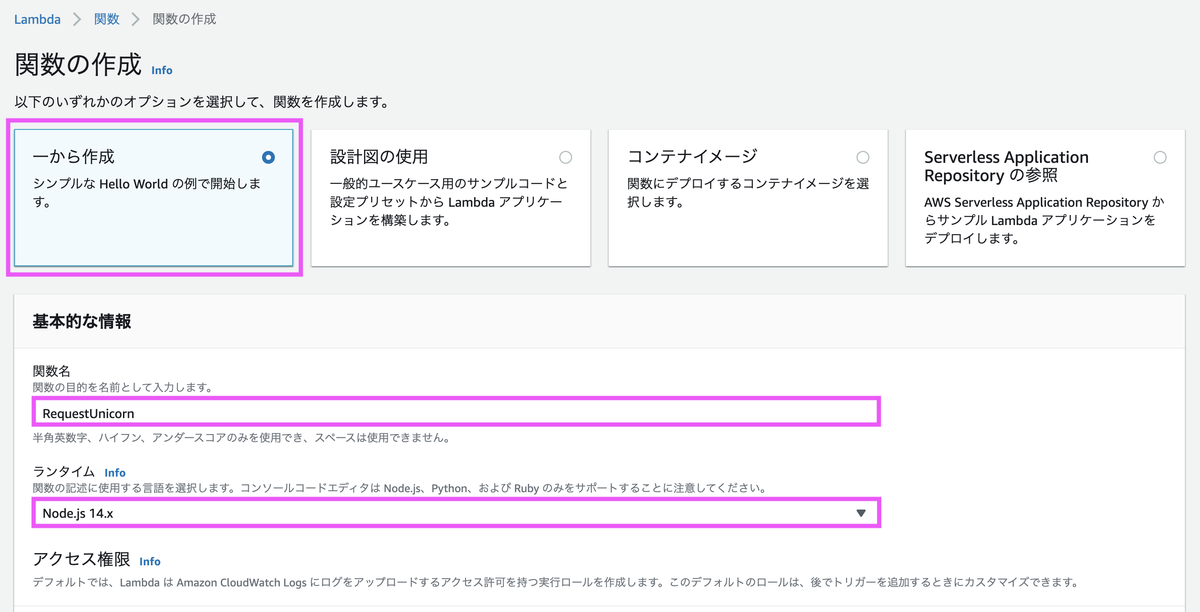
実行ロールは「既存のロールを使用する」を選択し、先程作成した IAMロールを選択します。
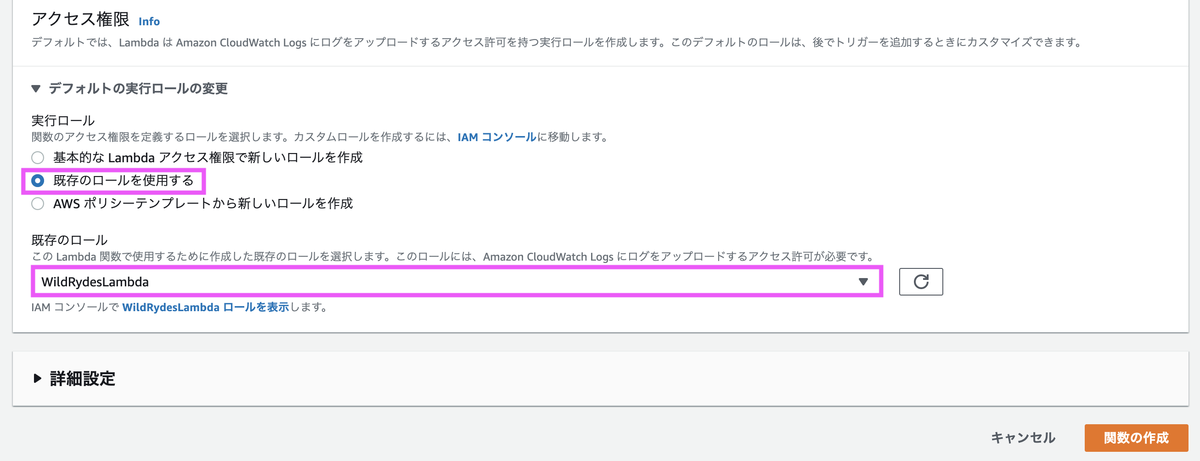
関数の作成完了後
「requestUnicorn.js」をindex.jsにコピーします。
[5-4] テスト
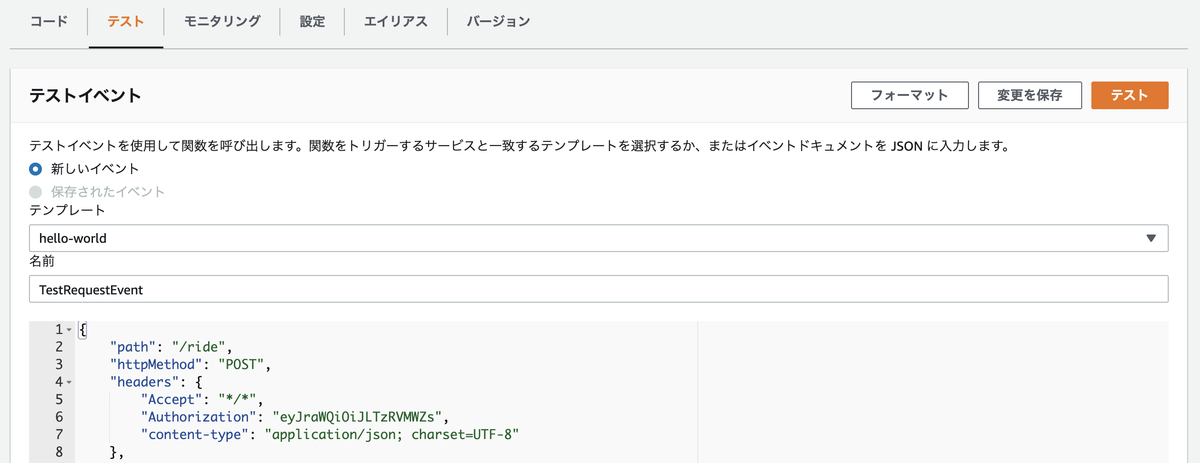
テストイベントを作成し、入力欄に下記JSONのコードをコピーします。
{ "path": "/ride", "httpMethod": "POST", "headers": { "Accept": "*/*", "Authorization": "eyJraWQiOiJLTzRVMWZs", "content-type": "application/json; charset=UTF-8" }, "queryStringParameters": null, "pathParameters": null, "requestContext": { "authorizer": { "claims": { "cognito:username": "the_username" } } }, "body": "{\"PickupLocation\":{\"Latitude\":47.6174755835663,\"Longitude\":-122.28837066650185}}" }
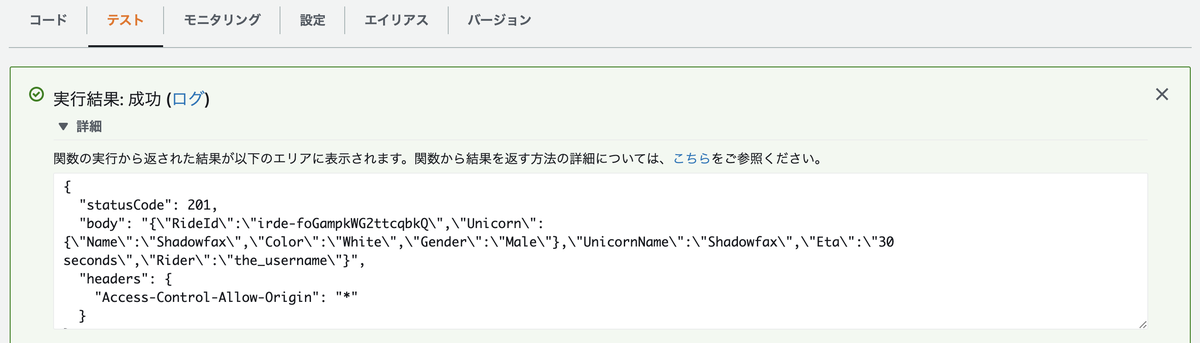
テストを実行し成功すると、以下のような結果が得られます。
[6] REST APIの作成(API Gateway)
[6-1] REST APIの作成
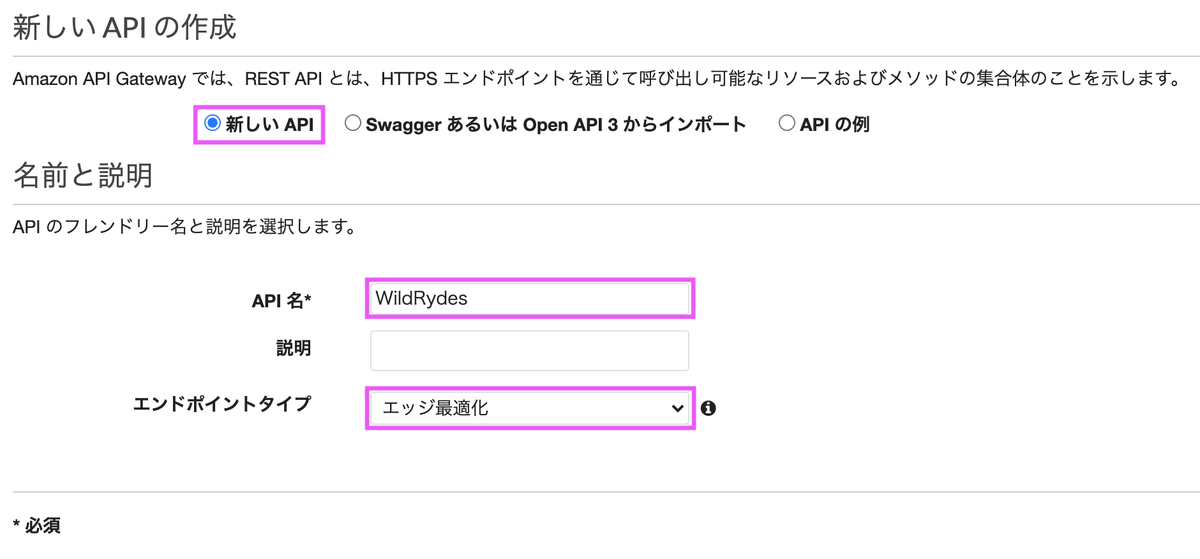
Lambda関数を呼ぶためのエンドポイントとなるREST APIを作成します。

「新しいAPI」を選択し、エンドポイントタイプは「エッジ最適化」を選択します。
[6-2] Cognito ユーザープールオーソライザーを作成
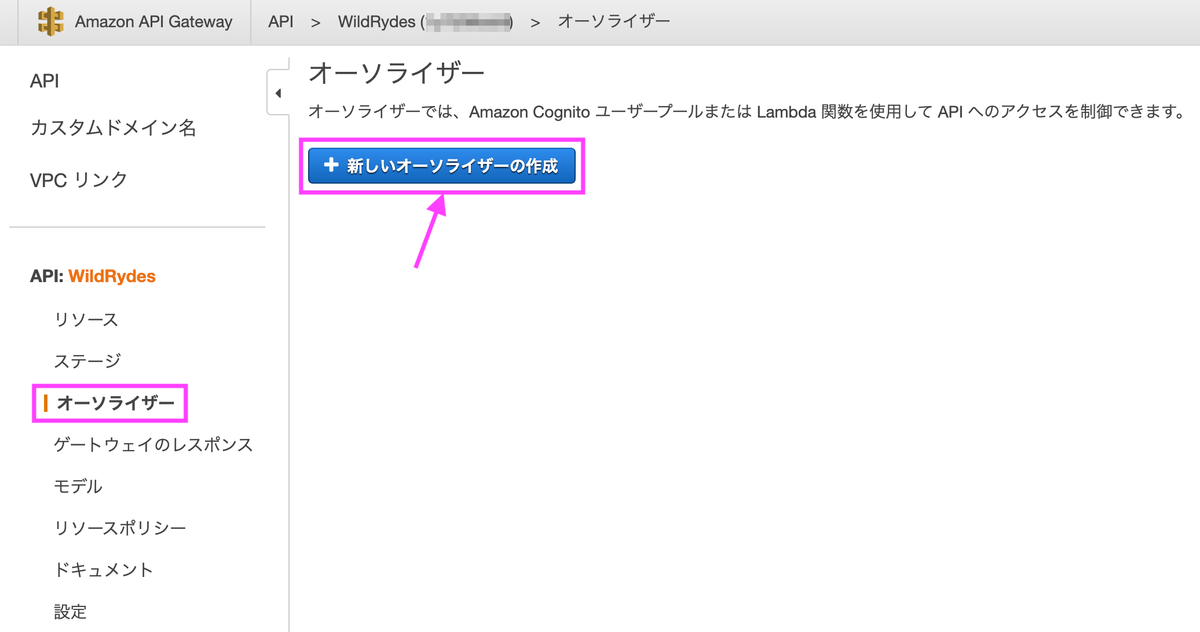
タイプを「Cognito」にし、Cognitoユーザープールは作成したものを選択します。トークンのソースは「Authorization」にします。
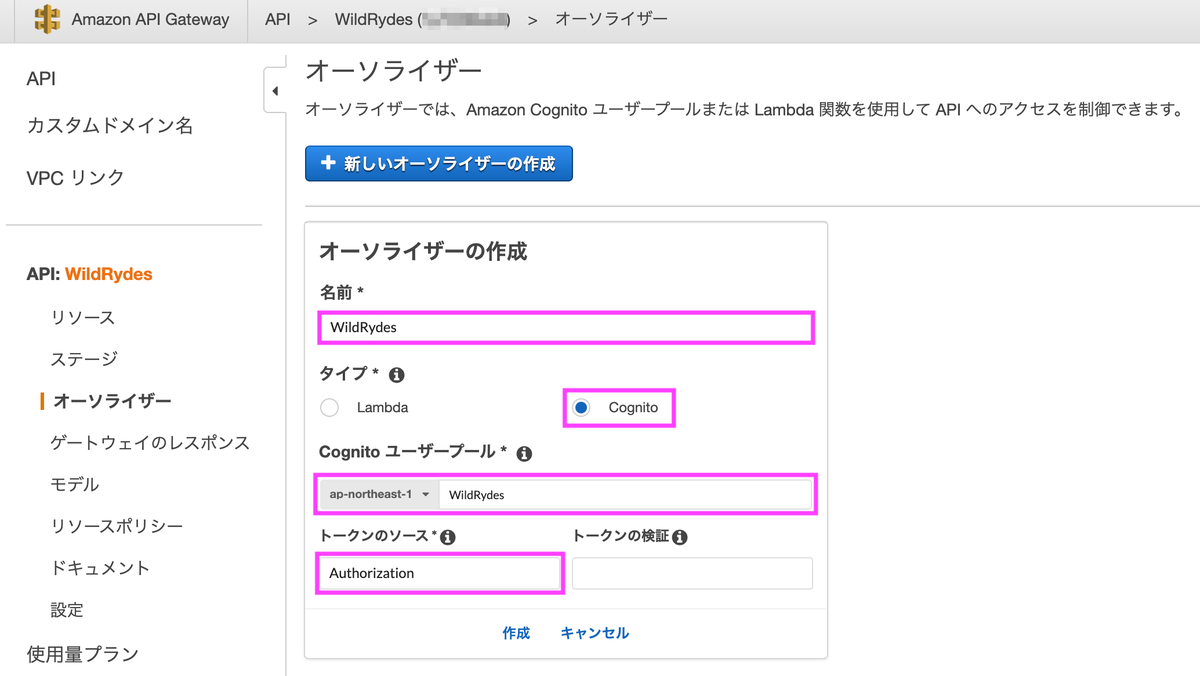
作成後、テストを行います。
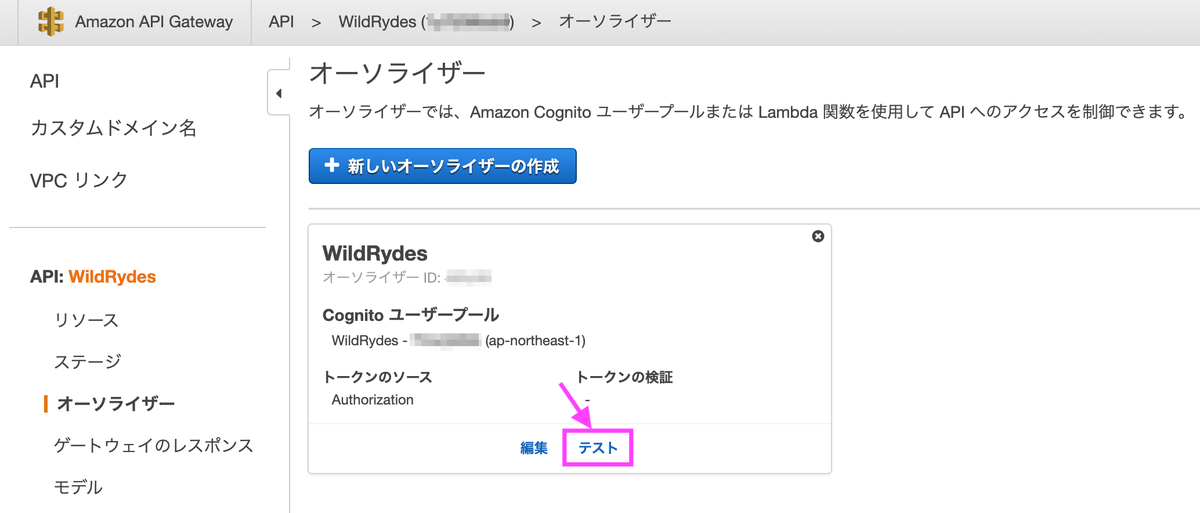
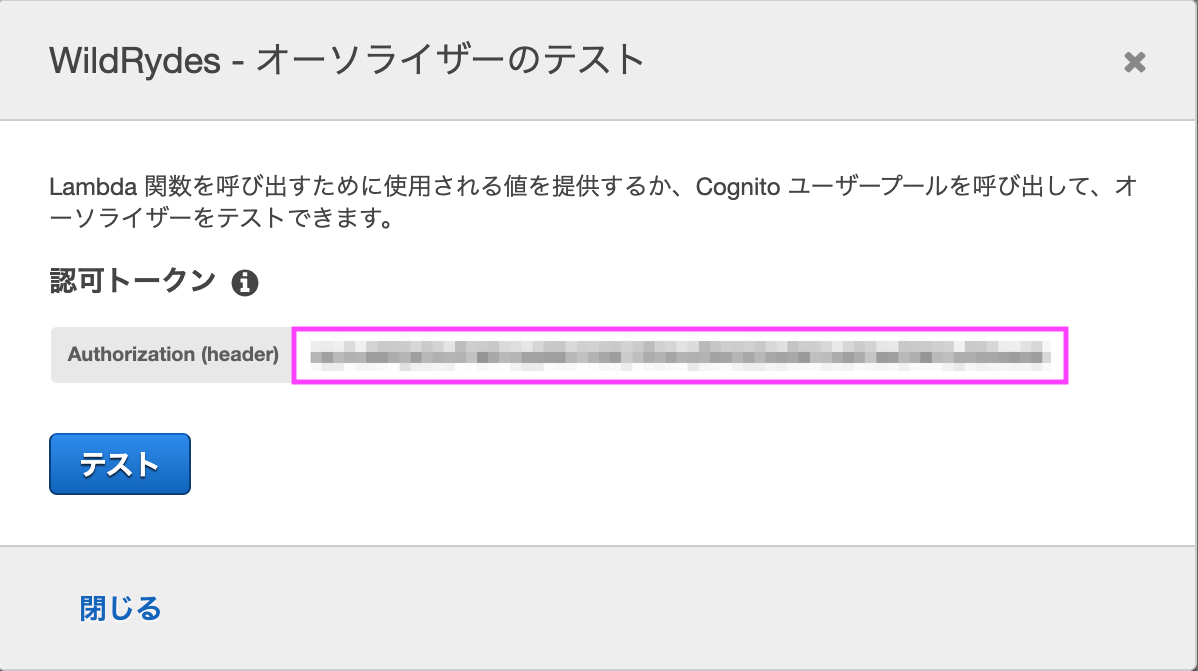
ブラウザからAmplifyで作成したページに飛び、/ride.htmlにアクセスします。認証を行うとトークンが表示されるのでコピーします。

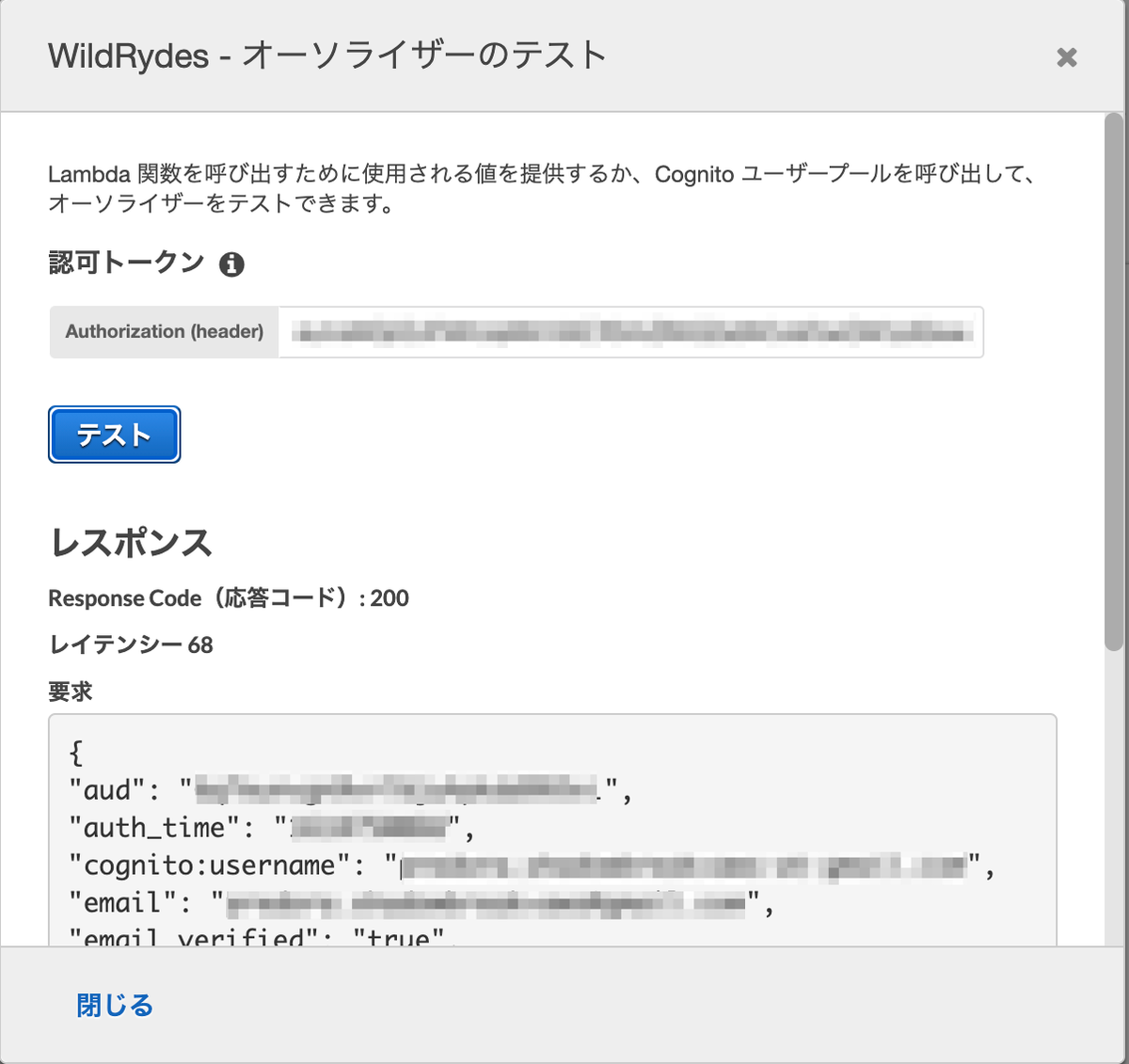
テストが成功すると、Response Code: 200が返ってきます。
[6-3] POSTメソッド追加
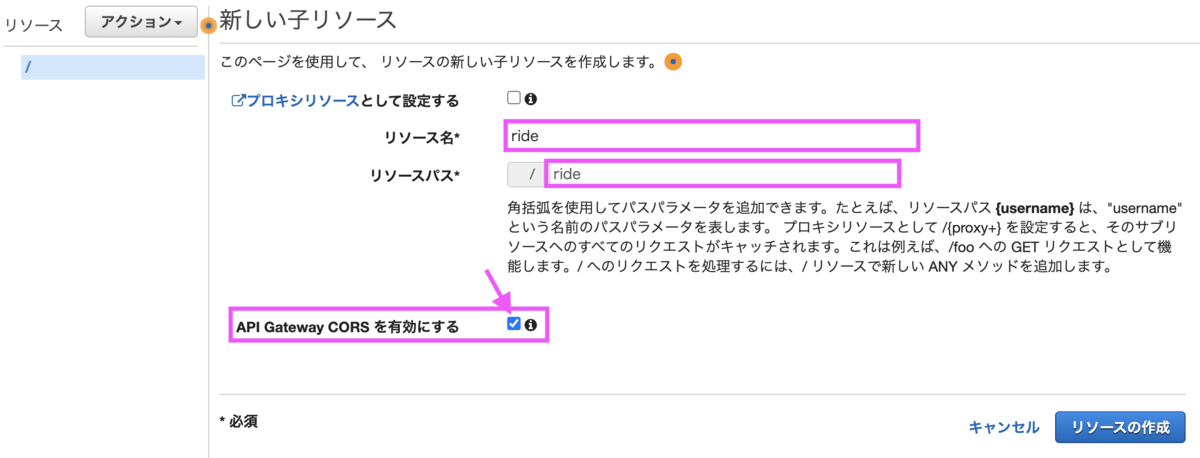
[リソースの作成]を選択し、まずはrideリソースを作成します。

名前は「ride」とし「API Gateway CORSを有効にする」にチェックを付けます。
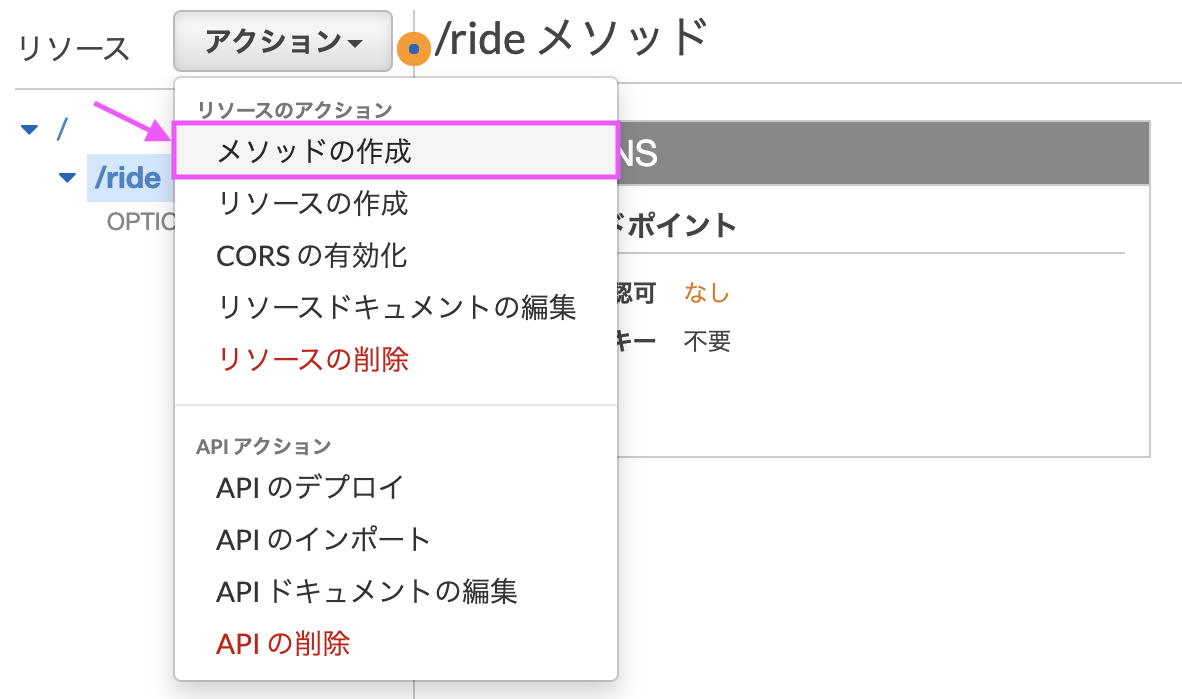
[メソッドの作成]を選択し、rideリソースにPOSTメソッドに追加します。
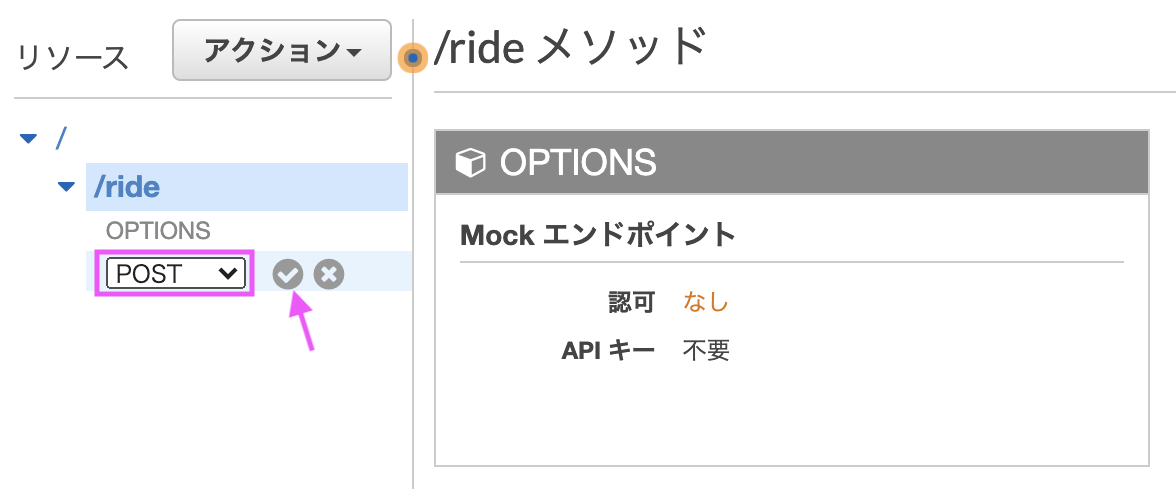
POSTを選択しチェックマークをクリックします。
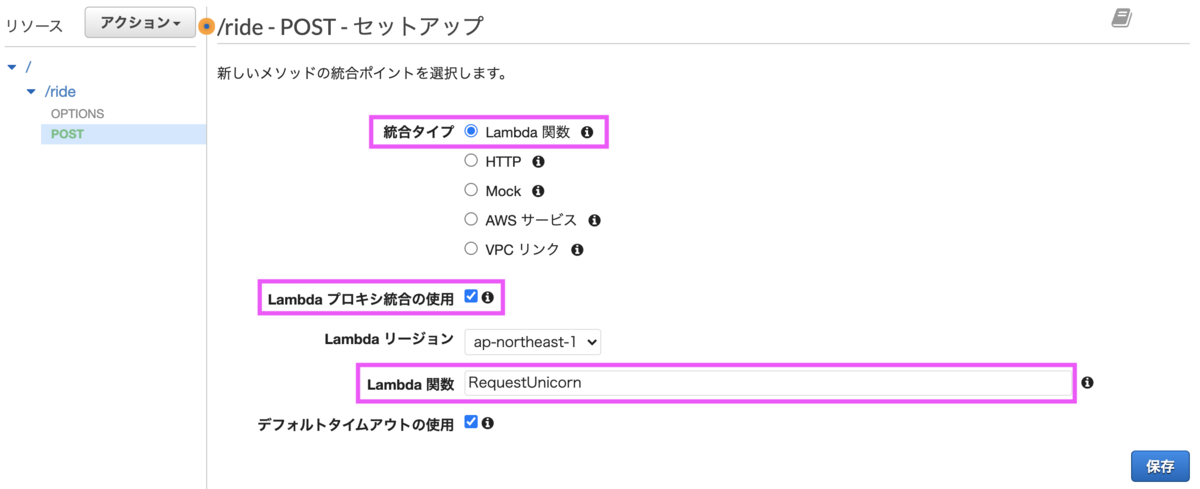
統合タイプは「Lambda関数」にし、「Lambdaプロキシ統合の使用」にチェックします。Lambda関数は先程作成した関数の名称を入力します。
Lambda関数に権限を追加してよいか確認ダイアログが表示されるので[OK]をクリックします。
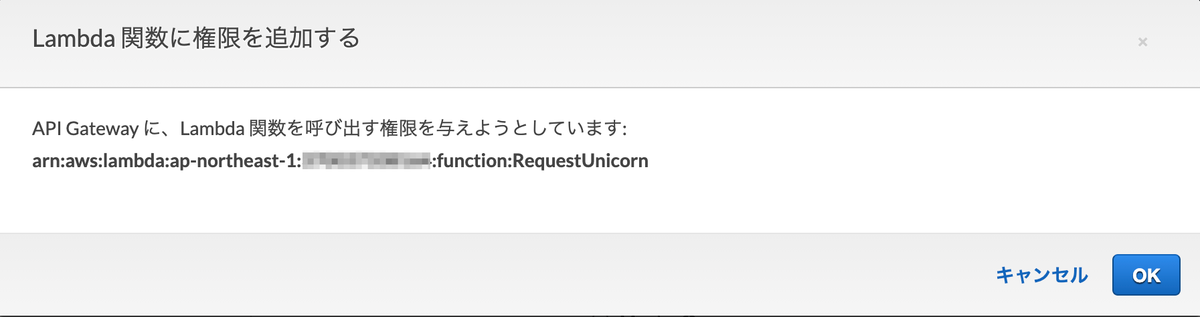
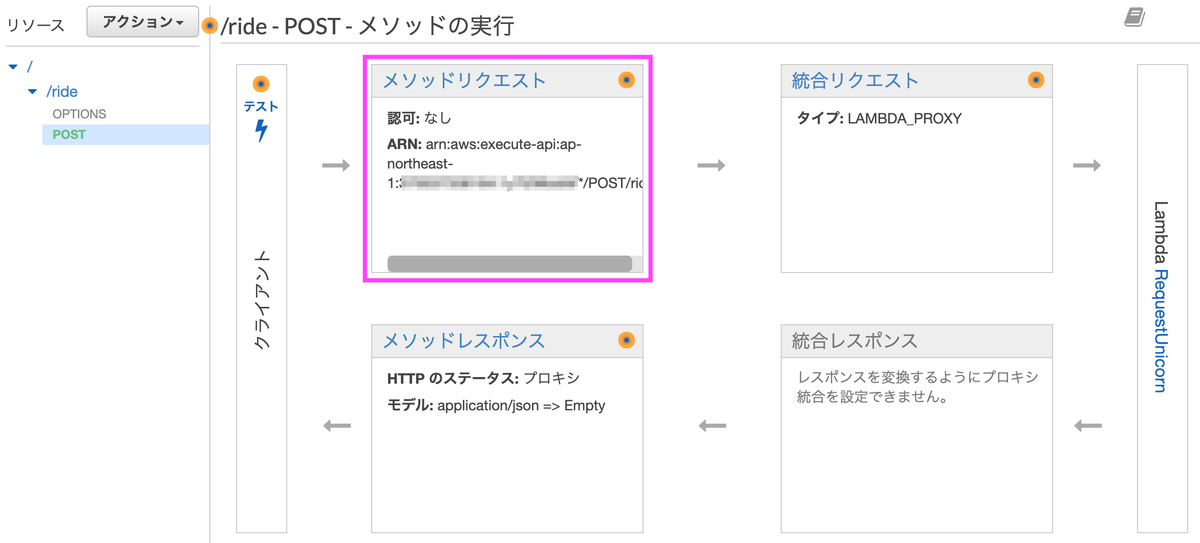
[メソッドリクエスト]を選択します。
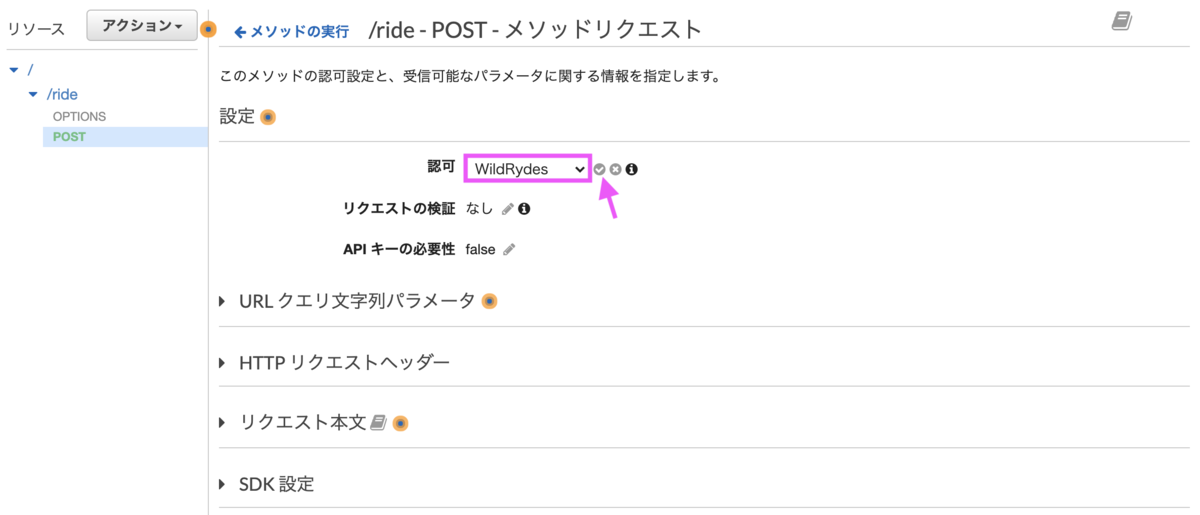
認可横の鉛筆マークを選択するとコンボボックスが表示されるので、Cognitoで追加したオーソライザー「WildRydes」を選択します。

[6-4] APIをデプロイ
アクションから[APIのデプロイ]を選択します。

「新しいステージ」を選択し、ステージ名を「prod」とします。
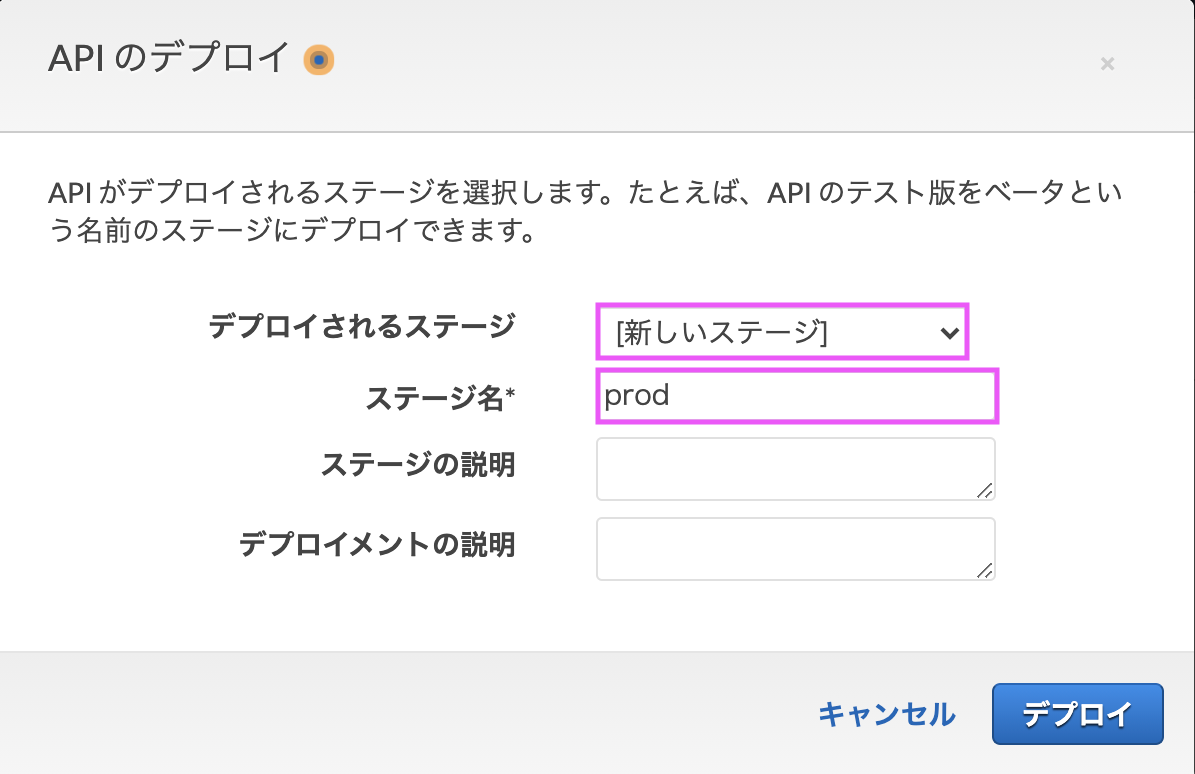
URLが表示されるので、この後ウェブサイトの設定ファイルに反映します。

[6-5] ウェブサイトの設定更新
js/config.jsを開き「invokeURL」にAPIのURLを設定します。

設定をCodeCommitのリポジトリに反映します。
$ git add js/config.js $ git commit -m "Add invokeUrl to config.js" $ git push
Amplifyの画面でデプロイ・検証が終わったことを確認し、ウェブサイトにアクセスすると地図が表示されます。
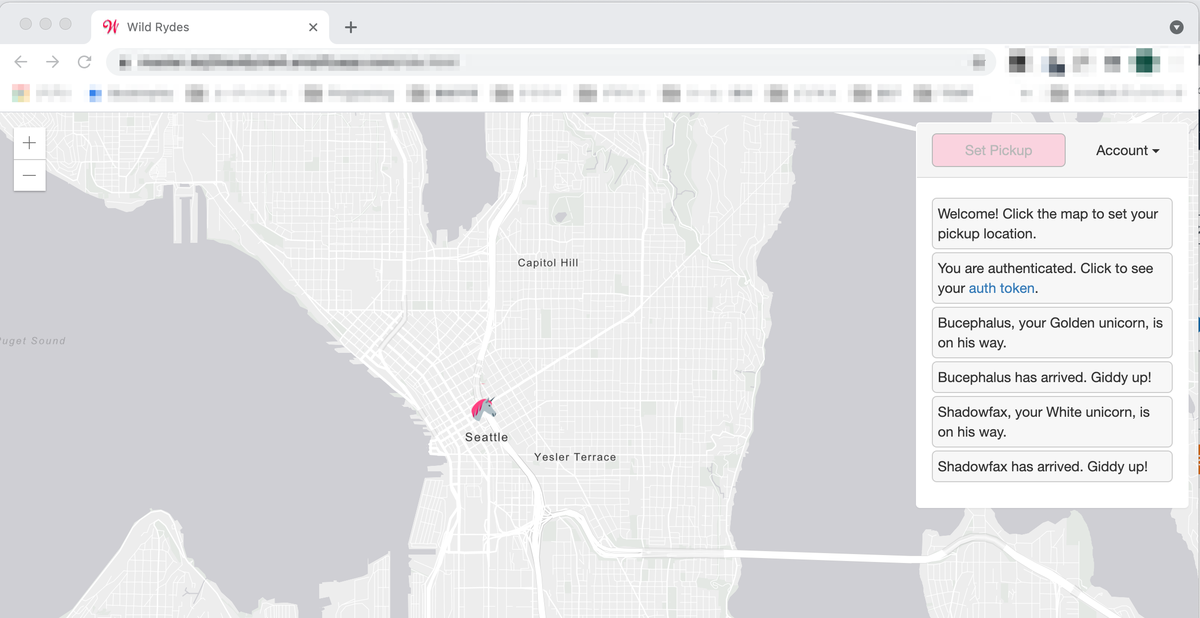
地図上の任意の位置をクリックすると、どこからともなく馬が現れクリックした位置で停止します。
[7] リソースの削除
- Amplify
- Cognitoユーザープール
- Lambda関数
- IAMロール (WildRydesLambda)
- IAMロール(AWSAmplifyExecutionRole〜)
- IAMロール (AWSAmplifyExecutionPolicy〜)
- DynamoDBテーブル
- API Gateway
- CloudWatchロググループ
- CodeCommitリポジトリ
終わりに
分量は多いですが、ハンズオンの説明が分かりやすいこともあり、途中で詰まることなく進められました。AWSの色々なサービスに触れることができ、良いハンズオンでした。
出典
- アイキャッチはGerd AltmannによるPixabayからの画像
「 投資家が「お金」よりも大切にしていること」の感想
お金より大切なものが何かと問われれば人それぞれです。仕事が一番、家族が大事、十人十色でしょう。私は家族、仕事、自分の時間、お金、どれも大事です。
著者は、ひふみ投信で有名なレオス・キャピタルワークス代表取締役社長・最高投資責任者の藤野英人さんです。ひふみ投信は一時不調とも言われていましたが、長期的に見れば運用成績は良い方じゃないでしょうか。
そんな藤野さんが何を大事にしているか、明確にコレとは言っていません。読み進めていけば分かるのですが、上手いタイトルを付けたなと思いました。
内容は、7つの習慣に通じるところがあります。短期的な個人の利益を目指すよりも、協力しあって生きた方が皆が幸せになるよねという主旨です。
発売されたのが2013年であり8年前にはなりますが、当時の日本には色々と問題点があると述べています。端的に言うと、日本人はお金好きでケチなくせにお金について何も考えていない、お金儲けは汚く人任せな人たちだということです。
これを聞いて気を悪くした方もいると思いますが、私は納得できました。私は比較的普通の日本人で、藤野さんの言う日本人の特徴に当てはまるところが多かったです。
じゃあ、どうすればいいのか。行動しよう、最後の最後はエイヤ!です。最後は勢い、気持ちということですね。何かするのには必ずリスクが伴います。失敗する可能性もあるわけです。日本人は特にリスクを恐れる傾向にあります。しかし、リスクがゼロになることなどないので、最後はエイヤで跳んでしまえということです。
本書では藤野さんが大企業や団体名を名指しで批判しています。そんな言っちゃって大丈夫なのと思いもしましたが、はっきり言う姿勢自体は好印象に感じました。これも藤野さんの言うエイヤなのでしょうか。
出典
- アイキャッチはNattanan KanchanapratによるPixabayからの画像
印象に残った内容
- 日本人は金儲けを悪だと思う人が多い
- 日本は金融資産の半分が現金・預金
- 日本人は寄付をしない
- 日本人はお金について何も考えていない
- アメリカのヒーローは民間人、日本のヒーローは公務員
- 日本人は、公のことは国や公務員任せ
- ブラック企業を生み出すのは、より安いものを望む消費者
- 日本人はたくさん働くのに仕事のことが好きではない
NPOやNGOについて私は詳しくありません。なので、以下のフレーズはかなり印象に残りました。