GitHubでパスワード認証が廃止されるので二要素認証とトークン認証の設定方法をまとめた
GitHubのパスワード認証が2021/08/13以降、受け付けなくなるそうです。まだ期限まで時間はありますが、今のうちに対処しておくことにしました。
やることは2点です。
- 二要素認証を有効にする
- トークンを作成する
[1] 二要素認証を有効にする
[1-1] 設定画面へ移動する
GitHubにブラウザでアクセスし[Settings]を選択します。
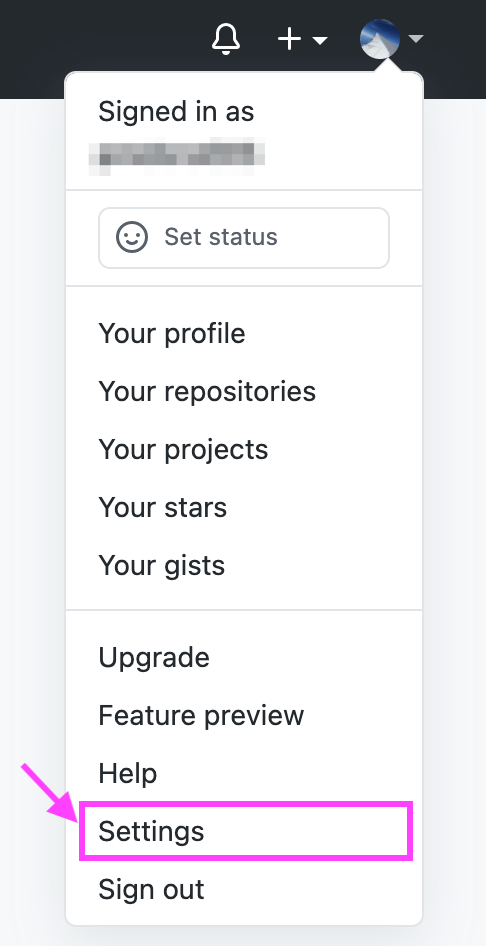
[Account security]を選択します。
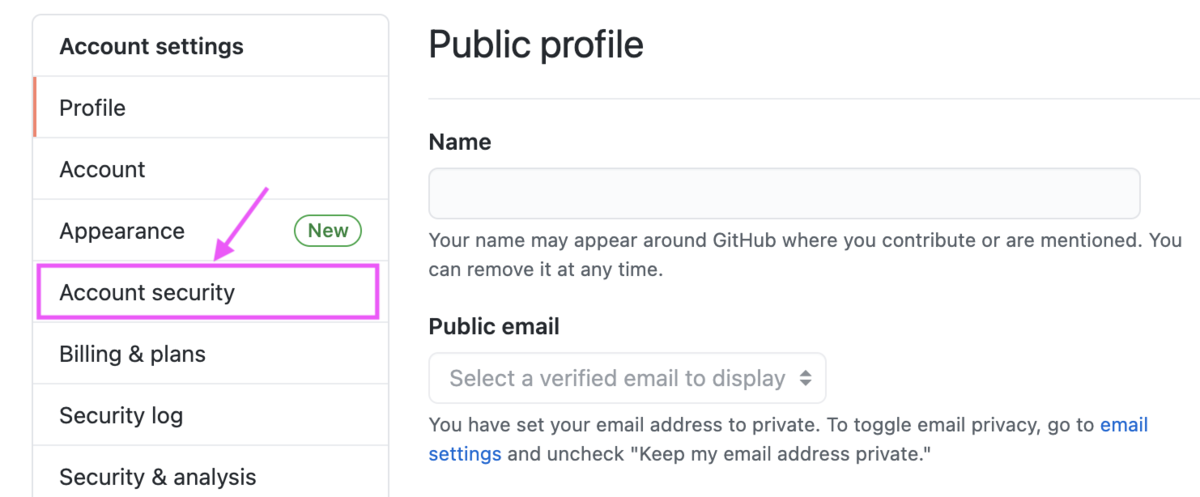
画面中央のTwo-factor authenticationの中から[Enable two-factor authentication]をクリックします。
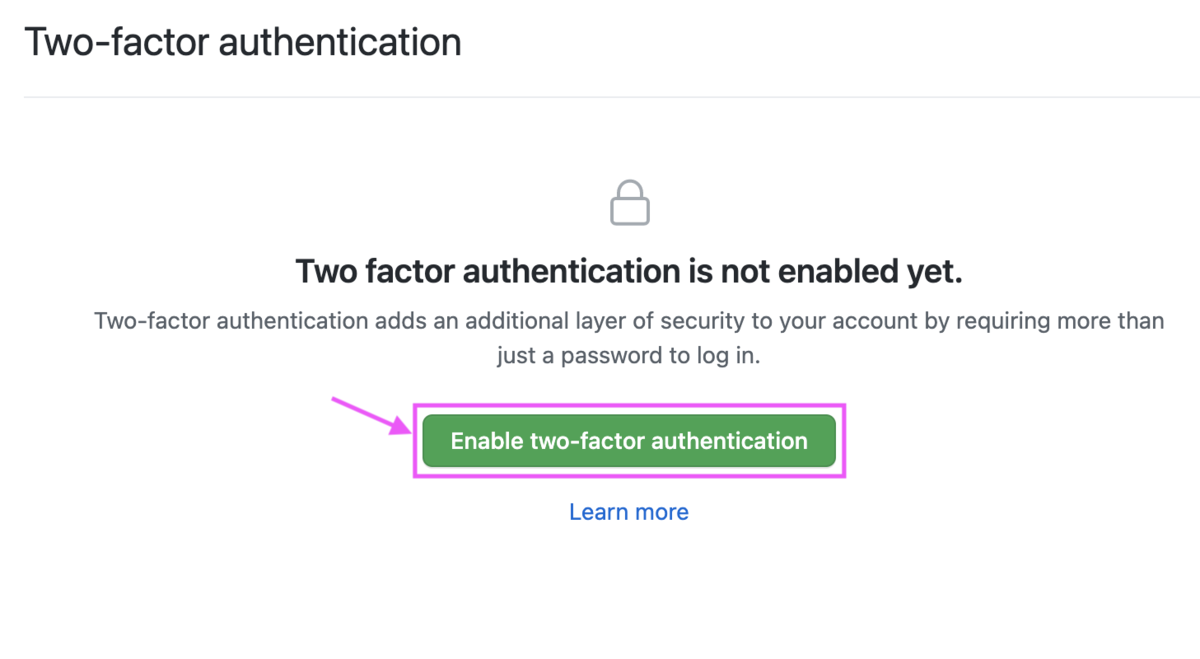
パスワードを入力し、次の画面に進みます。
[1-2] 二要素認証の方法を選択する
続いて、二要素認証の方法を選択します。アプリとSMSの2種類から選択できます。
アプリは、スマホなどのモバイル端末のアプリで認証コードを取得する方法です。私は「Google Authenticator」を使用しています。
SMSは、携帯のショートメッセージに認証コードが送られてくる方法です。
私はアプリの方を選んだので、アプリの設定方法を紹介します。
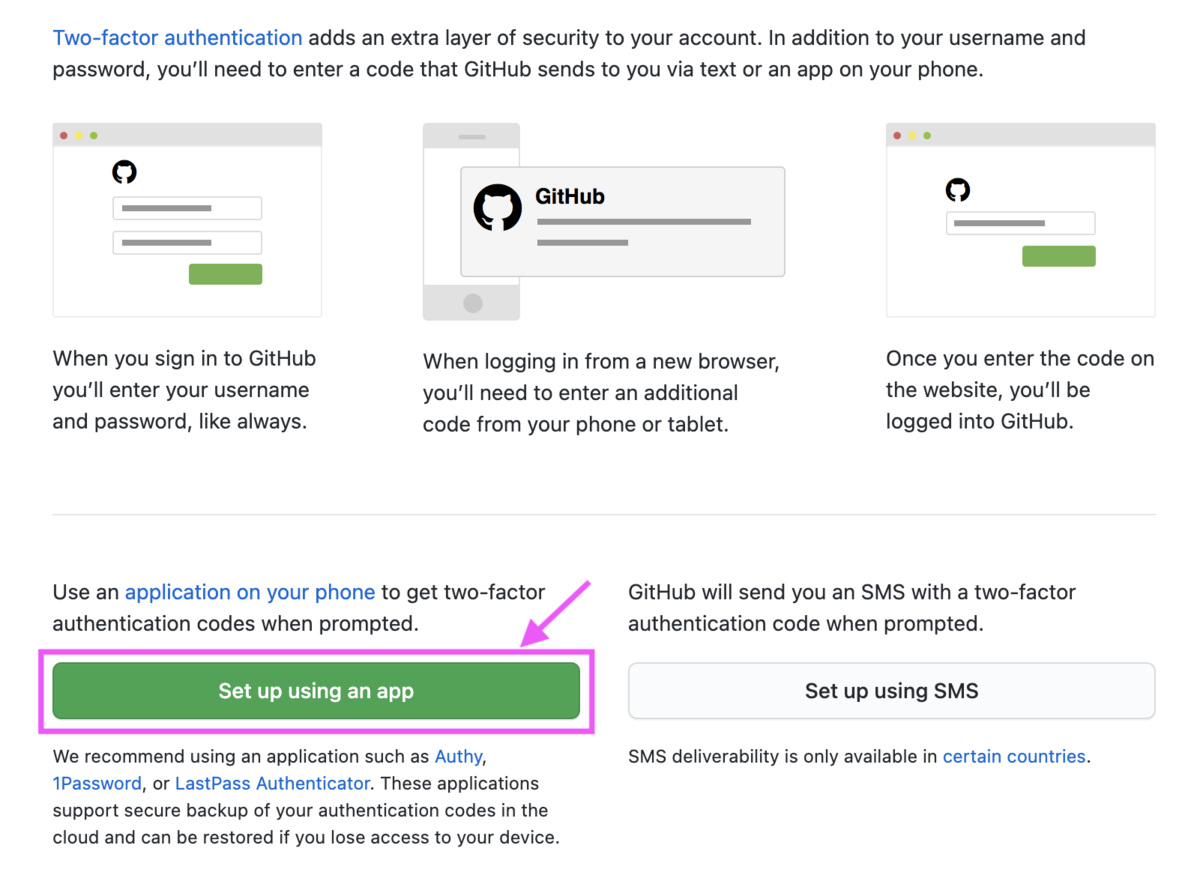
[Set up using an app[を選択すると、リカバリーコードが表示されます。リカバリーコードは二要素認証が行えなくなった場合に使用します。この画面を消すと取得できなくなるので[Download]や[Copy]を用いて保存しておきます。
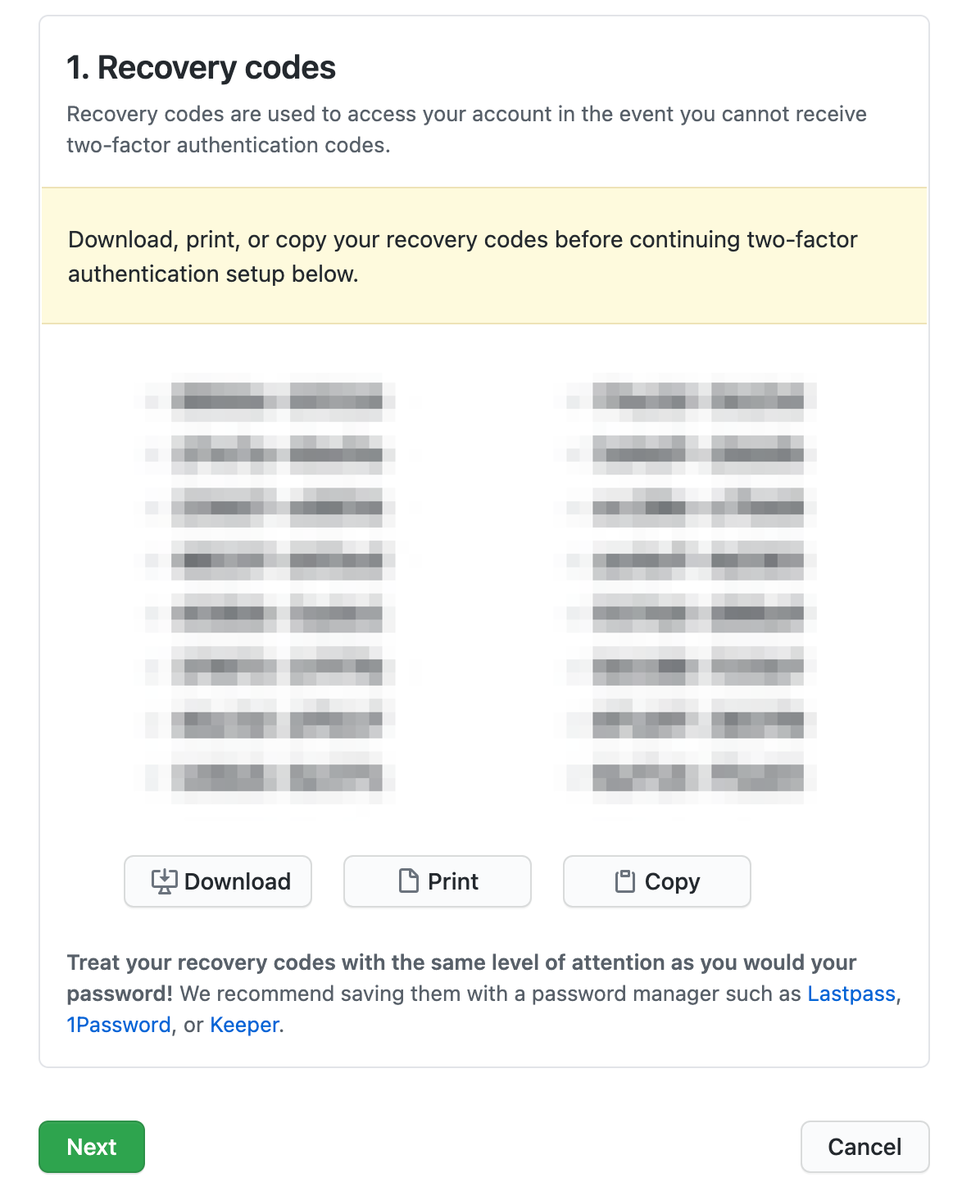
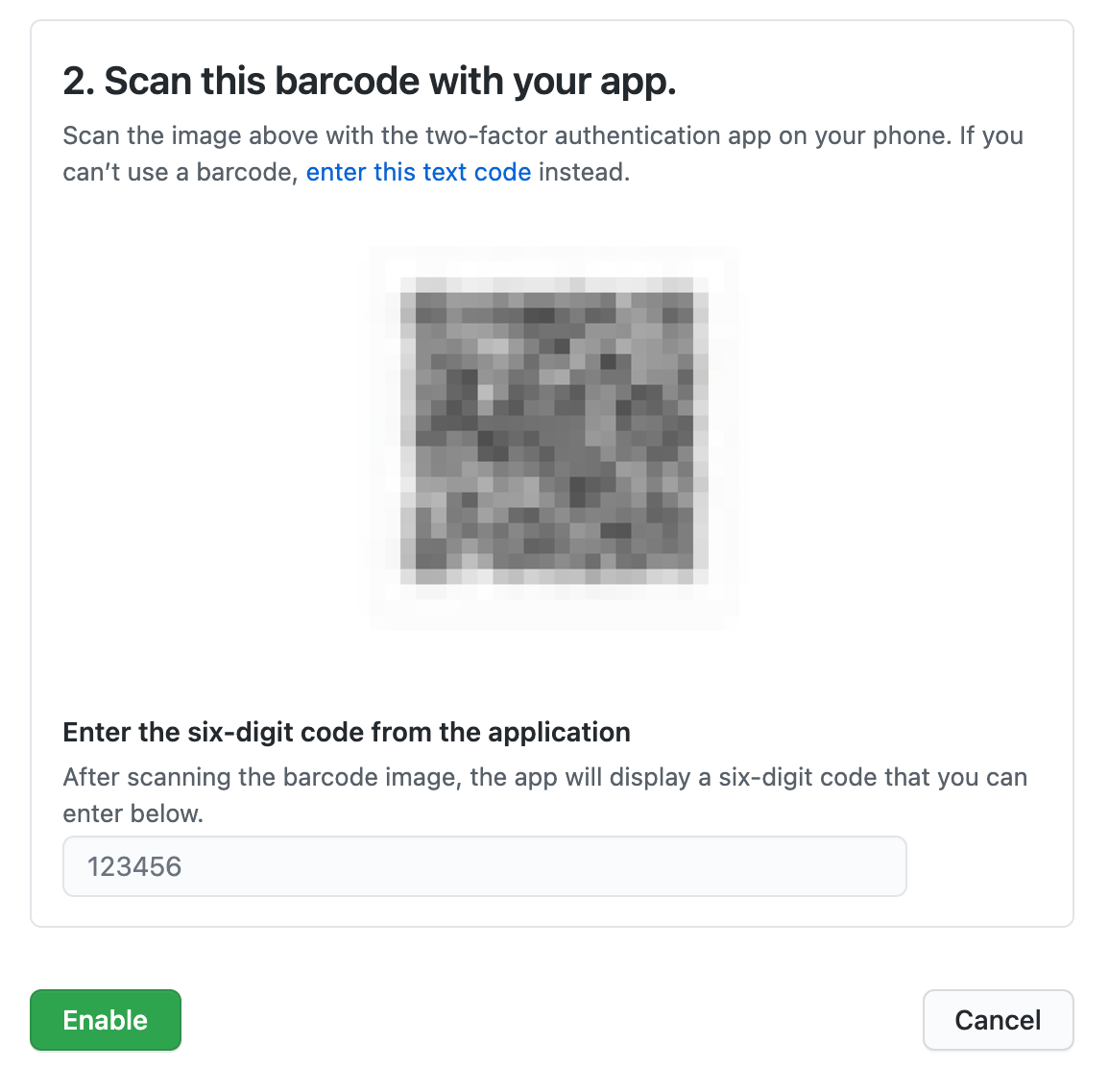
次の画面では、QRコードが表示されます。アプリでQRコードをスキャンして、認証情報をアプリに登録します。登録できたら、アプリに表示された6ケタの認証コードを入力します。入力後[Enable]を押せば、無事に設定完了です。
[2] トークンを作成する
二要素認証と同様にAccount settings画面に移動し、[Developer settings]を選択します。
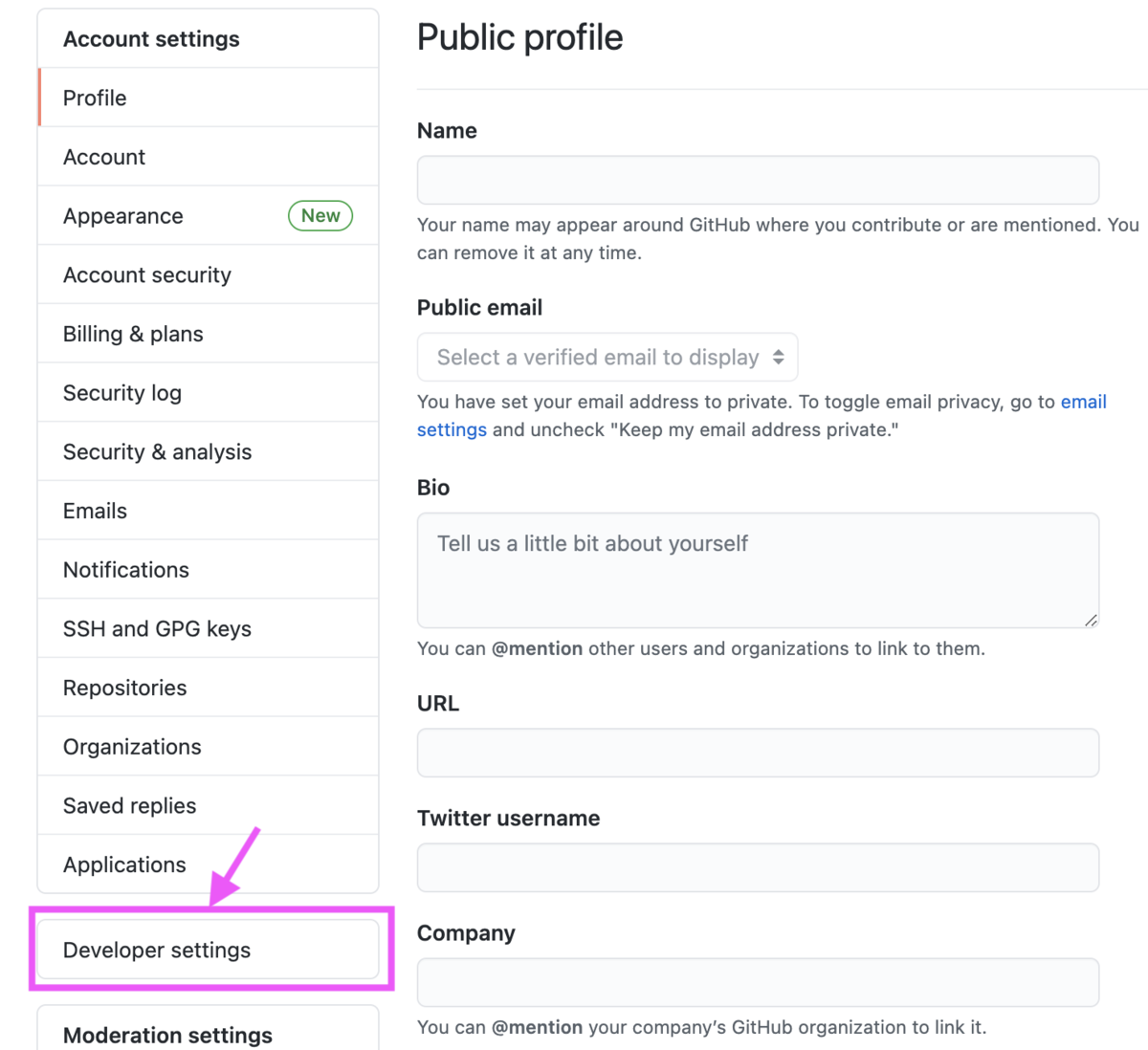
[Personal access tokens]を選択します。
[Generate new token]をクリックします。

[Note]に何に使用するトークンなのかを入力し、[Select scopes]でトークンの適用範囲を選択します。私はリポジトリへのアクセスにのみ使用するため「repo」を選択しました。
次の画面に進むとトークンが表示されます。この画面から移動すると二度とトークンが確認できないので、保存しておきましょう。
[3] 試しにpushしてみる
従来のパスワード認証でpushしてみます。すると、認証エラーで失敗しました。
$ git push Username for 'https://github.com': {アカウント名} Password for 'https://{アカウント名}@github.com': remote: Invalid username or password. fatal: Authentication failed for 'https://github.com/{アカウント名}/{リポジトリ名}/'
続いて、トークン認証を試します。トークン認証ではパスワード欄にトークンを入力します。
$ git push Username for 'https://github.com': {アカウント名} Password for 'https://{アカウント名}@github.com': Enumerating objects: 9, done. Counting objects: 100% (9/9), done. Delta compression using up to 2 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (5/5), 731 bytes | 731.00 KiB/s, done. Total 5 (delta 2), reused 0 (delta 0) remote: Resolving deltas: 100% (2/2), completed with 2 local objects. To https://github.com/{アカウント名}/{リポジトリ名}/ ... (省略) ...
トークン認証で、pushできました。
参考文献
鉄道業界の株価予想(2020年12月)

<鉄道業界の株価予想(2020年12月)>
*1
前回までに行ったスクレイピングで得た情報も取り入れつつ、株価予想をしていきます。
コロナウィルスの影響を大きく受けている鉄道業界の株価予想をします*2。
※ 株式投資はくれぐれも自己責任でお願いします。
[1] 2020年の株価推移
コロナウィルスの影響で株価は大きく下落しています。
特に新幹線事業を行っているJR九州・JR東日本・JR東海・JR西日本の下落幅が大きいです。 それ以外は各社に依りけりです。東急は年初と比較して40%近く下落していますが、他社は最大30%弱の下落幅に留まっています。

[2] JR東日本の状況
JR東日本の決算情報から、新幹線事業を持つ企業の状況を見ていきます。
[2-1] セグメント別の収益
鉄道会社は運輸収入*3だけで稼いでるわけではありません。不動産事業やサービス事業でも稼いでいます。例えば、JR東日本は駅ビル・オフィスビル・ホテルなどの不動産を所持しています。また、アトレやエキュートなどの小売業も積極的に行っています。
コロナウィルスの影響が無い、2019年3月期の決算情報から収益の割合を見てみます。運輸事業が営業収益(売上)・営業利益ともに 70%近くを占めています。

運輸事業の中での内訳を見ると、在来線が6割、新幹線が3割程度です。つまり、JR東日本の収益の40%は在来線、20%は新幹線ということです。

[2-2] 2020年第2四半期の実績
2020年4月〜9月の実績は、営業収益が50%減です。特に新幹線の輸送量は前年度比70%減であり、コロナウィルスの影響が顕著です。不動産事業は前年同期比と比較して30%減、サービス事業は50%減となっています。
2020年通期の純利益は、4,000億円マイナスの予想です。コロナウィルスの影響が軽減されれば業績は戻っていくと思いますが、しばらくは厳しい状況が続きそうです。2020年3月期の純利益が約2,000億円ですから、かなり大きいマイナスです。

[3] 近鉄GHDの状況
続いて、JR系と比較して株価の落込みが小さい、近鉄GHDの決算状況を見ていきます。
近鉄グループホールディングス株式会社|株主・投資家情報|IR資料|決算説明会
[3-1] セグメント別の収益
JR東日本と同様に、コロナウィルスの影響が無い、2019年3月期の決算情報から収益の割合を見てみます。運輸事業が占める比率は、営業収益が17%, 営業利益が49%です。JR東日本の68%, 70%と比較すると、運輸事業への依存度は低いことが分かります。

[3-2] 2020年第2四半期の実績
2020年4月〜9月の実績は、営業収益が54%減です。2020年通期の純利益は、310億円マイナスの予想です。50%減収という点は、JR東日本と変わりません。

セグメント別の営業収益を見ると、運輸が40%減、不動産が20%、流通が25%減、ホテル・レジャーが90%減です。
運輸の影響はJR東日本と比べて小さいのですが、ホテル・レジャーの減益がかなり大きいと予想されています。ホテル・レジャーの営業利益は360億円のマイナス予想になっています。
[4] 2016年からの株価推移
2016年1月4日の株価を基準とした、株価の上昇率はグラフの通りです。
全体的にみると、2020年初頭までは20%程度上昇し、2020年に入ってから大きく下落しています。
2016年1月から2020年1月までの間に、TOPIXは20%近く上昇しました。 TOPIXと同じ上昇率なので、鉄道業界が目立って浮き沈みはしていないと言えます。

[5] 鉄道輸送量の推移
政府の統計ページ e-Statより、鉄道輸送量の年度別推移を見てみます。緩やかに上昇していましたが、2019年度に減少に転じています。日本の人口は減少し続けているので、今後大きく増えていくことは期待できません。緩やかに減少していくでしょう。

鉄道業界の主な収益は運輸収入です。輸送量が減れば運輸収入も減りますので、鉄道業界が大きく成長することは見込めないわけです。成長するとしたら別セグメントが成長するか海外展開でしょう。
[6] 今後の株価予想
しばらくは低調な状態が続きそうです。本格的に回復するのは、コロナウィルスのワクチン接種が始まってからでしょう。
JR系と民鉄で比較すると、民鉄の方が低迷が続くと思います。ホテル・レジャー事業のマイナスが大きいからです。数年間は国内旅行の減少、インバウンドの減少は戻らないと予想しています。
一方、JR系はコロナウィルスの影響が落ち着けば、運輸収入はだいぶ戻るでしょう。株価も元に戻っていくと予想できます。ただし、今後大きな成長が見込める業界ではありません。株価が上昇するとしても、日経平均やTOPIXと近い上昇率で推移すると思われます。
【AWS】t4gでnumpy, pandas, matplotlibをインストールする方法
AWSのArmベースインスタンスのt4g.micro、2021年3月31日まで無料トライアル中です。無料で使えるやったと思っていたら思わぬところで引っかかりました。
- [0] 前提条件
- [1] numpyのインストールに失敗する
- [2] numpyのインストールに時間がかかる
- [3] pandasがout of memoryでインストールできない
- [4] matplotlibのインストールに失敗する
- 終わりに
[0] 前提条件
OSはAmazon Linux2、python3とpip3はインストール済みです。
$ python3 -V Python 3.7.9 $ pip3 -V pip 9.0.3 from /usr/lib/python3.7/site-packages (python 3.7)
[1] numpyのインストールに失敗する
$ pip3 install numpy --user ... ModuleNotFoundError: No module named 'Cython' ...
Cythonが無いと怒られます。対処法はcythonのインストールです。
$ pip3 install cython --user
[2] numpyのインストールに時間がかかる
理由は、ソースをビルドしているからです。
$ pip3 install numpy --user Collecting numpy Using cached https://files.pythonhosted.org/packages/51/60/3f0fe5b7675a461d96b9d6729beecd3532565743278a9c3fe6dd09697fa7/numpy-1.19.5.zip Installing collected packages: numpy Running setup.py install for numpy ... done Successfully installed numpy-1.19.5
また、t4g.microのスペックはvCPU=2、メモリ=1(GiB)と決して高くないため、より時間がかかります。
[3] pandasがout of memoryでインストールできない
pandasもnumpyと同様に、ソースをビルドしてインストールしようとします。
pip3 install pandas --user Collecting pandas Downloading https://files.pythonhosted.org/packages/11/1c/b0bc154996617eae877ff267fcf84e55e6c6808dbade0da206f0419dd483/pandas-1.2.1.tar.gz (5.5MB) 100% |████████████████████████████████| 5.5MB 273kB/s ... Running setup.py install for pandas ... error ... as: out of memory allocating 4064 bytes after a total of 163106816 bytes ...
t4g.microのメモリ=1(GiB)では、pandasをソースからビルドするのには足らなかったようです。
有効な対応策が見つからなかったため、t4g.smallでビルドしました。
[4] matplotlibのインストールに失敗する
matplotlibに必要な「kiwisolver」のインストールに失敗します。
$ pip3 install matplotlib --user Collecting matplotlib Downloading https://files.pythonhosted.org/packages/7b/b3/7c48f648bf83f39d4385e0169d1b68218b838e185047f7f613b1cfc57947/matplotlib-3.3.3.tar.gz (37.9MB) 100% |████████████████████████████████| 37.9MB 39kB/s Collecting cycler>=0.10 (from matplotlib) Downloading https://files.pythonhosted.org/packages/f7/d2/e07d3ebb2bd7af696440ce7e754c59dd546ffe1bbe732c8ab68b9c834e61/cycler-0.10.0-py2.py3-none-any.whl Collecting kiwisolver>=1.0.1 (from matplotlib) Downloading https://files.pythonhosted.org/packages/90/55/399ab9f2e171047d28933ae4b686d9382d17e6c09a01bead4a6f6b5038f4/kiwisolver-1.3.1.tar.gz (53kB) 100% |████████████████████████████████| 61kB 13.0MB/s ... ValueError: bad marshal data (unknown type code) During handling of the above exception, another exception occurred: ... Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-7wgyhm4y/kiwisolver/
対応策は、pipを最新にすることです。
$ sudo pip3 install -U pip WARNING: Running pip install with root privileges is generally not a good idea. Try `pip3 install --user` instead. Collecting pip Downloading https://files.pythonhosted.org/packages/de/47/58b9f3e6f611dfd17fb8bd9ed3e6f93b7ee662fb85bdfee3565e8979ddf7/pip-21.0-py3-none-any.whl (1.5MB) 100% |████████████████████████████████| 1.5MB 916kB/s Installing collected packages: pip Found existing installation: pip 9.0.3 Uninstalling pip-9.0.3: Successfully uninstalled pip-9.0.3 Successfully installed pip-21.0 $ source ~/.bash_profile
終わりに
最終的には無事解決できましたが、意外なところでハマってしまいました。
日本株の株価をpythonでスクレイピングを使って取得しmatplotlibで可視化する(複数銘柄)
前回の続きです。前回は単一銘柄の株価をスクレイピングで取得しmatplotlibで可視化しました。今回は複数銘柄の株価を取得し比較していきます。

[1] 複数銘柄の株価取得
get_stock_price, astype_stock_price, add_moving_average_stock_priceは前回のソースコードを関数化したものです。各銘柄に対してスクレイピングを行い、取得した結果をDataFrameの末尾に結合していきます。
import time import pandas as pd codes = { 'JR東日本': 9020, 'JR西日本': 9021 } start_year, end_year = 2019, 2020 df = None for name in codes.keys(): # 指定した証券コードの決算情報を取得する。 code = codes[name] df_tmp = get_stock_price(code, start_year, end_year) # 株価情報のデータタイプを修正する df_tmp = astype_stock_price(df) # 株価情報に移動平均を追加する df = add_moving_average_stock_price(df) # 銘柄名を追加し、MultiIndexにする。 df_tmp['銘柄'] = name df_tmp = df_tmp.set_index('銘柄', append=True) # 2回目以降は既存のDataFrameの末尾にデータを追加 if df is None: df = df_tmp else: df = df_tmp.append(df) # 1秒ディレイ time.sleep(1) # indexを入れ替える df = df.swaplevel('銘柄', '日付').sort_index()
結果、次のデータが得られました。
| 始値 | 高値 | 安値 | 終値 | 出来高 | 終値調整 | 5日移動平均 | 25日移動平均 | 75日移動平均 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 銘柄 | 日付 | |||||||||
| JR東日本 | 2019-01-04 | 9675.0 | 9820.0 | 9627.0 | 9731.0 | 1337200.0 | 9731.0 | NaN | NaN | NaN |
| 2019-01-07 | 9918.0 | 10065.0 | 9915.0 | 10030.0 | 887500.0 | 10030.0 | NaN | NaN | NaN | |
| ... | ... | ... | ... | ... | ... | |||||
| JR西日本 | 2020-12-03 | 5085.0 | 5249.0 | 5077.0 | 5233.0 | 1869000.0 | 5233.0 | 4986.8 | 4907.92 | 5172.11 |
| 2020-12-04 | 5299.0 | 5414.0 | 5257.0 | 5317.0 | 1745900.0 | 5317.0 | 5038.2 | 4932.32 | 5173.95 |
[2] 可視化
[2-1] 2020年以降のデータを抽出
DataFrameをMultiIndexしたことにより、日付による抽出方法が少し変わっています。pd.IndexSliceを用いて抽出します。
# 2020/01/01以降のデータを抽出 df = df.loc[pd.IndexSlice[:, '2020-01-01':], :] # (前回) df = df['2020-01-01':]
下記記事を参考にさせてもらいました。
pandasのMultiIndexから任意の行・列を選択、抽出 | note.nkmk.me
[2-2] 株価の可視化
まずは、終値をそのまま折れ線グラフで可視化してみます。抽出したデータを折れ線グラフで可視化します。
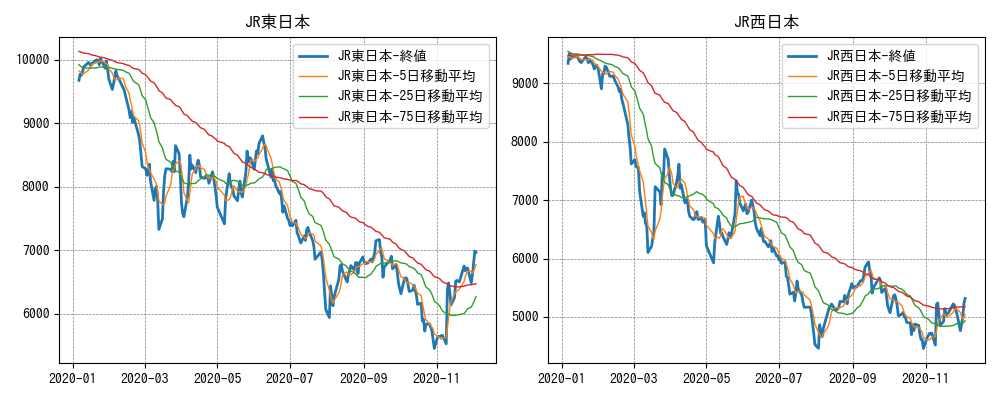
# Figureを取得 fig = plt.figure(figsize=(10, 4)) # 銘柄名のリスト取得 brand_names = list(df.index.unique('銘柄')) # 銘柄別に折れ線グラフで表示する for i, brand_name in enumerate(brand_names): # Axesを取得 ax = fig.add_subplot(1, 2, i+1) # 表示するデータを抽出 df_brand = df.loc[brand_name,] x = df_brand.index # 日付 y = df_brand['終値'] # 折れ線グラフ表示 label = '{0:s}-終値'.format(brand_name) ax.plot(x, y, label=label, linewidth=2.0) # 移動平均の折れ線グラフを追加 average_columns = ['5日移動平均', '25日移動平均', '75日移動平均'] for column in average_columns: x = df_brand.index # 日付 y = df_brand[column] # 移動平均 label = '{0:s}-{1:s}'.format(brand_name, column) ax.plot(x, y, label=label, linewidth=1.0) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # グラフのタイトルを追加 ax.set_title(brand_name) # 不要な余白を削る plt.tight_layout() # グラフを表示 fig.show()
[2-3] 値上がり率の可視化
株価は発行済株数によって変わるので単純比較はできません。そこで、ある日付を基準とした値上がり率で比較してみます。
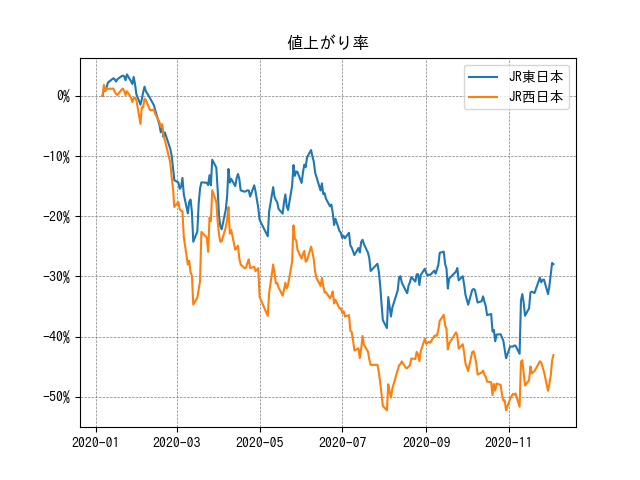
2020/01/06を基準とした比率で言うと、JR西日本の方が株価が大きく下落しています。
# 基準日を設定 ref_date = datetime.date(2020, 1, 6) ref_date_str = ref_date.strftime('%04Y-%02m-%02d') # FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(1,1,1) # 銘柄別に値上がり率を計算 for brand_name in brand_names: # 指定銘柄のデータを取得 df_brand = df.loc[brand_name,] # 値上がり率を計算 base_price = df_brand.loc[ref_date_str,'終値'] # 基準日の終値 rate = df_brand['終値'] / base_price - 1 # 値上がり率 # 表示するデータを抽出 x = df_brand.index # 日付 y = rate # 折れ線グラフを表示 ax.plot(x, y, label=brand_name) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # Y軸の単位をパーセント表示に設定 ax.yaxis.set_major_formatter(mpl.ticker.PercentFormatter(1)) # グラフのタイトルを追加 ax.set_title('値上がり率') # グラフを表示 fig.show()
期間をもう少し長く取ると、JR西日本は2019年〜2020年にわたって株価が大きく上昇していました。そのため、2020年の下落幅も大きかったことがわかります。

[2-4] 株式分割に注意
株式分割等で株価が急激に変わった場合は補正が必要です。例えば、株価¥10,000だった銘柄が株式分割で1株を10株に分割すると、株価は¥1,000になります。
株価は10分の1になりますが、1株あたりの価値は変わりません。この場合、株式分割後の株価を10倍にする補正が必要でしょう。
[2-5] 補足: DataFrameに値上がり率を追加
ちなみに、元のDataFrameに値上がり率を追加するためには以下のようにします。
# 値上がり率の列を用意 df['値上がり率'] = np.nan for brand_name in brand_names: ...(中略)... # 値上がり率をDataFrameに追加 # (rateはSeries. そのまま代入するとindexが合わないためNG) df.loc[(brand_name, ), '値上がり率'] = rate.values
終わりに
株価をスクレイピングで取得し、複数銘柄間の比較を行ました。上記では'JR東日本'と'JR西日本'の2銘柄のみ扱いましたが、銘柄数を増やすことは用意です。いちど仕組みを作ってしまえば応用することは難しくありません。

そもそもスクレイピングを始めた目的は、株式投資のために企業分析を行うことでした。より詳しい分析を行うためには各企業の決算情報なども見ないと足りないなと感じました。
ただ、今回行ったことは分析の取っ掛かりとしては悪くありませんでした。その業界全体の傾向を見る場合や、その業界のなかで他と値動きが異なる企業を探す場合に活用できそうです。
[補足]
[補足1] get_stock_pricesのソースコード
def get_stock_price(code, start_year, end_year): whole_df = None headers = None # 指定した年数分の株価を取得する years = range(start_year, end_year+1) for year in years: # 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html_headers ={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} html = requests.get(url, headers=html_headers) # BeautifulSoupのHTMLパーサーを生成 bs = BeautifulSoup(html.content, "html.parser") # <table>要素を取得 table = bs.find('table') # <table>要素内のヘッダ情報を取得する。 if headers is None: headers = [] thead_th = table.find('thead').find_all('th') for th in thead_th: headers.append(th.text) # <tr>要素のデータを取得する。 rows = [] tr_all = table.find_all('tr') for i, tr in enumerate(tr_all): # 最初の行は<thead>要素なので飛ばす if i==0: continue # <tr>要素内の<td>要素を取得する。 row = [] td_all = tr.find_all('td') for td in td_all: row.append(td.text) # 1行のデータをリストに追加 rows.append(row) # DataFrameを生成する df = pd.DataFrame(rows, columns=headers) # DataFrameを結合する if whole_df is None: whole_df = df else: whole_df = pd.concat([whole_df, df]) # 1秒ディレイ time.sleep(1) return whole_df
[補足2] astype_stock_priceのソースコード
def astype_stock_price(df): # 列とデータ型の組み合わせを設定 dtypes = {} for column in df.columns: if column == '日付': dtypes[column] = 'datetime64' else: dtypes[column] ='float64' # データ型を変換 new_df = df.astype(dtypes) # インデックスを日付に変更 new_df = new_df.set_index('日付') return new_df
[補足3] add_moving_average_stock_priceのソースコード
def add_moving_average_stock_price(df): df['5日移動平均'] = df['終値'].rolling(window=5).mean() df['25日移動平均'] = df['終値'].rolling(window=25).mean() df['75日移動平均'] = df['終値'].rolling(window=75).mean() return df
出典
- アイキャッチはGerd AltmannによるPixabayからの画像
【AWS】ArmベースのEC2インスタンスt4gとt3のスペック・料金比較
昨年9月からArmベースのt4gインスタンスが利用可能になりました。同じく汎用インスタンスであるt3インスタンスはIntelベースです。
昨年はAppleのM1チップや、WindowsのCPU自社設計など大きな話題がありましたが、いずれもArmベースです。Armはすでにスマホ用CPUでシェアを握っていますが、PC向けでも勢力を拡大しつつありますね。
料金とスペック
Intelベースのt3, AMDベースのt3a, Armベースのt4の性能面を比較していきます。
お試しでよく使われる「micro」で比較します。価格は東京リージョンのものです。
| インスタンスサイズ | 価格(東京リージョン) | vCPU | メモリ (GiB) | ベースラインパフォーマンス/vCPU | CPU クレジット取得/時間 | ネットワークバースト幅 (Gbps) | EBS バースト幅 (Mbps) |
|---|---|---|---|---|---|---|---|
| t4g.micro | 0.0108USD/時間 | 2 | 1 | 10% | 12 | 最大 5 | 最大 2,085 |
| t3.micro | 0.0136USD/時間 | 2 | 1 | 10% | 12 | 最大 5 | 最大 2,085 |
| t3a.micro | 0.0122USD/時間 | 2 | 1 | 10% | 12 | 最大 5 | 最大 2,085 |
スペックは同じで価格が異なります。t4gとt3を比較すると、t4gの方が20%安いです。
micro以外も確認しましたが、microと同様にスペックは同じで20%安いという結果でした。micro以外の性能を見たい方は公式を参照してください。
Amazon EC2 T4g Instances - Amazon Web Services
t4g以外のArmベースインスタンス
t4g以外にもArmベースのインスタンスは存在します。a1, m6g, c6g, r6gです。
a1はArmベースのインスタンスの中では古い部類だったと記憶しています。なので、t4g, m6g, c6g, r6gで使い分けるのがよいと思います。
- お試し用途、バーストが必要ならt4g
- 汎用でバースト不要ならm6g
- 高性能CPUが必要ならc6g
- メモリ容量が必要ならr6g
t4.microは2021年末まで無料トライアル中
t4.microは750時間/月まで無料で利用できます。t3からの移行を試すには非常にありがたいです。
Amazon EC2 T4g Instances - Amazon Web Services
注意点
t3を始めとしたIntel系(x86)のインスタンスと、ライブラリのインストール方法が異なる場合があります。ソースからビルドしてインストールが必要な場合もあります。
numpy, pandas, matplotlibのインストール手順は下記記事にまとめています。
終わりに
Armは昨年、ソフトバンクからNVIDIAに売却されることで話題になりましたね。Armは業績が伸び悩んでいると言われていますが、今後どうなっていくのか楽しみです。
参考資料
下記記事はOpenSSLで実際の性能を測定しており面白い記事でした。
ARMベースのCPUをバースト利用できる「T4g」インスタンスの性能をOpenSSLで測定してみた | DevelopersIO
日本株の株価をpythonでスクレイピングを使って取得しmatplotlibで可視化する(単一銘柄)
過去数年分の株価をスクレイピングで取得して可視化する手順を紹介します。最終的に以下のようなグラフを作成します。

各銘柄の時価総額や決算情報を取得する手順や、ライブラリ(pandas-datareader)を用いて株価を取得する手順も別の記事にまとめています。
[1] 取得する情報
[1-1] 株式投資メモから取得
株価は株式投資メモから取得させてもらいます。

株式投資メモでは、各銘柄の株価が過去数十年分にわたって閲覧することができます。CSVファイルでダウンロードすることも可能です。
[1-2] URL
URLはhttps://kabuoji3.com/stock/(証券コード)/(年)/になっています。JR東日本(証券コード=9020)の2020年の株価であればhttps://kabuoji3.com/stock/9020/2020/です。
[1-3] HTMLの構成
株価はtable要素に格納されています。tbody要素がありますが、1つ目以外はタグの開始側がなく機能していないので無視して構わないです。
<table class="stock_table stock_data_table"> <thead> <tr> <th>日付</th> <th>始値</th> <th>高値</th> <th>安値</th> <th>終値</th> <th>出来高</th> <th>終値調整</th> </tr> </thead> <tbody> <tr> <td>2020-01-06</td> <td>9785</td> <td>9816</td> <td>9670</td> <td>9676</td> <td>1179000</td> <td>9676</td> </tr> </tbody> <tr> <td>2020-01-07</td> <td>9727</td> <td>9801</td> <td>9701</td> <td>9774</td> <td>900000</td> <td>9774</td> </tr> </tbody> 〜〜〜(中略)〜〜〜 </table>
[2] 403 Forbiddenで上手くいかないので解決する
[2-1] ソースコードと事象
以下のソースコードを実行したところ「403 Forbidden」が返ってきてしまいました。アクセスが拒否されたということです。
code = 9020 year = 2020 # 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html = requests.get(url) print(html) # <Response [403]> print(html.content) # b'<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> # <html><head>\n<title>403 Forbidden</title> # </head><body>\n<h1>Forbidden</h1> # <p>You don\'t have permission to access this resource.</p> # </body></html>\n'
[2-2] 原因
非ブラウザのリクエストを禁止しているようです。スクレイピングを防ぐ意図で禁止しているのかと思いましたが、規約やrobots.txtを確認するとそうではないようです。
そこで今回は、ブラウザからのリクエストと認識されるようにしていきます。クライアントが何なのかは、HTTPヘッダの'User-Agent'に書かれます。なので、'User-Agent'の内容をブラウザからのリクエストに書き換えます。
なお、'User-Agent'については以下の記事に詳しい説明が書かれておりました。
UserAgentからOS/ブラウザなどの調べかたのまとめ - Qiita
[2-3] 解決法
確認くんにアクセスすると「現在のブラウザー」欄に使用しているブラウザの情報が表示されています。その内容をHTMLヘッダにセットします。
以下のソースではhtml_headersというディクショナリを用意し、keyを'User-Agent'にし、valueに確認くんで表示された内容をコピーしています。
# 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html_headers ={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} html = requests.get(url, headers=html_headers)
[3] スクレイピング
[3-1] ソースコード
JR東日本(証券コード=9020)の2016年〜2020年の株価を取得してみます。
code = 9020 # 証券コード start_year = 2016 # 開始年 end_year = 2020 # 終了年 df = None headers = None # 指定した年数分の株価を取得する years = range(start_year, end_year+1) for year in years: # 指定URLのHTMLデータを取得 url = 'https://kabuoji3.com/stock/{0:d}/{1:d}/'.format(code, year) html_headers ={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} html = requests.get(url, headers=html_headers) # BeautifulSoupのHTMLパーサーを生成 bs = BeautifulSoup(html.content, "html.parser") # <table>要素を取得 table = bs.find('table') # <table>要素内のヘッダ情報を取得する(初回のみ)。 # (日付, 始値, 高値, 安値, 終値, 出来高, 終値調整) if headers is None: headers = [] thead_th = table.find('thead').find_all('th') for th in thead_th: headers.append(th.text) # <tr>要素のデータを取得する。 rows = [] tr_all = table.find_all('tr') for i, tr in enumerate(tr_all): # 最初の行は<thead>要素なので飛ばす if i==0: continue # <tr>要素内の<td>要素を取得する。 row = [] td_all = tr.find_all('td') for td in td_all: row.append(td.text) # 1行のデータをリストに追加 rows.append(row) # DataFrameを生成する df_tmp = pd.DataFrame(rows, columns=headers) # DataFrameを結合する if df is None: df = df_tmp else: df = pd.concat([df, df_tmp]) # 1秒ディレイ time.sleep(1) print(df.head()) # 日付 始値 高値 安値 終値 出来高 終値調整 # 0 2016-01-04 11360 11410 11100 11125 748400 11125 # 1 2016-01-05 11100 11300 11035 11205 896700 11205 # 2 2016-01-06 11275 11400 11055 11135 699200 11135 # 3 2016-01-07 11255 11305 11040 11050 1095000 11050 # 4 2016-01-08 10950 11180 10855 10875 1100300 10875
[3-2] データ型を変換する
取得したデータの型を確認すると、すべて'object'型になっています。このままでは、グラフ表示や移動平均算出の際に都合が悪いです。
print(df.dtypes) # 日付 object # 始値 object # 高値 object # 安値 object # 終値 object # 出来高 object # 終値調整 object # dtype: object
日付はdatatime型、それ以外はfloat型に変換します。
# 列とデータ型の組み合わせを設定 dtypes = {} for column in df.columns: if column == '日付': dtypes[column] = 'datetime64' else: dtypes[column] = 'float64' # データ型を変換 df = df.astype(dtypes) # インデックスを日付に変更 df = df.set_index('日付')
[4] 可視化
[4-1] 終値をグラフ表示
まずは、終値を単純に折れ線グラフにしてみます。

# FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(1,1,1) # 終値の折れ線グラフを追加 x = df['日付'] y = df['終値'] ax.plot(x, y, label='終値', linewidth=2.0) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # グラフを表示 fig.show()
[4-2] 移動平均を算出
続いて、チャートでよくみる移動平均を算出します。
df['5日移動平均'] = df['終値'].rolling(window=5).mean() df['25日移動平均'] = df['終値'].rolling(window=25).mean() df['75日移動平均'] = df['終値'].rolling(window=75).mean()
[4-3] 移動平均をグラフ表示
移動平均をグラフ表示するにあたり、2020/01/01以降のデータに絞ります。
# 2020/01/01以降のデータを抽出 df = df['2020-01-01':]
グラフ表示してみると以下のようになりました。以下はJR東日本の株価です。コロナウィルスの影響もあり、長期で見ると株価は下がり続けています。
# FigureとAxesを取得 fig = plt.figure() ax = fig.add_subplot(1,1,1) # 終値の折れ線グラフを追加 x = df['日付'] y = df['終値'] ax.plot(x, y, label='終値', linewidth=2.0) # 移動平均の折れ線グラフを追加 average_columns = ['5日移動平均', '25日移動平均', '75日移動平均'] for column in average_columns: x = df['日付'] y = df[column] ax.plot(x, y, label=column, linewidth=1.0) # 目盛り線を表示 ax.grid(color='gray', linestyle='--', linewidth=0.5) # 凡例を表示 ax.legend() # グラフを表示 fig.show()
終わりに
株価をスクレイピングで取得してグラフ表示することができました。
しかし、単一銘柄の株価を見るだけであれば、色々なところで簡単に見れるので、自分でわざわざ作る価値はそれほどないでしょう。
次回は複数銘柄の比較と可視化を行い、作る価値のあるデータを作っていきます。
出典
- アイキャッチはGerd AltmannによるPixabayからの画像
【読書】最新書籍で紹介されていた世界注目の企業

<最新書籍で紹介されていた世界注目の企業>*1
2020年発売の書籍で紹介されていた世界注目の企業を紹介します。すでに世界で成功を収め今後も成長が見込める企業、今後急成長し市場破壊を起こすだろう企業が紹介されていました。
- サステナベーション sustainability × innovation ――多様性時代における企業の羅針盤
- フードテック革命 世界700兆円の新産業 「食」の進化と再定義
- アフターデジタル2 UXと自由
書籍で扱っていた全ての企業を紹介しているわけではありません。また、各企業については概要しか書いていません。詳細に興味がある方は、ぜひ書籍を購入するかご自分で調べてみてください。
中国
アリババ
最近、中国当局と揉めて話題になっているアリババです。知っている方も多いと思いますが、中国ECの超大手です。ECだけでなく様々な事業を持っているプラットフォーマーです。以下が主な事業です。
テンセント
メッセンジャーアプリ「WeChat」で有名な企業です。「WeChat」を基点として様々なサービスを提供しているプラットフォーマーなのはアリババと同じです。例えば、WeChatペイなどです。
アリババとの違いは、ゲーム事業で大きな収益を挙げていることです。テンセントミュージックという音楽サービスも展開しています。
NIO
電気自走車のメーカーで、中国で最も販売台数が多いのがNIOです。電気自動車自体よりも会員サービスが特徴的であり、NIO経済圏に顧客を引き込んでいます。会員サービスは、充電サービス、メンテナンス、ラウンジ・イベント、SNS・ECを提供しています。
電気自動車は充電に時間がかかりますが、電池パックそのものを交換するデリバリーサービスを提供しており、好評を得ています。また、ラウンジの提供やイベントの開催を、NIO専用のSNSで投稿してもらい、ポイントを貯めてグッズを買ってもらうことも行っています。
このように、NIOコミュニティでのコミュニケーションと購買を促し、ファンを獲得しています。
ZiRoom
若者向け賃貸サービスです。賃貸物件探し、生活サービス、旅行、コミュニティを提供しています。
生活サービスは管理費を上乗せすることで、定期的な清掃や家具の修理を提供しています。旅行は、中国国内で旅行する際にZiRoomの空き部屋に安価で宿泊できます。コミュニティでは、マンション内のイベントスペースを提供したり、近所のZiRoomユーザーのチャットグループを用意したりしています。
衆安保険
オンライン保険会社で、以下のような保険をOEMで提供しています。OEMなのでユーザー側に衆安保険の名前は出てこず、サービサーの名前で保険が販売されます。サービサーの保険を作りたいというニーズに応えるサービスです。
- 飛行機遅延保険
- 高温保険
- 糖尿病保険
- 返品運賃保険
イギリス
Digi.me
個人情報を一元管理するサービスを提供しています。SNSや財務管理サービス, スマートウォッチなどにより外部企業が保有している自分自身の個人データを、収集し一元管理できるようにしました。
これは個人情報管理に厳しい欧州、とくにイギリスならではのサービスと言えます。イギリスでは個人情報の活用を本人が選択できます。企業が保有している自身のデータにアクセスできるように政府主導で推進してきました。
エバーレッジャー
ダイヤモンドの産地や所有者の情報をブロックチェーンで電子台帳化するサービスを提供しています。電子化することで、産地の偽造や改ざん、詐欺を防げるようにしています。
ダイヤモンドの採掘は紛争地の貧困層によって行われるケースが増えていました。しかし、利益は貧困層と国に渡らず地元住民は貧乏なまま。産地は偽られ、紛争地のダイヤとは分からずに購入するのはよくあることでした。
東南アジア
Grab
ライドシェアサービス大手です。ライドシェアだけでなく「GrabPay」というキャッシュレス決済、デリバリーフードや食事のピックアップサービスも行っていますが、特に重要なのは金融サービスです。Grabで得たドライバーの情報から与信管理を行い、ドライバー向けの融資も行っています。
アメリカ
Casper
マットレス直販を行うD2Cブランドです。商品の購入はオンラインのみ、100日間返品可能、美しい包装といった特徴がありますが、特筆すべきは質の高いブランディングです。
睡眠は人間のウェルネスを決める重要な要素と位置付け、ウェルネスをテーマにした雑誌を自社で発行したりポッドキャストを展開したりして、ファンを獲得しました。
インポッシブルフーズ
動物肉を使わない代替肉である「植物性パティ」を製造しており、既に15,000点以上のレストランで採用されています。2020年3月時点で総額10億2,800万ドルの資金調達規模です。
近年問題化している、人口増加による肉の消費量増加、畜産の道義上の問題と環境問題、健康被害の解決作として代替肉は強く期待されています。
ビヨンドミート
インポッシブルフーズと同様に植物性パティを製造しています。2020年12月時点で時価総額は70億ドルを超えています。
イニット, サイドシェフ, シェフリング
キッチンOSの代表的なプレーヤーです。
キッチンOSは、スマート調理家電をコントロールするソフトウェアです。例えば、スマホアプリからレシピを選択すると、調理家電がレシピ通りに調理するといったことが可能になります。
キッチンOSにより、今まで得られなかったユーザー個別の食に関するデータが得られます。GAFAがデータを活用して巨大企業にまで成長したことは誰もが知っていますが、それと同じことが食でも起こるのかと注目されています。
日本
グローバルモビリティサービス
東南アジアの車社会に貢献している企業で、車載IoTデバイス「MCCS」が有名です。MCCSには加速度センサーやGPSが付いており、搭載した車がどこにいるか、どのような運転がされたかを24時間把握できます。
新興国では車を購入するのにローンが組めず購入できない場合が多かったです。しかし、MCCSを搭載した車であれば与信審査に通りやすくなります。例えば、タクシー運転手をしたい若者の与信審査をする場合に、MCCS搭載車であれば運転手が安全に運転しているかを把握できます。もし、ローンの返済が滞ったり危険な運転を行ってれば、遠隔で車を動かせなくすることも可能です。
南アフリカ
ルムカニ
スラム向け火災報知器を開発・販売しています。スラムは木や段ボールなど燃えやすい資材で作られており、火災が発生すると瞬く間に燃え広がるという問題がありました。
ルムカニの火災報知器は安価に簡単に取り付けができます。また、火災報知器から住民の生活情報を収集し信用調査が行えるようになったことで、スラムの住民が火災保険に加入できるようになりました。
*1:Gerd AltmannによるPixabayからの画像
*2:正確にはアリババではなく、アリババ関連企業のアントフィナンシャルが運営しています